 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIceBench-S2S: A Benchmark of Deep Learning for Challenging Subseasonal-to-Seasonal Daily Arctic Sea Ice Forecasting in Deep Latent Space
Jan 31, 2026Arctic sea ice plays a critical role in regulating Earth's climate system, significantly influencing polar ecological stability and human activities in coastal regions. Recent advances in artificial intelligence have facilitated the development of skillful pan-Arctic sea ice forecasting systems, where data-driven approaches showcase tremendous potential to outperform conventional physics-based numerical models in terms of accuracy, computational efficiency and forecasting lead times. Despite the latest progress made by deep learning (DL) forecasting models, most of their skillful forecasting lead times are confined to daily subseasonal scale and monthly averaged values for up to six months, which drastically hinders their deployment for real-world applications, e.g., maritime routine planning for Arctic transportation and scientific investigation. Extending daily forecasts from subseasonal to seasonal (S2S) scale is scientifically crucial for operational applications. To bridge the gap between the forecasting lead time of current DL models and the significant daily S2S scale, we introduce IceBench-S2S, the first comprehensive benchmark for evaluating DL approaches in mitigating the challenge of forecasting Arctic sea ice concentration in successive 180-day periods. It proposes a generalized framework that first compresses spatial features of daily sea ice data into a deep latent space. The temporally concatenated deep features are subsequently modeled by DL-based forecasting backbones to predict the sea ice variation at S2S scale. IceBench-S2S provides a unified training and evaluation pipeline for different backbones, along with practical guidance for model selection in polar environmental monitoring tasks.
CLO: Efficient LLM Inference System with CPU-Light KVCache Offloading via Algorithm-System Co-Design
Nov 18, 2025The growth of million-token LLMs exposes the scalability limits of inference systems, where the KVCache dominates memory usage and data transfer overhead. Recent offloading systems migrate the KVCache to CPU memory and incorporate top-k attention to reduce the volume of data transferred from the CPU, while further applying system-level optimizations such as on-GPU caching and prefetching to lower transfer overhead. However, they overlook the CPU bottleneck in three aspects: (1) substantial overhead of fine-grained dynamic cache management performed on the CPU side, (2) significant transfer overhead from poor PCIe bandwidth utilization caused by heavy gathering operations at the CPU side, and (3) GPU runtime bubbles introduced by coarse-grained CPU-centric synchronization. To address these challenges, we propose CLO, a CPU-light KVCache offloading system via algorithm-system co-design. CLO features: (1) a coarse-grained head-wise approximate on-GPU caching strategy with negligible cache management cost, (2) seamless combination of data prefetching and on-GPU persistent caching for lower transfer overhead, (3) a zero-copy transfer engine to fully exploit PCIe bandwidth, and a GPU-centric synchronization method to eliminate GPU stalls. Evaluation on two widely-used LLMs demonstrates that CLO achieves comparable accuracy to state-of-the-art systems, while substantially minimizing CPU overhead, fully utilizing PCIe bandwidth, thus improving decoding throughput by 9.3%-66.6%. Our results highlight that algorithm-system co-design is essential for memory-constrained LLM inference on modern GPU platforms. We open source CLO at https://github.com/CommediaJW/CLO.
