 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild
Apr 13, 2026This paper presents an overview of the NTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild, held in conjunction with the NTIRE workshop at CVPR 2026. The goal of this challenge was to develop detection models capable of distinguishing real images from generated ones in realistic scenarios: the images are often transformed (cropped, resized, compressed, blurred) for practical usage, and therefore, the detection models should be robust to such transformations. The challenge is based on a novel dataset consisting of 108,750 real and 185,750 AI-generated images from 42 generators comprising a large variety of open-source and closed-source models of various architectures, augmented with 36 image transformations. Methods were evaluated using ROC AUC on the full test set, including both transformed and untransformed images. A total of 511 participants registered, with 20 teams submitting valid final solutions. This report provides a comprehensive overview of the challenge, describes the proposed solutions, and can be used as a valuable reference for researchers and practitioners in increasing the robustness of the detection models to real-world transformations.
TextShield-R1: Reinforced Reasoning for Tampered Text Detection
Feb 23, 2026The growing prevalence of tampered images poses serious security threats, highlighting the urgent need for reliable detection methods. Multimodal large language models (MLLMs) demonstrate strong potential in analyzing tampered images and generating interpretations. However, they still struggle with identifying micro-level artifacts, exhibit low accuracy in localizing tampered text regions, and heavily rely on expensive annotations for forgery interpretation. To this end, we introduce TextShield-R1, the first reinforcement learning based MLLM solution for tampered text detection and reasoning. Specifically, our approach introduces Forensic Continual Pre-training, an easy-to-hard curriculum that well prepares the MLLM for tampered text detection by harnessing the large-scale cheap data from natural image forensic and OCR tasks. During fine-tuning, we perform Group Relative Policy Optimization with novel reward functions to reduce annotation dependency and improve reasoning capabilities. At inference time, we enhance localization accuracy via OCR Rectification, a method that leverages the MLLM's strong text recognition abilities to refine its predictions. Furthermore, to support rigorous evaluation, we introduce the Text Forensics Reasoning (TFR) benchmark, comprising over 45k real and tampered images across 16 languages, 10 tampering techniques, and diverse domains. Rich reasoning-style annotations are included, allowing for comprehensive assessment. Our TFR benchmark simultaneously addresses seven major limitations of existing benchmarks and enables robust evaluation under cross-style, cross-method, and cross-language conditions. Extensive experiments demonstrate that TextShield-R1 significantly advances the state of the art in interpretable tampered text detection.
Webly-Supervised Image Manipulation Localization via Category-Aware Auto-Annotation
Aug 28, 2025
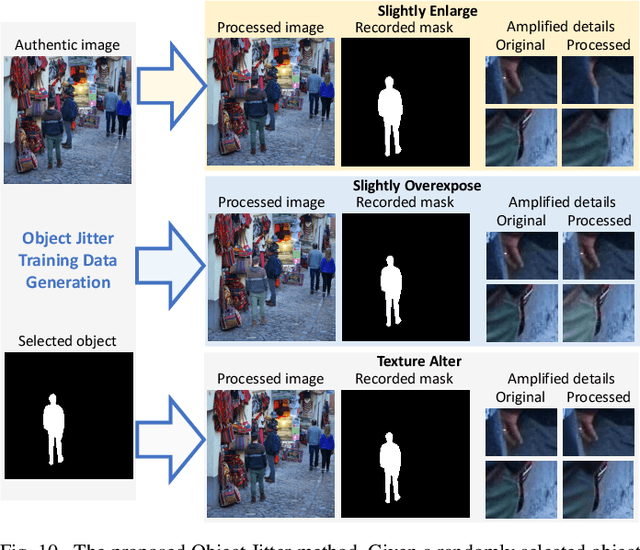
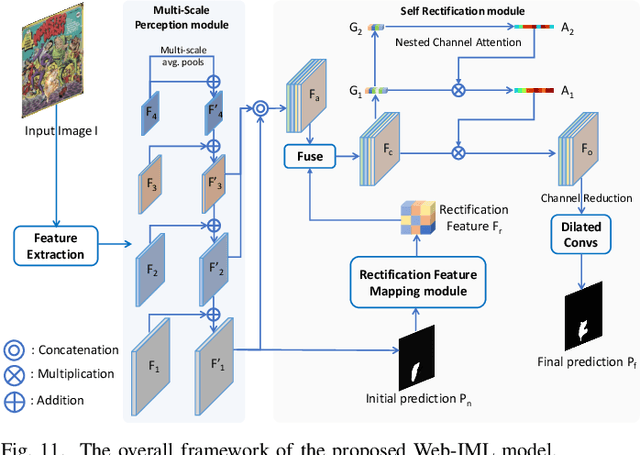

