 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Reasoning Reward Model for Agents
Jan 29, 2026Agentic Reinforcement Learning (Agentic RL) has achieved notable success in enabling agents to perform complex reasoning and tool use. However, most methods still relies on sparse outcome-based reward for training. Such feedback fails to differentiate intermediate reasoning quality, leading to suboptimal training results. In this paper, we introduce Agent Reasoning Reward Model (Agent-RRM), a multi-faceted reward model that produces structured feedback for agentic trajectories, including (1) an explicit reasoning trace , (2) a focused critique that provides refinement guidance by highlighting reasoning flaws, and (3) an overall score that evaluates process performance. Leveraging these signals, we systematically investigate three integration strategies: Reagent-C (text-augmented refinement), Reagent-R (reward-augmented guidance), and Reagent-U (unified feedback integration). Extensive evaluations across 12 diverse benchmarks demonstrate that Reagent-U yields substantial performance leaps, achieving 43.7% on GAIA and 46.2% on WebWalkerQA, validating the effectiveness of our reasoning reward model and training schemes. Code, models, and datasets are all released to facilitate future research.
Rethinking Sample Polarity in Reinforcement Learning with Verifiable Rewards
Dec 25, 2025Large reasoning models (LRMs) are typically trained using reinforcement learning with verifiable reward (RLVR) to enhance their reasoning abilities. In this paradigm, policies are updated using both positive and negative self-generated rollouts, which correspond to distinct sample polarities. In this paper, we provide a systematic investigation into how these sample polarities affect RLVR training dynamics and behaviors. We find that positive samples sharpen existing correct reasoning patterns, while negative samples encourage exploration of new reasoning paths. We further explore how adjusting the advantage values of positive and negative samples at both the sample level and the token level affects RLVR training. Based on these insights, we propose an Adaptive and Asymmetric token-level Advantage shaping method for Policy Optimization, namely A3PO, that more precisely allocates advantage signals to key tokens across different polarities. Experiments across five reasoning benchmarks demonstrate the effectiveness of our approach.