Efficient Long-Context LLM Inference via KV Cache Clustering
Jun 13, 2025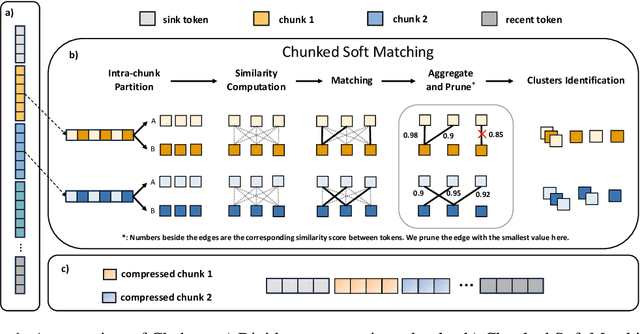
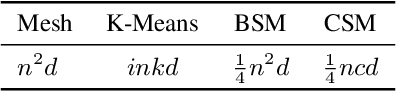
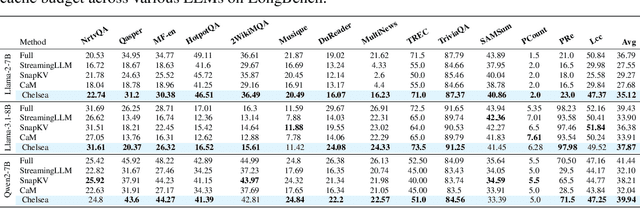
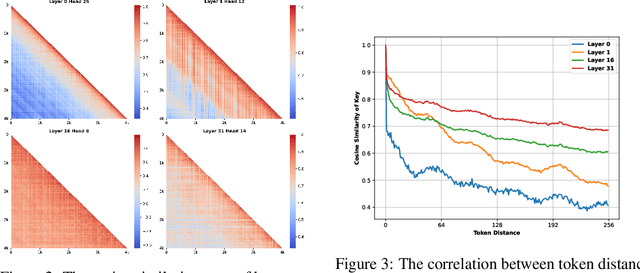
Large language models (LLMs) with extended context windows have become increasingly prevalent for tackling complex tasks. However, the substantial Key-Value (KV) cache required for long-context LLMs poses significant deployment challenges. Existing approaches either discard potentially critical information needed for future generations or offer limited efficiency gains due to high computational overhead. In this paper, we introduce Chelsea, a simple yet effective framework for online KV cache clustering. Our approach is based on the observation that key states exhibit high similarity along the sequence dimension. To enable efficient clustering, we divide the sequence into chunks and propose Chunked Soft Matching, which employs an alternating partition strategy within each chunk and identifies clusters based on similarity. Chelsea then merges the KV cache within each cluster into a single centroid. Additionally, we provide a theoretical analysis of the computational complexity and the optimality of the intra-chunk partitioning strategy. Extensive experiments across various models and long-context benchmarks demonstrate that Chelsea achieves up to 80% reduction in KV cache memory usage while maintaining comparable model performance. Moreover, with minimal computational overhead, Chelsea accelerates the decoding stage of inference by up to 3.19$\times$ and reduces end-to-end latency by up to 2.72$\times$.
BigMac: A Communication-Efficient Mixture-of-Experts Model Structure for Fast Training and Inference
Feb 24, 2025The Mixture-of-Experts (MoE) structure scales the Transformer-based large language models (LLMs) and improves their performance with only the sub-linear increase in computation resources. Recently, a fine-grained DeepSeekMoE structure is proposed, which can further improve the computing efficiency of MoE without performance degradation. However, the All-to-All communication introduced by MoE has become a bottleneck, especially for the fine-grained structure, which typically involves and activates more experts, hence contributing to heavier communication overhead. In this paper, we propose a novel MoE structure named BigMac, which is also fine-grained but with high communication efficiency. The innovation of BigMac is mainly due to that we abandon the \textbf{c}ommunicate-\textbf{d}escend-\textbf{a}scend-\textbf{c}ommunicate (CDAC) manner used by fine-grained MoE, which leads to the All-to-All communication always taking place at the highest dimension. Instead, BigMac designs an efficient \textbf{d}escend-\textbf{c}ommunicate-\textbf{c}ommunicate-\textbf{a}scend (DCCA) manner. Specifically, we add a descending and ascending projection at the entrance and exit of the expert, respectively, which enables the communication to perform at a very low dimension. Furthermore, to adapt to DCCA, we re-design the structure of small experts, ensuring that the expert in BigMac has enough complexity to address tokens. Experimental results show that BigMac achieves comparable or even better model quality than fine-grained MoEs with the same number of experts and a similar number of total parameters. Equally importantly, BigMac reduces the end-to-end latency by up to 3.09$\times$ for training and increases the throughput by up to 3.11$\times$ for inference on state-of-the-art AI computing frameworks including Megatron, Tutel, and DeepSpeed-Inference.