Images manipulated using image editing tools can mislead viewers and pose significant risks to social security. However, accurately localizing the manipulated regions within an image remains a challenging problem. One of the main barriers in this area is the high cost of data acquisition and the severe lack of high-quality annotated datasets. To address this challenge, we introduce novel methods that mitigate data scarcity by leveraging readily available web data. We utilize a large collection of manually forged images from the web, as well as automatically generated annotations derived from a simpler auxiliary task, constrained image manipulation localization. Specifically, we introduce a new paradigm CAAAv2, which automatically and accurately annotates manipulated regions at the pixel level. To further improve annotation quality, we propose a novel metric, QES, which filters out unreliable annotations. Through CAAA v2 and QES, we construct MIMLv2, a large-scale, diverse, and high-quality dataset containing 246,212 manually forged images with pixel-level mask annotations. This is over 120x larger than existing handcrafted datasets like IMD20. Additionally, we introduce Object Jitter, a technique that further enhances model training by generating high-quality manipulation artifacts. Building on these advances, we develop a new model, Web-IML, designed to effectively leverage web-scale supervision for the image manipulation localization task. Extensive experiments demonstrate that our approach substantially alleviates the data scarcity problem and significantly improves the performance of various models on multiple real-world forgery benchmarks. With the proposed web supervision, Web-IML achieves a striking performance gain of 31% and surpasses previous SOTA TruFor by 24.1 average IoU points. The dataset and code will be made publicly available at https://github.com/qcf-568/MIML.
ForensicHub: A Unified Benchmark & Codebase for All-Domain Fake Image Detection and Localization
May 16, 2025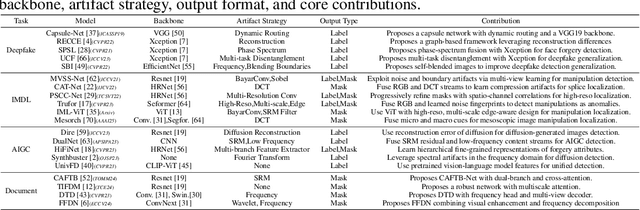
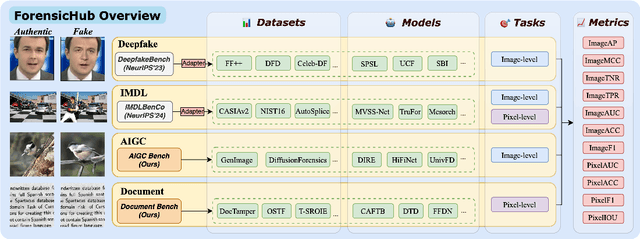
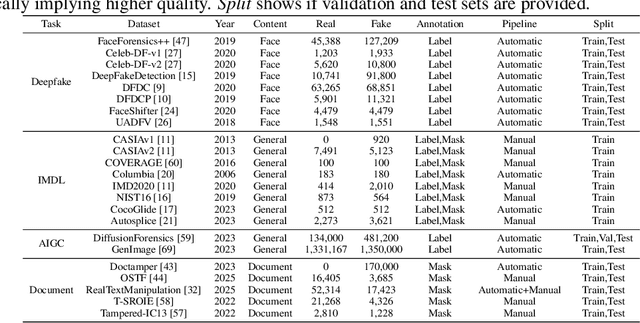
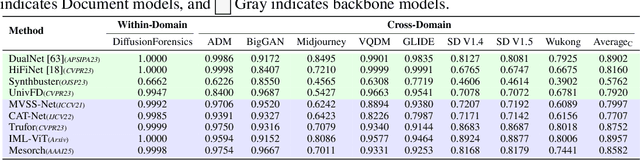
The field of Fake Image Detection and Localization (FIDL) is highly fragmented, encompassing four domains: deepfake detection (Deepfake), image manipulation detection and localization (IMDL), artificial intelligence-generated image detection (AIGC), and document image manipulation localization (Doc). Although individual benchmarks exist in some domains, a unified benchmark for all domains in FIDL remains blank. The absence of a unified benchmark results in significant domain silos, where each domain independently constructs its datasets, models, and evaluation protocols without interoperability, preventing cross-domain comparisons and hindering the development of the entire FIDL field. To close the domain silo barrier, we propose ForensicHub, the first unified benchmark & codebase for all-domain fake image detection and localization. Considering drastic variations on dataset, model, and evaluation configurations across all domains, as well as the scarcity of open-sourced baseline models and the lack of individual benchmarks in some domains, ForensicHub: i) proposes a modular and configuration-driven architecture that decomposes forensic pipelines into interchangeable components across datasets, transforms, models, and evaluators, allowing flexible composition across all domains; ii) fully implements 10 baseline models, 6 backbones, 2 new benchmarks for AIGC and Doc, and integrates 2 existing benchmarks of DeepfakeBench and IMDLBenCo through an adapter-based design; iii) conducts indepth analysis based on the ForensicHub, offering 8 key actionable insights into FIDL model architecture, dataset characteristics, and evaluation standards. ForensicHub represents a significant leap forward in breaking the domain silos in the FIDL field and inspiring future breakthroughs.
