 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency Guided Optimization of Diffusion Latents
Paper and Code
Oct 14, 2024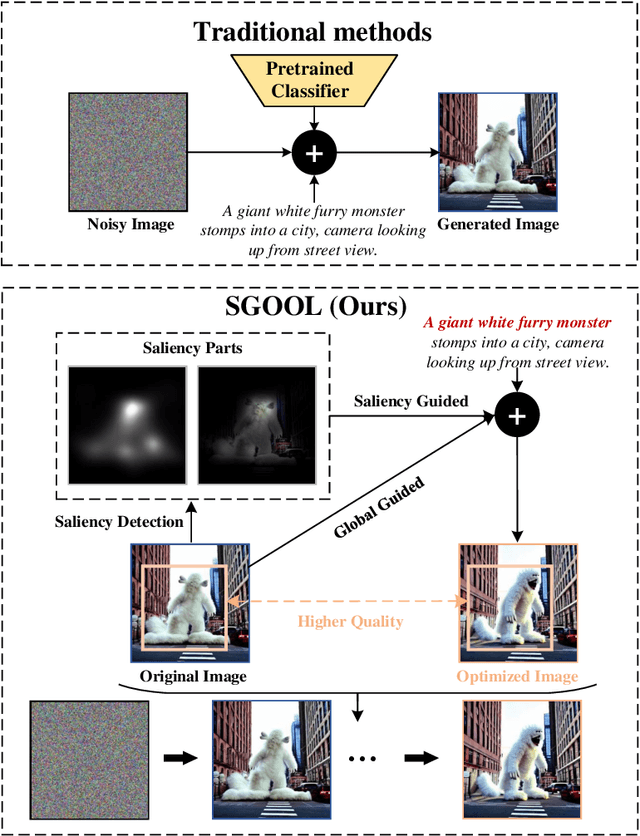

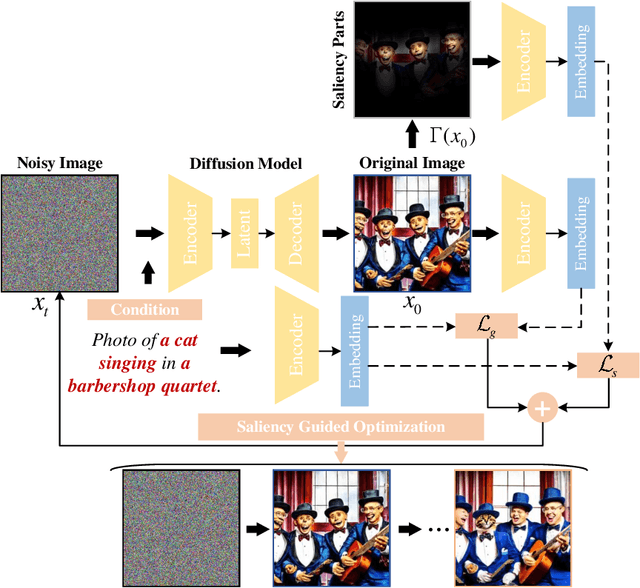
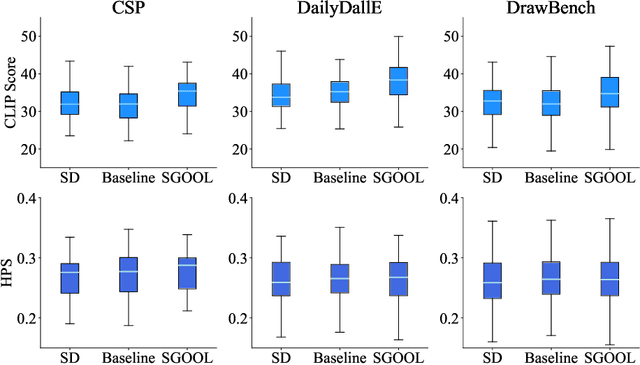
With the rapid advances in diffusion models, generating decent images from text prompts is no longer challenging. The key to text-to-image generation is how to optimize the results of a text-to-image generation model so that they can be better aligned with human intentions or prompts. Existing optimization methods commonly treat the entire image uniformly and conduct global optimization. These methods overlook the fact that when viewing an image, the human visual system naturally prioritizes attention toward salient areas, often neglecting less or non-salient regions. That is, humans are likely to neglect optimizations in non-salient areas. Consequently, although model retaining is conducted under the guidance of additional large and multimodality models, existing methods, which perform uniform optimizations, yield sub-optimal results. To address this alignment challenge effectively and efficiently, we propose Saliency Guided Optimization Of Diffusion Latents (SGOOL). We first employ a saliency detector to mimic the human visual attention system and mark out the salient regions. To avoid retraining an additional model, our method directly optimizes the diffusion latents. Besides, SGOOL utilizes an invertible diffusion process and endows it with the merits of constant memory implementation. Hence, our method becomes a parameter-efficient and plug-and-play fine-tuning method. Extensive experiments have been done with several metrics and human evaluation. Experimental results demonstrate the superiority of SGOOL in image quality and prompt alignment.