SIFM: A Foundation Model for Multi-granularity Arctic Sea Ice Forecasting
Oct 16, 2024


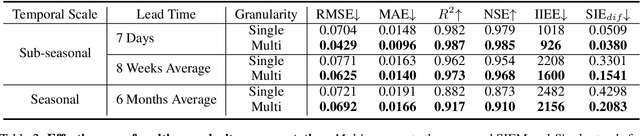
Arctic sea ice performs a vital role in global climate and has paramount impacts on both polar ecosystems and coastal communities. In the last few years, multiple deep learning based pan-Arctic sea ice concentration (SIC) forecasting methods have emerged and showcased superior performance over physics-based dynamical models. However, previous methods forecast SIC at a fixed temporal granularity, e.g. sub-seasonal or seasonal, thus only leveraging inter-granularity information and overlooking the plentiful inter-granularity correlations. SIC at various temporal granularities exhibits cumulative effects and are naturally consistent, with short-term fluctuations potentially impacting long-term trends and long-term trends provides effective hints for facilitating short-term forecasts in Arctic sea ice. Therefore, in this study, we propose to cultivate temporal multi-granularity that naturally derived from Arctic sea ice reanalysis data and provide a unified perspective for modeling SIC via our Sea Ice Foundation Model. SIFM is delicately designed to leverage both intra-granularity and inter-granularity information for capturing granularity-consistent representations that promote forecasting skills. Our extensive experiments show that SIFM outperforms off-the-shelf deep learning models for their specific temporal granularity.
XL3M: A Training-free Framework for LLM Length Extension Based on Segment-wise Inference
May 28, 2024



Length generalization failure problem, namely the large language model (LLM) fails to generalize to texts longer than its maximum training length, greatly restricts the application of LLM in the scenarios with streaming long inputs. To address this problem, the existing methods either require substantial costs or introduce precision loss. In this paper, we empirically find that the accuracy of the LLM's prediction is highly correlated to its certainty. Based on this, we propose an efficient training free framework, named XL3M (it means extra-long large language model), which enables the LLMs trained on short sequences to reason extremely long sequence without any further training or fine-tuning. Under the XL3M framework, the input context will be firstly decomposed into multiple short sub-contexts, where each sub-context contains an independent segment and a common ``question'' which is a few tokens from the end of the original context. Then XL3M gives a method to measure the relevance between each segment and the ``question'', and constructs a concise key context by splicing all the relevant segments in chronological order. The key context is further used instead of the original context to complete the inference task. Evaluations on comprehensive benchmarks show the superiority of XL3M. Using our framework, a Llama2-7B model is able to reason 20M long sequences on an 8-card Huawei Ascend 910B NPU machine with 64GB memory per card.
BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences
Mar 14, 2024
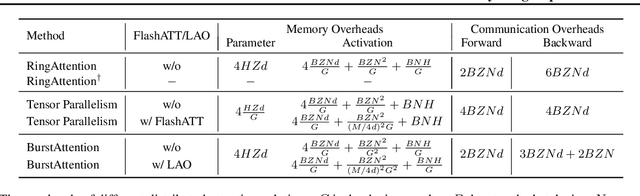

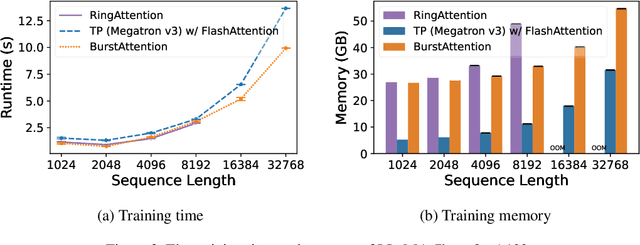
Effective attention modules have played a crucial role in the success of Transformer-based large language models (LLMs), but the quadratic time and memory complexities of these attention modules also pose a challenge when processing long sequences. One potential solution for the long sequence problem is to utilize distributed clusters to parallelize the computation of attention modules across multiple devices (e.g., GPUs). However, adopting a distributed approach inevitably introduces extra memory overheads to store local attention results and incurs additional communication costs to aggregate local results into global ones. In this paper, we propose a distributed attention framework named ``BurstAttention'' to optimize memory access and communication operations at both the global cluster and local device levels. In our experiments, we compare BurstAttention with other competitive distributed attention solutions for long sequence processing. The experimental results under different length settings demonstrate that BurstAttention offers significant advantages for processing long sequences compared with these competitive baselines, reducing 40% communication overheads and achieving 2 X speedup during training 32K sequence length on 8 X A100.