Explainable Tampered Text Detection via Multimodal Large Models
Dec 19, 2024



Recently, tampered text detection has attracted increasing attention due to its essential role in information security. Although existing methods can detect the tampered text region, the interpretation of such detection remains unclear, making the prediction unreliable. To address this black-box problem, we propose to explain the basis of tampered text detection with natural language via large multimodal models. To fill the data gap for this task, we propose a large-scale, comprehensive dataset, ETTD, which contains both pixel-level annotations indicating the tampered text region and natural language annotations describing the anomaly of the tampered text. Multiple methods are employed to improve the quality of the proposed data. For example, a fused mask prompt is proposed to reduce confusion when querying GPT4o to generate anomaly descriptions. By weighting the input image with the mask annotation, the tampered region can be clearly indicated and the content in and around the tampered region can also be preserved. We also propose prompting GPT4o to recognize tampered texts and filtering out the responses with low OCR accuracy, which can effectively improve annotation quality in an automatic manner. To further improve explainable tampered text detection, we propose a simple yet effective model called TTD, which benefits from improved fine-grained perception by paying attention to the suspected region with auxiliary reference grounding query. Extensive experiments on both the ETTD dataset and the public dataset have verified the effectiveness of the proposed methods. In-depth analysis is also provided to inspire further research. The dataset and code will be made publicly available.
Omni-IML: Towards Unified Image Manipulation Localization
Nov 22, 2024

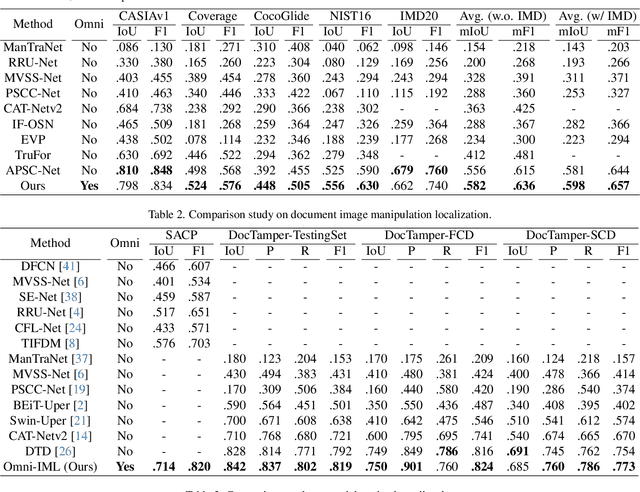

Image manipulation can lead to misinterpretation of visual content, posing significant risks to information security. Image Manipulation Localization (IML) has thus received increasing attention. However, existing IML methods rely heavily on task-specific designs, making them perform well only on one target image type but are mostly random guessing on other image types, and even joint training on multiple image types causes significant performance degradation. This hinders the deployment for real applications as it notably increases maintenance costs and the misclassification of image types leads to serious error accumulation. To this end, we propose Omni-IML, the first generalist model to unify diverse IML tasks. Specifically, Omni-IML achieves generalism by adopting the Modal Gate Encoder and the Dynamic Weight Decoder to adaptively determine the optimal encoding modality and the optimal decoder filters for each sample. We additionally propose an Anomaly Enhancement module that enhances the features of tampered regions with box supervision and helps the generalist model to extract common features across different IML tasks. We validate our approach on IML tasks across three major scenarios: natural images, document images, and face images. Without bells and whistles, our Omni-IML achieves state-of-the-art performance on all three tasks with a single unified model, providing valuable strategies and insights for real-world application and future research in generalist image forensics. Our code will be publicly available.
