 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Additive Kolmogorov-Arnold Transformer for Point-Level Maize Localization in Unmanned Aerial Vehicle Imagery
Jan 12, 2026High-resolution UAV photogrammetry has become a key technology for precision agriculture, enabling centimeter-level crop monitoring and point-level plant localization. However, point-level maize localization in UAV imagery remains challenging due to (1) extremely small object-to-pixel ratios, typically less than 0.1%, (2) prohibitive computational costs of quadratic attention on ultra-high-resolution images larger than 3000 x 4000 pixels, and (3) agricultural scene-specific complexities such as sparse object distribution and environmental variability that are poorly handled by general-purpose vision models. To address these challenges, we propose the Additive Kolmogorov-Arnold Transformer (AKT), which replaces conventional multilayer perceptrons with Pade Kolmogorov-Arnold Network (PKAN) modules to enhance functional expressivity for small-object feature extraction, and introduces PKAN Additive Attention (PAA) to model multiscale spatial dependencies with reduced computational complexity. In addition, we present the Point-based Maize Localization (PML) dataset, consisting of 1,928 high-resolution UAV images with approximately 501,000 point annotations collected under real field conditions. Extensive experiments show that AKT achieves an average F1-score of 62.8%, outperforming state-of-the-art methods by 4.2%, while reducing FLOPs by 12.6% and improving inference throughput by 20.7%. For downstream tasks, AKT attains a mean absolute error of 7.1 in stand counting and a root mean square error of 1.95-1.97 cm in interplant spacing estimation. These results demonstrate that integrating Kolmogorov-Arnold representation theory with efficient attention mechanisms offers an effective framework for high-resolution agricultural remote sensing.
AutoPP: Towards Automated Product Poster Generation and Optimization
Dec 26, 2025Product posters blend striking visuals with informative text to highlight the product and capture customer attention. However, crafting appealing posters and manually optimizing them based on online performance is laborious and resource-consuming. To address this, we introduce AutoPP, an automated pipeline for product poster generation and optimization that eliminates the need for human intervention. Specifically, the generator, relying solely on basic product information, first uses a unified design module to integrate the three key elements of a poster (background, text, and layout) into a cohesive output. Then, an element rendering module encodes these elements into condition tokens, efficiently and controllably generating the product poster. Based on the generated poster, the optimizer enhances its Click-Through Rate (CTR) by leveraging online feedback. It systematically replaces elements to gather fine-grained CTR comparisons and utilizes Isolated Direct Preference Optimization (IDPO) to attribute CTR gains to isolated elements. Our work is supported by AutoPP1M, the largest dataset specifically designed for product poster generation and optimization, which contains one million high-quality posters and feedback collected from over one million users. Experiments demonstrate that AutoPP achieves state-of-the-art results in both offline and online settings. Our code and dataset are publicly available at: https://github.com/JD-GenX/AutoPP
Loss Functions for Predictor-based Neural Architecture Search
Jun 06, 2025Evaluation is a critical but costly procedure in neural architecture search (NAS). Performance predictors have been widely adopted to reduce evaluation costs by directly estimating architecture performance. The effectiveness of predictors is heavily influenced by the choice of loss functions. While traditional predictors employ regression loss functions to evaluate the absolute accuracy of architectures, recent approaches have explored various ranking-based loss functions, such as pairwise and listwise ranking losses, to focus on the ranking of architecture performance. Despite their success in NAS, the effectiveness and characteristics of these loss functions have not been thoroughly investigated. In this paper, we conduct the first comprehensive study on loss functions in performance predictors, categorizing them into three main types: regression, ranking, and weighted loss functions. Specifically, we assess eight loss functions using a range of NAS-relevant metrics on 13 tasks across five search spaces. Our results reveal that specific categories of loss functions can be effectively combined to enhance predictor-based NAS. Furthermore, our findings could provide practical guidance for selecting appropriate loss functions for various tasks. We hope this work provides meaningful insights to guide the development of loss functions for predictor-based methods in the NAS community.
