 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-IML: Towards Unified Image Manipulation Localization
Paper and Code
Nov 22, 2024

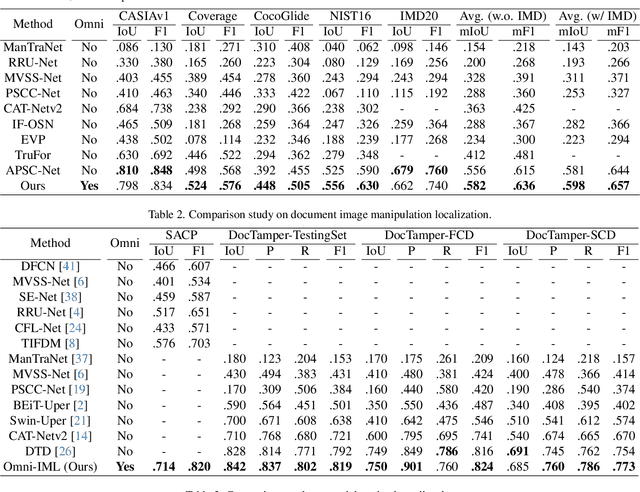

Image manipulation can lead to misinterpretation of visual content, posing significant risks to information security. Image Manipulation Localization (IML) has thus received increasing attention. However, existing IML methods rely heavily on task-specific designs, making them perform well only on one target image type but are mostly random guessing on other image types, and even joint training on multiple image types causes significant performance degradation. This hinders the deployment for real applications as it notably increases maintenance costs and the misclassification of image types leads to serious error accumulation. To this end, we propose Omni-IML, the first generalist model to unify diverse IML tasks. Specifically, Omni-IML achieves generalism by adopting the Modal Gate Encoder and the Dynamic Weight Decoder to adaptively determine the optimal encoding modality and the optimal decoder filters for each sample. We additionally propose an Anomaly Enhancement module that enhances the features of tampered regions with box supervision and helps the generalist model to extract common features across different IML tasks. We validate our approach on IML tasks across three major scenarios: natural images, document images, and face images. Without bells and whistles, our Omni-IML achieves state-of-the-art performance on all three tasks with a single unified model, providing valuable strategies and insights for real-world application and future research in generalist image forensics. Our code will be publicly available.