 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFGM-HD: Boosting Generation Diversity of Fractal Generative Models through Hausdorff Dimension Induction
Nov 18, 2025Improving the diversity of generated results while maintaining high visual quality remains a significant challenge in image generation tasks. Fractal Generative Models (FGMs) are efficient in generating high-quality images, but their inherent self-similarity limits the diversity of output images. To address this issue, we propose a novel approach based on the Hausdorff Dimension (HD), a widely recognized concept in fractal geometry used to quantify structural complexity, which aids in enhancing the diversity of generated outputs. To incorporate HD into FGM, we propose a learnable HD estimation method that predicts HD directly from image embeddings, addressing computational cost concerns. However, simply introducing HD into a hybrid loss is insufficient to enhance diversity in FGMs due to: 1) degradation of image quality, and 2) limited improvement in generation diversity. To this end, during training, we adopt an HD-based loss with a monotonic momentum-driven scheduling strategy to progressively optimize the hyperparameters, obtaining optimal diversity without sacrificing visual quality. Moreover, during inference, we employ HD-guided rejection sampling to select geometrically richer outputs. Extensive experiments on the ImageNet dataset demonstrate that our FGM-HD framework yields a 39\% improvement in output diversity compared to vanilla FGMs, while preserving comparable image quality. To our knowledge, this is the very first work introducing HD into FGM. Our method effectively enhances the diversity of generated outputs while offering a principled theoretical contribution to FGM development.
Enhancing Diffusion Model Stability for Image Restoration via Gradient Management
Jul 09, 2025

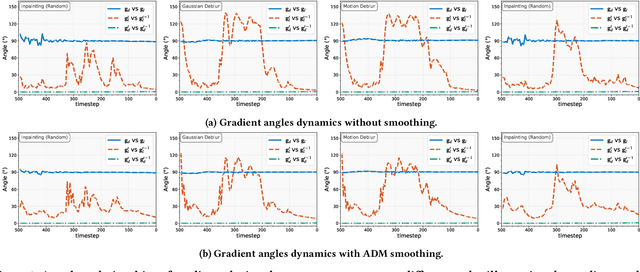

Diffusion models have shown remarkable promise for image restoration by leveraging powerful priors. Prominent methods typically frame the restoration problem within a Bayesian inference framework, which iteratively combines a denoising step with a likelihood guidance step. However, the interactions between these two components in the generation process remain underexplored. In this paper, we analyze the underlying gradient dynamics of these components and identify significant instabilities. Specifically, we demonstrate conflicts between the prior and likelihood gradient directions, alongside temporal fluctuations in the likelihood gradient itself. We show that these instabilities disrupt the generative process and compromise restoration performance. To address these issues, we propose Stabilized Progressive Gradient Diffusion (SPGD), a novel gradient management technique. SPGD integrates two synergistic components: (1) a progressive likelihood warm-up strategy to mitigate gradient conflicts; and (2) adaptive directional momentum (ADM) smoothing to reduce fluctuations in the likelihood gradient. Extensive experiments across diverse restoration tasks demonstrate that SPGD significantly enhances generation stability, leading to state-of-the-art performance in quantitative metrics and visually superior results. Code is available at \href{https://github.com/74587887/SPGD}{here}.
