 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLBM: Hierarchical Large Auto-Bidding Model via Reasoning and Acting
Mar 05, 2026The growing scale of ad auctions on online advertising platforms has intensified competition, making manual bidding impractical and necessitating auto-bidding to help advertisers achieve their economic goals. Current auto-bidding methods have evolved to use offline reinforcement learning or generative methods to optimize bidding strategies, but they can sometimes behave counterintuitively due to the black-box training manner and limited mode coverage of datasets, leading to challenges in understanding task status and generalization in dynamic ad environments. Large language models (LLMs) offer a promising solution by leveraging prior human knowledge and reasoning abilities to improve auto-bidding performance. However, directly applying LLMs to auto-bidding faces difficulties due to the need for precise actions in competitive auctions and the lack of specialized auto-bidding knowledge, which can lead to hallucinations and suboptimal decisions. To address these challenges, we propose a hierarchical Large autoBidding Model (LBM) to leverage the reasoning capabilities of LLMs for developing a superior auto-bidding strategy. This includes a high-level LBM-Think model for reasoning and a low-level LBM-Act model for action generation. Specifically, we propose a dual embedding mechanism to efficiently fuse two modalities, including language and numerical inputs, for language-guided training of the LBM-Act; then, we propose an offline reinforcement fine-tuning technique termed GQPO for mitigating the LLM-Think's hallucinations and enhancing decision-making performance without simulation or real-world rollout like previous multi-turn LLM-based methods. Experiments demonstrate the superiority of a generative backbone based on our LBM, especially in an efficient training manner and generalization ability.
Phase-Aware Mixture of Experts for Agentic Reinforcement Learning
Feb 19, 2026Reinforcement learning (RL) has equipped LLM agents with a strong ability to solve complex tasks. However, existing RL methods normally use a \emph{single} policy network, causing \emph{simplicity bias} where simple tasks occupy most parameters and dominate gradient updates, leaving insufficient capacity for complex tasks. A plausible remedy could be employing the Mixture-of-Experts (MoE) architecture in the policy network, as MoE allows different parameters (experts) to specialize in different tasks, preventing simple tasks from dominating all parameters. However, a key limitation of traditional MoE is its token-level routing, where the router assigns each token to specialized experts, which fragments phase-consistent patterns into scattered expert assignments and thus undermines expert specialization. In this paper, we propose \textbf{Phase-Aware Mixture of Experts (PA-MoE)}. It first features a lightweight \emph{phase router} that learns latent phase boundaries directly from the RL objective without pre-defining phase categories. Then, the phase router allocates temporally consistent assignments to the same expert, allowing experts to preserve phase-specific expertise. Experimental results demonstrate the effectiveness of our proposed PA-MoE.
FineFT: Efficient and Risk-Aware Ensemble Reinforcement Learning for Futures Trading
Dec 29, 2025Futures are contracts obligating the exchange of an asset at a predetermined date and price, notable for their high leverage and liquidity and, therefore, thrive in the Crypto market. RL has been widely applied in various quantitative tasks. However, most methods focus on the spot and could not be directly applied to the futures market with high leverage because of 2 challenges. First, high leverage amplifies reward fluctuations, making training stochastic and difficult to converge. Second, prior works lacked self-awareness of capability boundaries, exposing them to the risk of significant loss when encountering new market state (e.g.,a black swan event like COVID-19). To tackle these challenges, we propose the Efficient and Risk-Aware Ensemble Reinforcement Learning for Futures Trading (FineFT), a novel three-stage ensemble RL framework with stable training and proper risk management. In stage I, ensemble Q learners are selectively updated by ensemble TD errors to improve convergence. In stage II, we filter the Q-learners based on their profitabilities and train VAEs on market states to identify the capability boundaries of the learners. In stage III, we choose from the filtered ensemble and a conservative policy, guided by trained VAEs, to maintain profitability and mitigate risk with new market states. Through extensive experiments on crypto futures in a high-frequency trading environment with high fidelity and 5x leverage, we demonstrate that FineFT outperforms 12 SOTA baselines in 6 financial metrics, reducing risk by more than 40% while achieving superior profitability compared to the runner-up. Visualization of the selective update mechanism shows that different agents specialize in distinct market dynamics, and ablation studies certify routing with VAEs reduces maximum drawdown effectively, and selective update improves convergence and performance.
