 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Mixture-of-Experts for Efficient Deep Reinforcement Learning
Paper and Code
Apr 19, 2021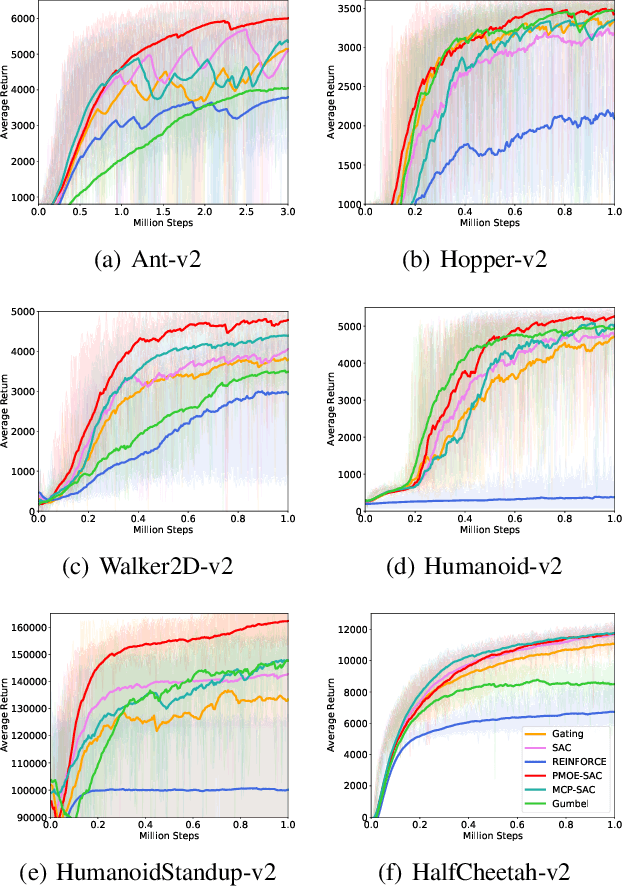
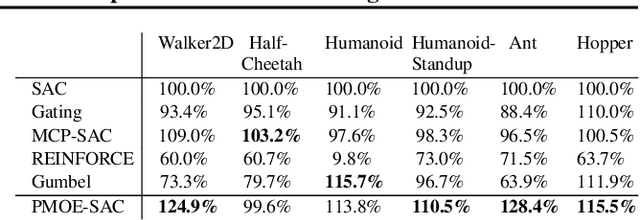
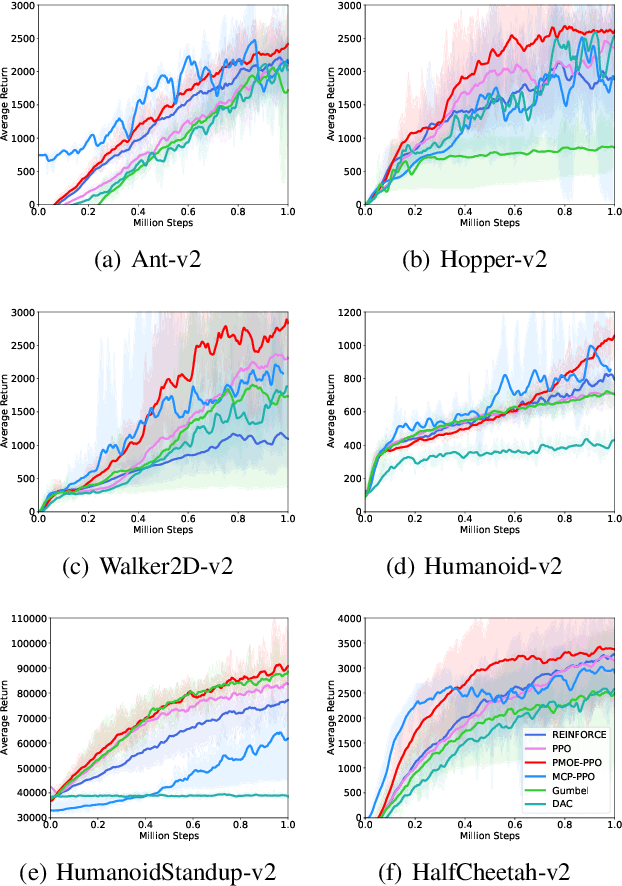
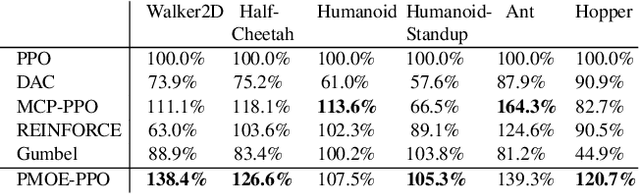
Deep reinforcement learning (DRL) has successfully solved various problems recently, typically with a unimodal policy representation. However, grasping distinguishable skills for some tasks with non-unique optima can be essential for further improving its learning efficiency and performance, which may lead to a multimodal policy represented as a mixture-of-experts (MOE). To our best knowledge, present DRL algorithms for general utility do not deploy this method as policy function approximators due to the potential challenge in its differentiability for policy learning. In this work, we propose a probabilistic mixture-of-experts (PMOE) implemented with a Gaussian mixture model (GMM) for multimodal policy, together with a novel gradient estimator for the indifferentiability problem, which can be applied in generic off-policy and on-policy DRL algorithms using stochastic policies, e.g., Soft Actor-Critic (SAC) and Proximal Policy Optimisation (PPO). Experimental results testify the advantage of our method over unimodal polices and two different MOE methods, as well as a method of option frameworks, based on the above two types of DRL algorithms, on six MuJoCo tasks. Different gradient estimations for GMM like the reparameterisation trick (Gumbel-Softmax) and the score-ratio trick are also compared with our method. We further empirically demonstrate the distinguishable primitives learned with PMOE and show the benefits of our method in terms of exploration.