Memory-Augmented Dual-Decoder Networks for Multi-Class Unsupervised Anomaly Detection
Apr 21, 2025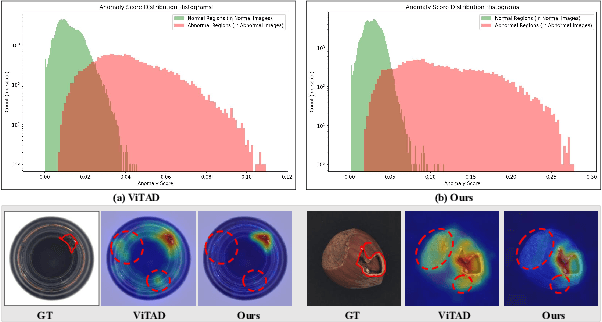
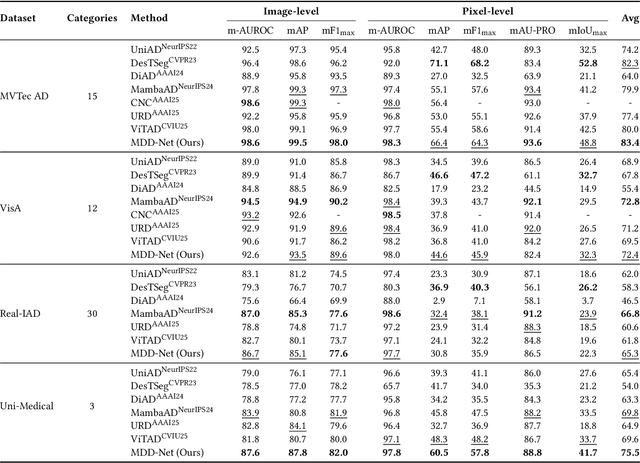
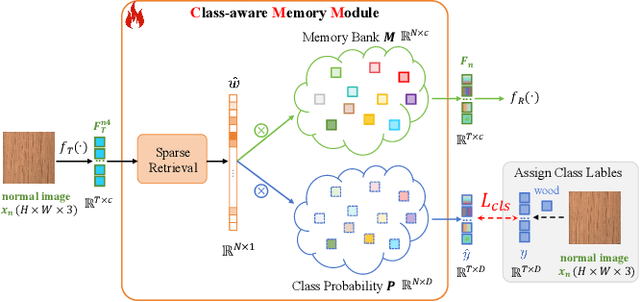
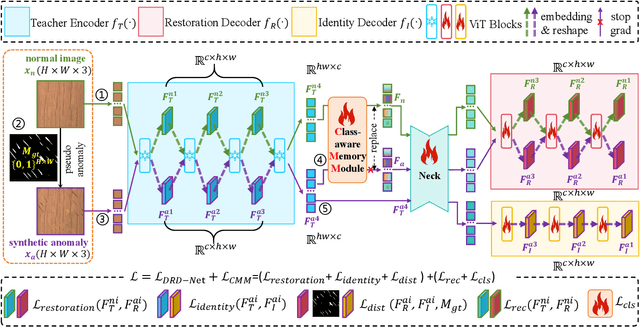
Recent advances in unsupervised anomaly detection (UAD) have shifted from single-class to multi-class scenarios. In such complex contexts, the increasing pattern diversity has brought two challenges to reconstruction-based approaches: (1) over-generalization: anomalies that are subtle or share compositional similarities with normal patterns may be reconstructed with high fidelity, making them difficult to distinguish from normal instances; and (2) insufficient normality reconstruction: complex normal features, such as intricate textures or fine-grained structures, may not be faithfully reconstructed due to the model's limited representational capacity, resulting in false positives. Existing methods typically focus on addressing the former, which unintentionally exacerbate the latter, resulting in inadequate representation of intricate normal patterns. To concurrently address these two challenges, we propose a Memory-augmented Dual-Decoder Networks (MDD-Net). This network includes two critical components: a Dual-Decoder Reverse Distillation Network (DRD-Net) and a Class-aware Memory Module (CMM). Specifically, the DRD-Net incorporates a restoration decoder designed to recover normal features from synthetic abnormal inputs and an identity decoder to reconstruct features that maintain the anomalous semantics. By exploiting the discrepancy between features produced by two decoders, our approach refines anomaly scores beyond the conventional encoder-decoder comparison paradigm, effectively reducing false positives and enhancing localization accuracy. Furthermore, the CMM explicitly encodes and preserves class-specific normal prototypes, actively steering the network away from anomaly reconstruction. Comprehensive experimental results across several benchmarks demonstrate the superior performance of our MDD-Net framework over current SoTA approaches in multi-class UAD tasks.