Runtime Analysis of Evolutionary NAS for Multiclass Classification
Jun 06, 2025Evolutionary neural architecture search (ENAS) is a key part of evolutionary machine learning, which commonly utilizes evolutionary algorithms (EAs) to automatically design high-performing deep neural architectures. During past years, various ENAS methods have been proposed with exceptional performance. However, the theory research of ENAS is still in the infant. In this work, we step for the runtime analysis, which is an essential theory aspect of EAs, of ENAS upon multiclass classification problems. Specifically, we first propose a benchmark to lay the groundwork for the analysis. Furthermore, we design a two-level search space, making it suitable for multiclass classification problems and consistent with the common settings of ENAS. Based on both designs, we consider (1+1)-ENAS algorithms with one-bit and bit-wise mutations, and analyze their upper and lower bounds on the expected runtime. We prove that the algorithm using both mutations can find the optimum with the expected runtime upper bound of $O(rM\ln{rM})$ and lower bound of $\Omega(rM\ln{M})$. This suggests that a simple one-bit mutation may be greatly considered, given that most state-of-the-art ENAS methods are laboriously designed with the bit-wise mutation. Empirical studies also support our theoretical proof.
CARL: Causality-guided Architecture Representation Learning for an Interpretable Performance Predictor
Jun 04, 2025Performance predictors have emerged as a promising method to accelerate the evaluation stage of neural architecture search (NAS). These predictors estimate the performance of unseen architectures by learning from the correlation between a small set of trained architectures and their performance. However, most existing predictors ignore the inherent distribution shift between limited training samples and diverse test samples. Hence, they tend to learn spurious correlations as shortcuts to predictions, leading to poor generalization. To address this, we propose a Causality-guided Architecture Representation Learning (CARL) method aiming to separate critical (causal) and redundant (non-causal) features of architectures for generalizable architecture performance prediction. Specifically, we employ a substructure extractor to split the input architecture into critical and redundant substructures in the latent space. Then, we generate multiple interventional samples by pairing critical representations with diverse redundant representations to prioritize critical features. Extensive experiments on five NAS search spaces demonstrate the state-of-the-art accuracy and superior interpretability of CARL. For instance, CARL achieves 97.67% top-1 accuracy on CIFAR-10 using DARTS.
SaENeRF: Suppressing Artifacts in Event-based Neural Radiance Fields
Apr 23, 2025Event cameras are neuromorphic vision sensors that asynchronously capture changes in logarithmic brightness changes, offering significant advantages such as low latency, low power consumption, low bandwidth, and high dynamic range. While these characteristics make them ideal for high-speed scenarios, reconstructing geometrically consistent and photometrically accurate 3D representations from event data remains fundamentally challenging. Current event-based Neural Radiance Fields (NeRF) methods partially address these challenges but suffer from persistent artifacts caused by aggressive network learning in early stages and the inherent noise of event cameras. To overcome these limitations, we present SaENeRF, a novel self-supervised framework that effectively suppresses artifacts and enables 3D-consistent, dense, and photorealistic NeRF reconstruction of static scenes solely from event streams. Our approach normalizes predicted radiance variations based on accumulated event polarities, facilitating progressive and rapid learning for scene representation construction. Additionally, we introduce regularization losses specifically designed to suppress artifacts in regions where photometric changes fall below the event threshold and simultaneously enhance the light intensity difference of non-zero events, thereby improving the visual fidelity of the reconstructed scene. Extensive qualitative and quantitative experiments demonstrate that our method significantly reduces artifacts and achieves superior reconstruction quality compared to existing methods. The code is available at https://github.com/Mr-firework/SaENeRF.
EBAD-Gaussian: Event-driven Bundle Adjusted Deblur Gaussian Splatting
Apr 14, 2025While 3D Gaussian Splatting (3D-GS) achieves photorealistic novel view synthesis, its performance degrades with motion blur. In scenarios with rapid motion or low-light conditions, existing RGB-based deblurring methods struggle to model camera pose and radiance changes during exposure, reducing reconstruction accuracy. Event cameras, capturing continuous brightness changes during exposure, can effectively assist in modeling motion blur and improving reconstruction quality. Therefore, we propose Event-driven Bundle Adjusted Deblur Gaussian Splatting (EBAD-Gaussian), which reconstructs sharp 3D Gaussians from event streams and severely blurred images. This method jointly learns the parameters of these Gaussians while recovering camera motion trajectories during exposure time. Specifically, we first construct a blur loss function by synthesizing multiple latent sharp images during the exposure time, minimizing the difference between real and synthesized blurred images. Then we use event stream to supervise the light intensity changes between latent sharp images at any time within the exposure period, supplementing the light intensity dynamic changes lost in RGB images. Furthermore, we optimize the latent sharp images at intermediate exposure times based on the event-based double integral (EDI) prior, applying consistency constraints to enhance the details and texture information of the reconstructed images. Extensive experiments on synthetic and real-world datasets show that EBAD-Gaussian can achieve high-quality 3D scene reconstruction under the condition of blurred images and event stream inputs.