Digital twin-assisted three-dimensional electrical capacitance tomography for multiphase flow imaging
Dec 22, 2023Three-dimensional electrical capacitance tomography (3D-ECT) has shown promise for visualizing industrial multiphase flows. However, existing 3D-ECT approaches suffer from limited imaging resolution and lack assessment metrics, hampering their effectiveness in quantitative multiphase flow imaging. This paper presents a digital twin (DT)-assisted 3D-ECT, aiming to overcome these limitations and enhance our understanding of multiphase flow dynamics. The DT framework incorporates a 3D fluid-electrostatic field coupling model (3D-FECM) that digitally represents the physical 3D-ECT system, which enables us to simulate real multiphase flows and generate a comprehensive virtual multiphase flow 3D imaging dataset. Additionally, the framework includes a deep neural network named 3D deep back projection (3D-DBP), which learns multiphase flow features from the virtual dataset and enables more accurate 3D flow imaging in the real world. The DT-assisted 3D-ECT was validated through virtual and physical experiments, demonstrating superior image quality, noise robustness and computational efficiency compared to conventional 3D-ECT approaches. This research contributes to developing accurate and reliable 3D-ECT techniques and their implementation in multiphase flow systems across various industries.
Progressively Stacking 2.0: A Multi-stage Layerwise Training Method for BERT Training Speedup
Nov 27, 2020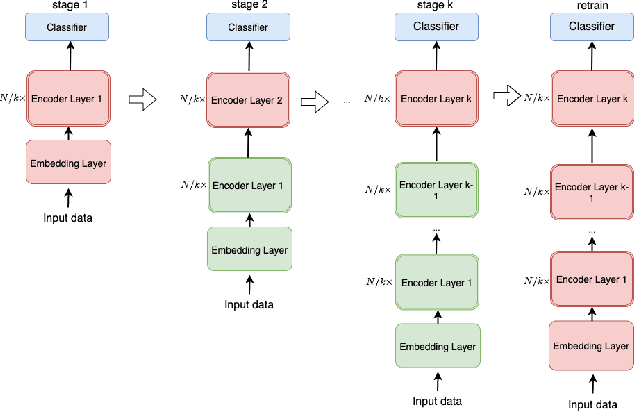
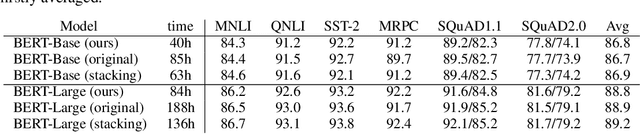
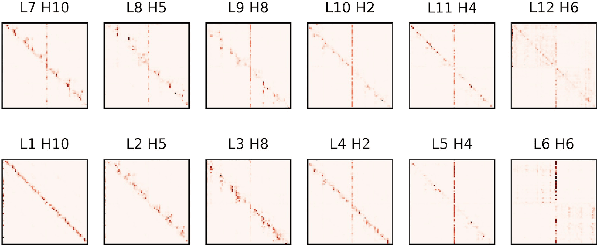
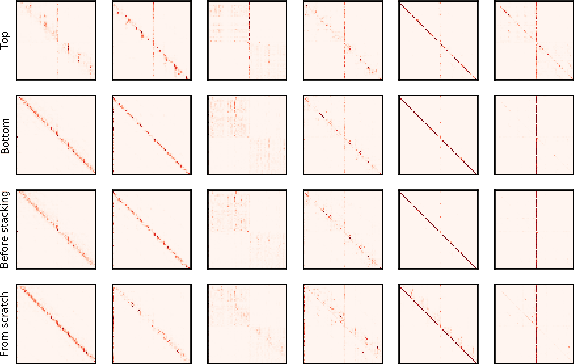
Pre-trained language models, such as BERT, have achieved significant accuracy gain in many natural language processing tasks. Despite its effectiveness, the huge number of parameters makes training a BERT model computationally very challenging. In this paper, we propose an efficient multi-stage layerwise training (MSLT) approach to reduce the training time of BERT. We decompose the whole training process into several stages. The training is started from a small model with only a few encoder layers and we gradually increase the depth of the model by adding new encoder layers. At each stage, we only train the top (near the output layer) few encoder layers which are newly added. The parameters of the other layers which have been trained in the previous stages will not be updated in the current stage. In BERT training, the backward computation is much more time-consuming than the forward computation, especially in the distributed training setting in which the backward computation time further includes the communication time for gradient synchronization. In the proposed training strategy, only top few layers participate in backward computation, while most layers only participate in forward computation. Hence both the computation and communication efficiencies are greatly improved. Experimental results show that the proposed method can achieve more than 110% training speedup without significant performance degradation.