Can We Get Rid of Handcrafted Feature Extractors? SparseViT: Nonsemantics-Centered, Parameter-Efficient Image Manipulation Localization Through Spare-Coding Transformer
Dec 19, 2024
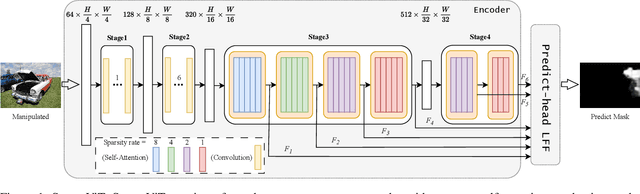
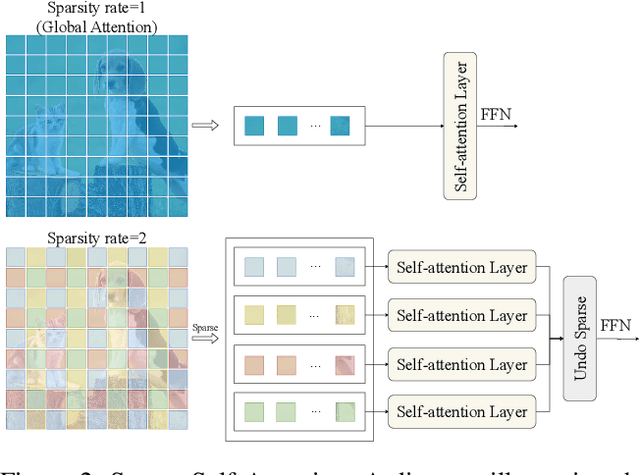
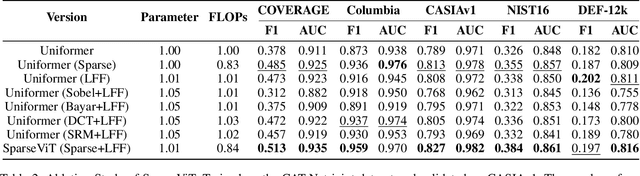
Non-semantic features or semantic-agnostic features, which are irrelevant to image context but sensitive to image manipulations, are recognized as evidential to Image Manipulation Localization (IML). Since manual labels are impossible, existing works rely on handcrafted methods to extract non-semantic features. Handcrafted non-semantic features jeopardize IML model's generalization ability in unseen or complex scenarios. Therefore, for IML, the elephant in the room is: How to adaptively extract non-semantic features? Non-semantic features are context-irrelevant and manipulation-sensitive. That is, within an image, they are consistent across patches unless manipulation occurs. Then, spare and discrete interactions among image patches are sufficient for extracting non-semantic features. However, image semantics vary drastically on different patches, requiring dense and continuous interactions among image patches for learning semantic representations. Hence, in this paper, we propose a Sparse Vision Transformer (SparseViT), which reformulates the dense, global self-attention in ViT into a sparse, discrete manner. Such sparse self-attention breaks image semantics and forces SparseViT to adaptively extract non-semantic features for images. Besides, compared with existing IML models, the sparse self-attention mechanism largely reduced the model size (max 80% in FLOPs), achieving stunning parameter efficiency and computation reduction. Extensive experiments demonstrate that, without any handcrafted feature extractors, SparseViT is superior in both generalization and efficiency across benchmark datasets.
Diffusion Posterior Proximal Sampling for Image Restoration
Feb 25, 2024



Diffusion models have demonstrated remarkable efficacy in generating high-quality samples. Existing diffusion-based image restoration algorithms exploit pre-trained diffusion models to leverage data priors, yet they still preserve elements inherited from the unconditional generation paradigm. These strategies initiate the denoising process with pure white noise and incorporate random noise at each generative step, leading to over-smoothed results. In this paper, we introduce a refined paradigm for diffusion-based image restoration. Specifically, we opt for a sample consistent with the measurement identity at each generative step, exploiting the sampling selection as an avenue for output stability and enhancement. Besides, we start the restoration process with an initialization combined with the measurement signal, providing supplementary information to better align the generative process. Extensive experimental results and analyses validate the effectiveness of our proposed approach across diverse image restoration tasks.