 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Emotion Recognition using Visual-audio-linguistic information: A Technical Report for ABAW3
Paper and Code
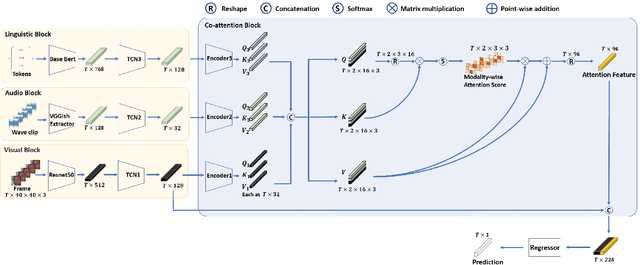
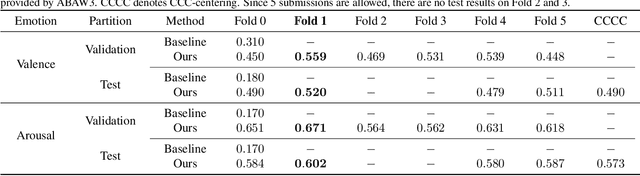
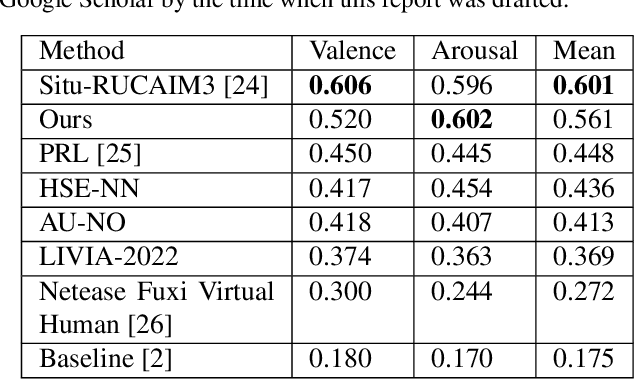
We propose a cross-modal co-attention model for continuous emotion recognition using visual-audio-linguistic information. The model consists of four blocks. The visual, audio, and linguistic blocks are used to learn the spatial-temporal features of the multi-modal input. A co-attention block is designed to fuse the learned features with the multi-head co-attention mechanism. The visual encoding from the visual block is concatenated with the attention feature to emphasize the visual information. To make full use of the data and alleviate over-fitting, cross-validation is carried out on the training and validation set. The concordance correlation coefficient (CCC) centering is used to merge the results from each fold. The achieved CCC on the test set is $0.520$ for valence and $0.602$ for arousal, which significantly outperforms the baseline method with the corresponding CCC of 0.180 and 0.170 for valence and arousal, respectively. The code is available at https://github.com/sucv/ABAW3.