 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Auto-Bidding in Large-Scale Competitive Auctions via Diffusion Completer-Aligner
Sep 03, 2025Auto-bidding is central to computational advertising, achieving notable commercial success by optimizing advertisers' bids within economic constraints. Recently, large generative models show potential to revolutionize auto-bidding by generating bids that could flexibly adapt to complex, competitive environments. Among them, diffusers stand out for their ability to address sparse-reward challenges by focusing on trajectory-level accumulated rewards, as well as their explainable capability, i.e., planning a future trajectory of states and executing bids accordingly. However, diffusers struggle with generation uncertainty, particularly regarding dynamic legitimacy between adjacent states, which can lead to poor bids and further cause significant loss of ad impression opportunities when competing with other advertisers in a highly competitive auction environment. To address it, we propose a Causal auto-Bidding method based on a Diffusion completer-aligner framework, termed CBD. Firstly, we augment the diffusion training process with an extra random variable t, where the model observes t-length historical sequences with the goal of completing the remaining sequence, thereby enhancing the generated sequences' dynamic legitimacy. Then, we employ a trajectory-level return model to refine the generated trajectories, aligning more closely with advertisers' objectives. Experimental results across diverse settings demonstrate that our approach not only achieves superior performance on large-scale auto-bidding benchmarks, such as a 29.9% improvement in conversion value in the challenging sparse-reward auction setting, but also delivers significant improvements on the Kuaishou online advertising platform, including a 2.0% increase in target cost.
Resultant: Incremental Effectiveness on Likelihood for Unsupervised Out-of-Distribution Detection
Sep 05, 2024



Unsupervised out-of-distribution (U-OOD) detection is to identify OOD data samples with a detector trained solely on unlabeled in-distribution (ID) data. The likelihood function estimated by a deep generative model (DGM) could be a natural detector, but its performance is limited in some popular "hard" benchmarks, such as FashionMNIST (ID) vs. MNIST (OOD). Recent studies have developed various detectors based on DGMs to move beyond likelihood. However, despite their success on "hard" benchmarks, most of them struggle to consistently surpass or match the performance of likelihood on some "non-hard" cases, such as SVHN (ID) vs. CIFAR10 (OOD) where likelihood could be a nearly perfect detector. Therefore, we appeal for more attention to incremental effectiveness on likelihood, i.e., whether a method could always surpass or at least match the performance of likelihood in U-OOD detection. We first investigate the likelihood of variational DGMs and find its detection performance could be improved in two directions: i) alleviating latent distribution mismatch, and ii) calibrating the dataset entropy-mutual integration. Then, we apply two techniques for each direction, specifically post-hoc prior and dataset entropy-mutual calibration. The final method, named Resultant, combines these two directions for better incremental effectiveness compared to either technique alone. Experimental results demonstrate that the Resultant could be a new state-of-the-art U-OOD detector while maintaining incremental effectiveness on likelihood in a wide range of tasks.
Continuous Emotion Recognition using Visual-audio-linguistic information: A Technical Report for ABAW3
Mar 30, 2022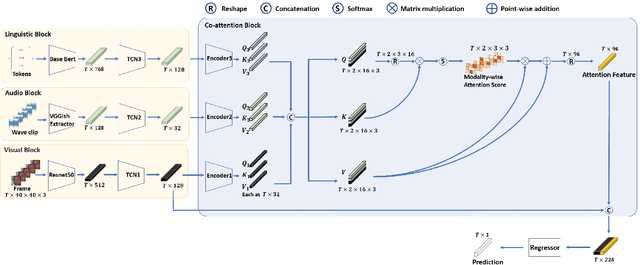
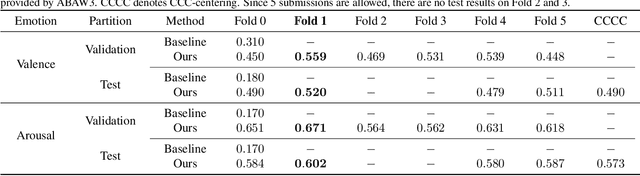
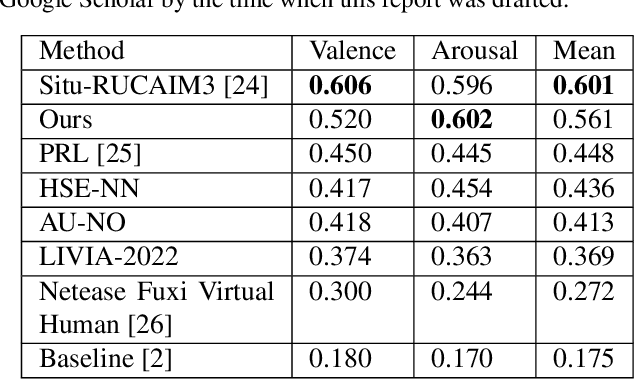
We propose a cross-modal co-attention model for continuous emotion recognition using visual-audio-linguistic information. The model consists of four blocks. The visual, audio, and linguistic blocks are used to learn the spatial-temporal features of the multi-modal input. A co-attention block is designed to fuse the learned features with the multi-head co-attention mechanism. The visual encoding from the visual block is concatenated with the attention feature to emphasize the visual information. To make full use of the data and alleviate over-fitting, cross-validation is carried out on the training and validation set. The concordance correlation coefficient (CCC) centering is used to merge the results from each fold. The achieved CCC on the test set is $0.520$ for valence and $0.602$ for arousal, which significantly outperforms the baseline method with the corresponding CCC of 0.180 and 0.170 for valence and arousal, respectively. The code is available at https://github.com/sucv/ABAW3.