Generative Auto-Bidding in Large-Scale Competitive Auctions via Diffusion Completer-Aligner
Sep 03, 2025Auto-bidding is central to computational advertising, achieving notable commercial success by optimizing advertisers' bids within economic constraints. Recently, large generative models show potential to revolutionize auto-bidding by generating bids that could flexibly adapt to complex, competitive environments. Among them, diffusers stand out for their ability to address sparse-reward challenges by focusing on trajectory-level accumulated rewards, as well as their explainable capability, i.e., planning a future trajectory of states and executing bids accordingly. However, diffusers struggle with generation uncertainty, particularly regarding dynamic legitimacy between adjacent states, which can lead to poor bids and further cause significant loss of ad impression opportunities when competing with other advertisers in a highly competitive auction environment. To address it, we propose a Causal auto-Bidding method based on a Diffusion completer-aligner framework, termed CBD. Firstly, we augment the diffusion training process with an extra random variable t, where the model observes t-length historical sequences with the goal of completing the remaining sequence, thereby enhancing the generated sequences' dynamic legitimacy. Then, we employ a trajectory-level return model to refine the generated trajectories, aligning more closely with advertisers' objectives. Experimental results across diverse settings demonstrate that our approach not only achieves superior performance on large-scale auto-bidding benchmarks, such as a 29.9% improvement in conversion value in the challenging sparse-reward auction setting, but also delivers significant improvements on the Kuaishou online advertising platform, including a 2.0% increase in target cost.
Generative Auto-Bidding with Value-Guided Explorations
Apr 20, 2025Auto-bidding, with its strong capability to optimize bidding decisions within dynamic and competitive online environments, has become a pivotal strategy for advertising platforms. Existing approaches typically employ rule-based strategies or Reinforcement Learning (RL) techniques. However, rule-based strategies lack the flexibility to adapt to time-varying market conditions, and RL-based methods struggle to capture essential historical dependencies and observations within Markov Decision Process (MDP) frameworks. Furthermore, these approaches often face challenges in ensuring strategy adaptability across diverse advertising objectives. Additionally, as offline training methods are increasingly adopted to facilitate the deployment and maintenance of stable online strategies, the issues of documented behavioral patterns and behavioral collapse resulting from training on fixed offline datasets become increasingly significant. To address these limitations, this paper introduces a novel offline Generative Auto-bidding framework with Value-Guided Explorations (GAVE). GAVE accommodates various advertising objectives through a score-based Return-To-Go (RTG) module. Moreover, GAVE integrates an action exploration mechanism with an RTG-based evaluation method to explore novel actions while ensuring stability-preserving updates. A learnable value function is also designed to guide the direction of action exploration and mitigate Out-of-Distribution (OOD) problems. Experimental results on two offline datasets and real-world deployments demonstrate that GAVE outperforms state-of-the-art baselines in both offline evaluations and online A/B tests. The implementation code is publicly available to facilitate reproducibility and further research.
GAS: Generative Auto-bidding with Post-training Search
Dec 22, 2024



Auto-bidding is essential in facilitating online advertising by automatically placing bids on behalf of advertisers. Generative auto-bidding, which generates bids based on an adjustable condition using models like transformers and diffusers, has recently emerged as a new trend due to its potential to learn optimal strategies directly from data and adjust flexibly to preferences. However, generative models suffer from low-quality data leading to a mismatch between condition, return to go, and true action value, especially in long sequential decision-making. Besides, the majority preference in the dataset may hinder models' generalization ability on minority advertisers' preferences. While it is possible to collect high-quality data and retrain multiple models for different preferences, the high cost makes it unaffordable, hindering the advancement of auto-bidding into the era of large foundation models. To address this, we propose a flexible and practical Generative Auto-bidding scheme using post-training Search, termed GAS, to refine a base policy model's output and adapt to various preferences. We use weak-to-strong search alignment by training small critics for different preferences and an MCTS-inspired search to refine the model's output. Specifically, a novel voting mechanism with transformer-based critics trained with policy indications could enhance search alignment performance. Additionally, utilizing the search, we provide a fine-tuning method for high-frequency preference scenarios considering computational efficiency. Extensive experiments conducted on the real-world dataset and online A/B test on the Kuaishou advertising platform demonstrate the effectiveness of GAS, achieving significant improvements, e.g., 1.554% increment of target cost.