Position: Continual Learning Benefits from An Evolving Population over An Unified Model
Feb 10, 2025



Deep neural networks have demonstrated remarkable success in machine learning; however, they remain fundamentally ill-suited for Continual Learning (CL). Recent research has increasingly focused on achieving CL without the need for rehearsal. Among these, parameter isolation-based methods have proven particularly effective in enhancing CL by optimizing model weights for each incremental task. Despite their success, they fall short in optimizing architectures tailored to distinct incremental tasks. To address this limitation, updating a group of models with different architectures offers a promising alternative to the traditional CL paradigm that relies on a single unified model. Building on this insight, this study introduces a novel Population-based Continual Learning (PCL) framework. PCL extends CL to the architectural level by maintaining and evolving a population of neural network architectures, which are continually refined for the current task through NAS. Importantly, the well-evolved population for the current incremental task is naturally inherited by the subsequent one, thereby facilitating forward transfer, a crucial objective in CL. Throughout the CL process, the population evolves, yielding task-specific architectures that collectively form a robust CL system. Experimental results demonstrate that PCL outperforms state-of-the-art rehearsal-free CL methods that employs a unified model, highlighting its potential as a new paradigm for CL.
Uni-EDEN: Universal Encoder-Decoder Network by Multi-Granular Vision-Language Pre-training
Jan 11, 2022
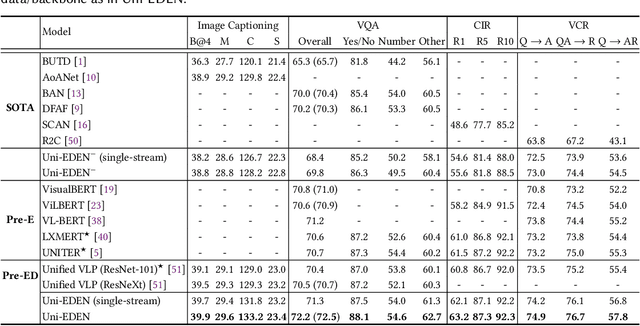

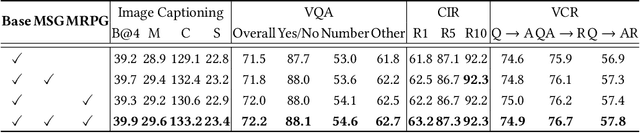
Vision-language pre-training has been an emerging and fast-developing research topic, which transfers multi-modal knowledge from rich-resource pre-training task to limited-resource downstream tasks. Unlike existing works that predominantly learn a single generic encoder, we present a pre-trainable Universal Encoder-DEcoder Network (Uni-EDEN) to facilitate both vision-language perception (e.g., visual question answering) and generation (e.g., image captioning). Uni-EDEN is a two-stream Transformer based structure, consisting of three modules: object and sentence encoders that separately learns the representations of each modality, and sentence decoder that enables both multi-modal reasoning and sentence generation via inter-modal interaction. Considering that the linguistic representations of each image can span different granularities in this hierarchy including, from simple to comprehensive, individual label, a phrase, and a natural sentence, we pre-train Uni-EDEN through multi-granular vision-language proxy tasks: Masked Object Classification (MOC), Masked Region Phrase Generation (MRPG), Image-Sentence Matching (ISM), and Masked Sentence Generation (MSG). In this way, Uni-EDEN is endowed with the power of both multi-modal representation extraction and language modeling. Extensive experiments demonstrate the compelling generalizability of Uni-EDEN by fine-tuning it to four vision-language perception and generation downstream tasks.