Generalized Tampered Scene Text Detection in the era of Generative AI
Jul 31, 2024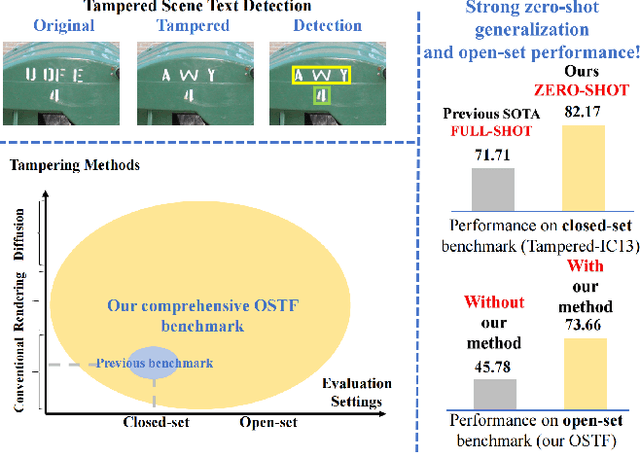

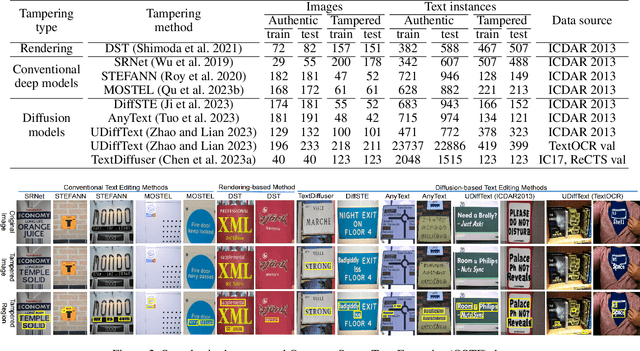

The rapid advancements of generative AI have fueled the potential of generative text image editing while simultaneously escalating the threat of misinformation spreading. However, existing forensics methods struggle to detect unseen forgery types that they have not been trained on, leaving the development of a model capable of generalized detection of tampered scene text as an unresolved issue. To tackle this, we propose a novel task: open-set tampered scene text detection, which evaluates forensics models on their ability to identify both seen and previously unseen forgery types. We have curated a comprehensive, high-quality dataset, featuring the texts tampered by eight text editing models, to thoroughly assess the open-set generalization capabilities. Further, we introduce a novel and effective pre-training paradigm that subtly alters the texture of selected texts within an image and trains the model to identify these regions. This approach not only mitigates the scarcity of high-quality training data but also enhances models' fine-grained perception and open-set generalization abilities. Additionally, we present DAF, a novel framework that improves open-set generalization by distinguishing between the features of authentic and tampered text, rather than focusing solely on the tampered text's features. Our extensive experiments validate the remarkable efficacy of our methods. For example, our zero-shot performance can even beat the previous state-of-the-art full-shot model by a large margin. Our dataset and code will be open-source.