Resultant: Incremental Effectiveness on Likelihood for Unsupervised Out-of-Distribution Detection
Sep 05, 2024



Unsupervised out-of-distribution (U-OOD) detection is to identify OOD data samples with a detector trained solely on unlabeled in-distribution (ID) data. The likelihood function estimated by a deep generative model (DGM) could be a natural detector, but its performance is limited in some popular "hard" benchmarks, such as FashionMNIST (ID) vs. MNIST (OOD). Recent studies have developed various detectors based on DGMs to move beyond likelihood. However, despite their success on "hard" benchmarks, most of them struggle to consistently surpass or match the performance of likelihood on some "non-hard" cases, such as SVHN (ID) vs. CIFAR10 (OOD) where likelihood could be a nearly perfect detector. Therefore, we appeal for more attention to incremental effectiveness on likelihood, i.e., whether a method could always surpass or at least match the performance of likelihood in U-OOD detection. We first investigate the likelihood of variational DGMs and find its detection performance could be improved in two directions: i) alleviating latent distribution mismatch, and ii) calibrating the dataset entropy-mutual integration. Then, we apply two techniques for each direction, specifically post-hoc prior and dataset entropy-mutual calibration. The final method, named Resultant, combines these two directions for better incremental effectiveness compared to either technique alone. Experimental results demonstrate that the Resultant could be a new state-of-the-art U-OOD detector while maintaining incremental effectiveness on likelihood in a wide range of tasks.
HumanMAC: Masked Motion Completion for Human Motion Prediction
Feb 07, 2023Human motion prediction is a classical problem in computer vision and computer graphics, which has a wide range of practical applications. Previous effects achieve great empirical performance based on an encoding-decoding fashion. The methods of this fashion work by first encoding previous motions to latent representations and then decoding the latent representations into predicted motions. However, in practice, they are still unsatisfactory due to several issues, including complicated loss constraints, cumbersome training processes, and scarce switch of different categories of motions in prediction. In this paper, to address the above issues, we jump out of the foregoing fashion and propose a novel framework from a new perspective. Specifically, our framework works in a denoising diffusion style. In the training stage, we learn a motion diffusion model that generates motions from random noise. In the inference stage, with a denoising procedure, we make motion prediction conditioning on observed motions to output more continuous and controllable predictions. The proposed framework enjoys promising algorithmic properties, which only needs one loss in optimization and is trained in an end-to-end manner. Additionally, it accomplishes the switch of different categories of motions effectively, which is significant in realistic tasks, \textit{e.g.}, the animation task. Comprehensive experiments on benchmarks confirm the superiority of the proposed framework. The project page is available at \url{https://lhchen.top/Human-MAC}.
Pluralistic Image Completion with Probabilistic Mixture-of-Experts
May 18, 2022


Pluralistic image completion focuses on generating both visually realistic and diverse results for image completion. Prior methods enjoy the empirical successes of this task. However, their used constraints for pluralistic image completion are argued to be not well interpretable and unsatisfactory from two aspects. First, the constraints for visual reality can be weakly correlated to the objective of image completion or even redundant. Second, the constraints for diversity are designed to be task-agnostic, which causes the constraints to not work well. In this paper, to address the issues, we propose an end-to-end probabilistic method. Specifically, we introduce a unified probabilistic graph model that represents the complex interactions in image completion. The entire procedure of image completion is then mathematically divided into several sub-procedures, which helps efficient enforcement of constraints. The sub-procedure directly related to pluralistic results is identified, where the interaction is established by a Gaussian mixture model (GMM). The inherent parameters of GMM are task-related, which are optimized adaptively during training, while the number of its primitives can control the diversity of results conveniently. We formally establish the effectiveness of our method and demonstrate it with comprehensive experiments.