CoRe: An Efficient Coarse-refined Training Framework for BERT
Nov 27, 2020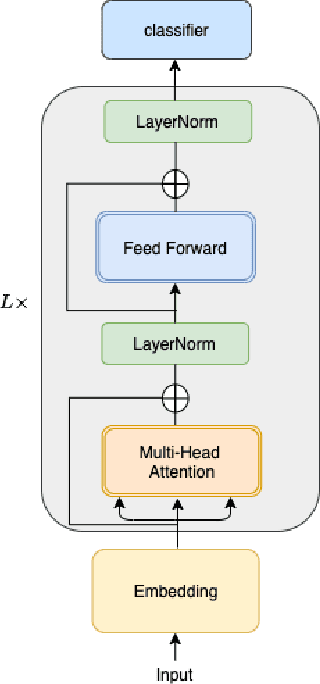
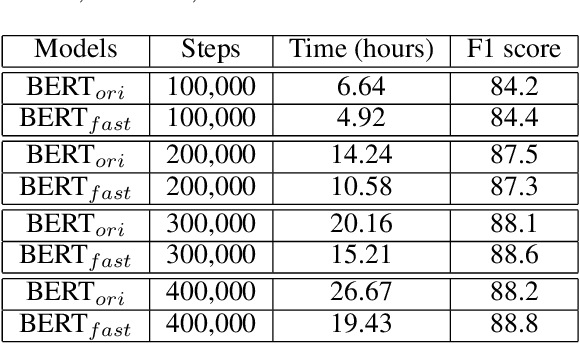
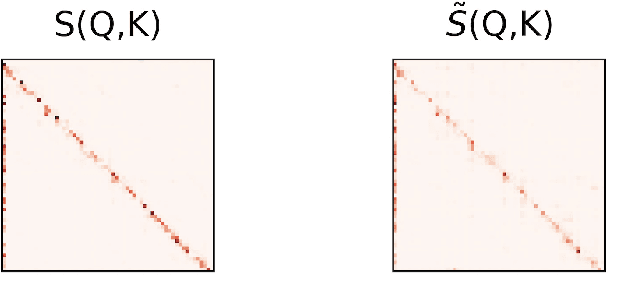
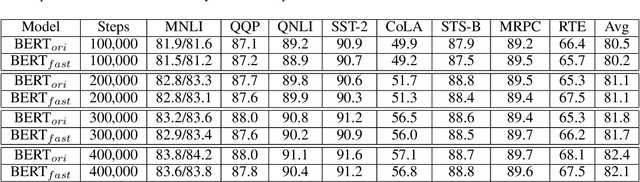
In recent years, BERT has made significant breakthroughs on many natural language processing tasks and attracted great attentions. Despite its accuracy gains, the BERT model generally involves a huge number of parameters and needs to be trained on massive datasets, so training such a model is computationally very challenging and time-consuming. Hence, training efficiency should be a critical issue. In this paper, we propose a novel coarse-refined training framework named CoRe to speed up the training of BERT. Specifically, we decompose the training process of BERT into two phases. In the first phase, by introducing fast attention mechanism and decomposing the large parameters in the feed-forward network sub-layer, we construct a relaxed BERT model which has much less parameters and much lower model complexity than the original BERT, so the relaxed model can be quickly trained. In the second phase, we transform the trained relaxed BERT model into the original BERT and further retrain the model. Thanks to the desired initialization provided by the relaxed model, the retraining phase requires much less training steps, compared with training an original BERT model from scratch with a random initialization. Experimental results show that the proposed CoRe framework can greatly reduce the training time without reducing the performance.