Sawtooth Factorial Topic Embeddings Guided Gamma Belief Network
Jun 30, 2021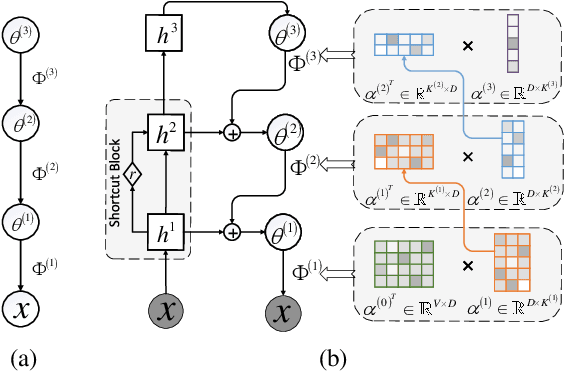
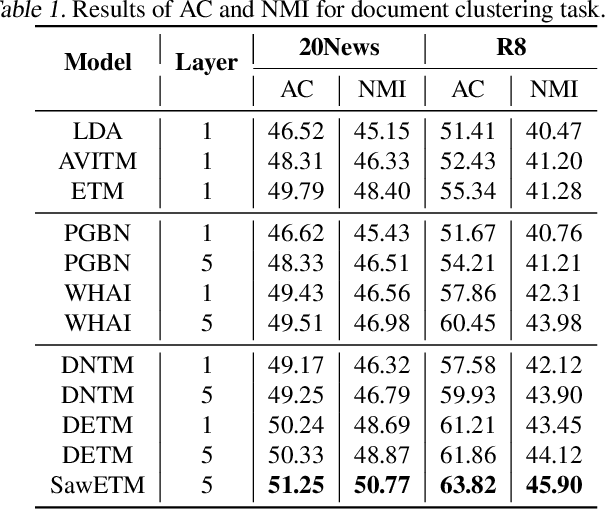
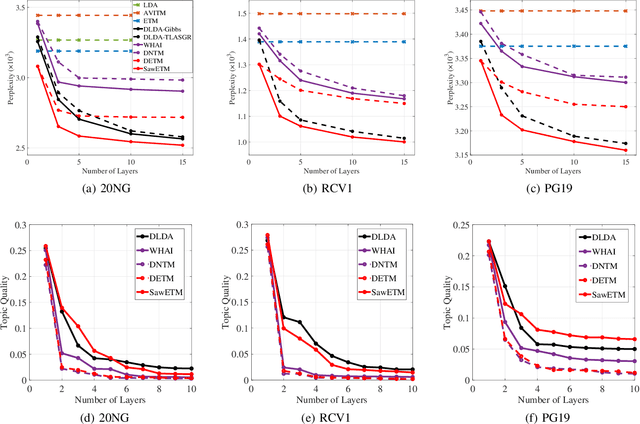
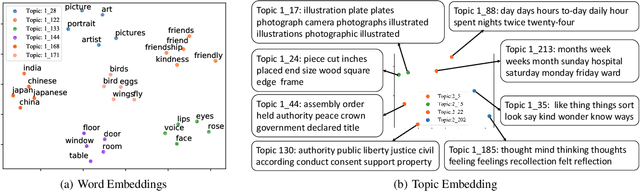
Hierarchical topic models such as the gamma belief network (GBN) have delivered promising results in mining multi-layer document representations and discovering interpretable topic taxonomies. However, they often assume in the prior that the topics at each layer are independently drawn from the Dirichlet distribution, ignoring the dependencies between the topics both at the same layer and across different layers. To relax this assumption, we propose sawtooth factorial topic embedding guided GBN, a deep generative model of documents that captures the dependencies and semantic similarities between the topics in the embedding space. Specifically, both the words and topics are represented as embedding vectors of the same dimension. The topic matrix at a layer is factorized into the product of a factor loading matrix and a topic embedding matrix, the transpose of which is set as the factor loading matrix of the layer above. Repeating this particular type of factorization, which shares components between adjacent layers, leads to a structure referred to as sawtooth factorization. An auto-encoding variational inference network is constructed to optimize the model parameter via stochastic gradient descent. Experiments on big corpora show that our models outperform other neural topic models on extracting deeper interpretable topics and deriving better document representations.