AdaTooler-V: Adaptive Tool-Use for Images and Videos
Dec 19, 2025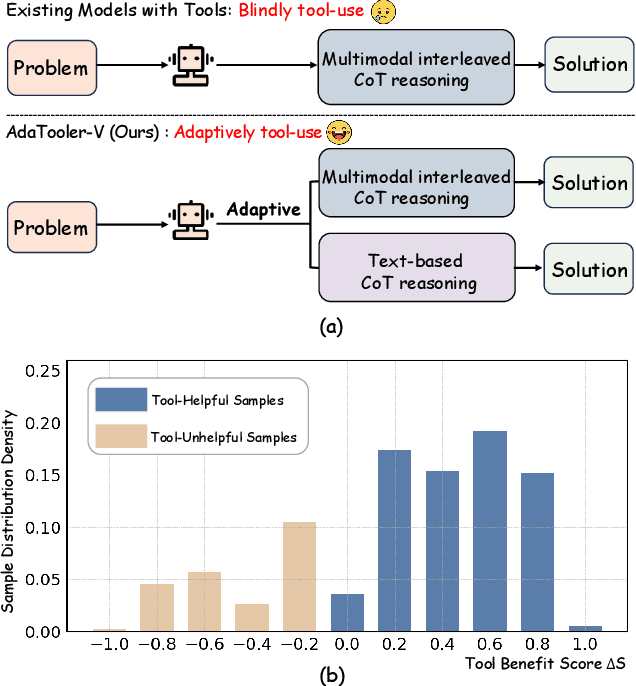
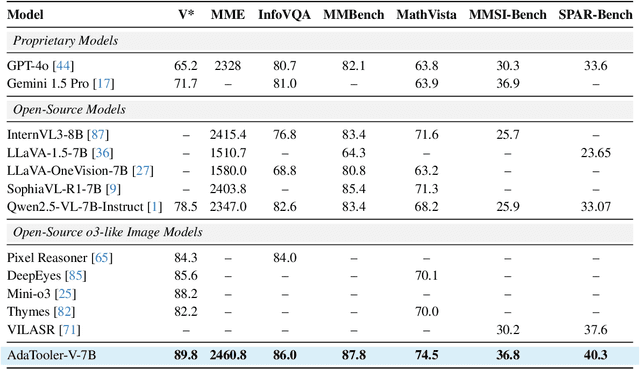
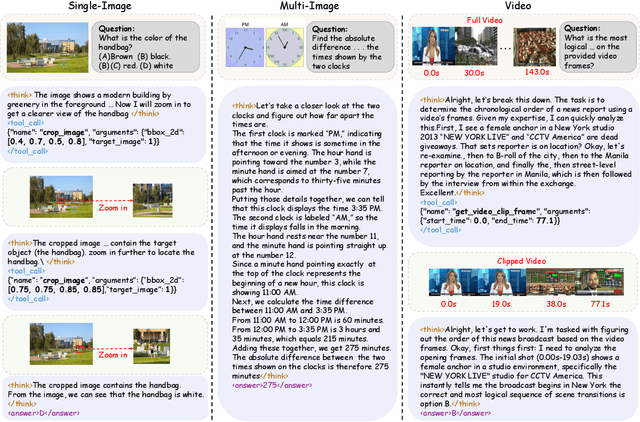
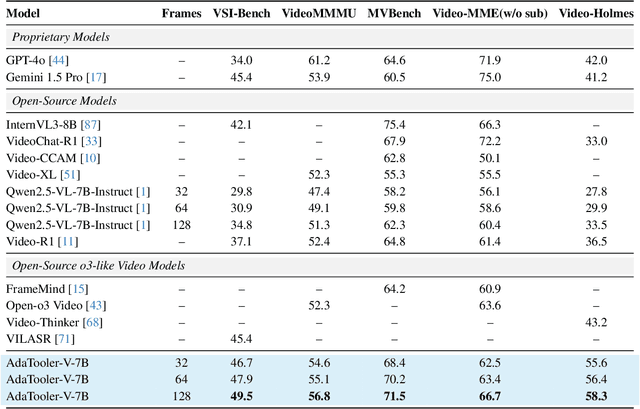
Recent advances have shown that multimodal large language models (MLLMs) benefit from multimodal interleaved chain-of-thought (CoT) with vision tool interactions. However, existing open-source models often exhibit blind tool-use reasoning patterns, invoking vision tools even when they are unnecessary, which significantly increases inference overhead and degrades model performance. To this end, we propose AdaTooler-V, an MLLM that performs adaptive tool-use by determining whether a visual problem truly requires tools. First, we introduce AT-GRPO, a reinforcement learning algorithm that adaptively adjusts reward scales based on the Tool Benefit Score of each sample, encouraging the model to invoke tools only when they provide genuine improvements. Moreover, we construct two datasets to support training: AdaTooler-V-CoT-100k for SFT cold start and AdaTooler-V-300k for RL with verifiable rewards across single-image, multi-image, and video data. Experiments across twelve benchmarks demonstrate the strong reasoning capability of AdaTooler-V, outperforming existing methods in diverse visual reasoning tasks. Notably, AdaTooler-V-7B achieves an accuracy of 89.8\% on the high-resolution benchmark V*, surpassing the commercial proprietary model GPT-4o and Gemini 1.5 Pro. All code, models, and data are released.
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
EraRAG: Efficient and Incremental Retrieval Augmented Generation for Growing Corpora
Jun 26, 2025Graph-based Retrieval-Augmented Generation (Graph-RAG) enhances large language models (LLMs) by structuring retrieval over an external corpus. However, existing approaches typically assume a static corpus, requiring expensive full-graph reconstruction whenever new documents arrive, limiting their scalability in dynamic, evolving environments. To address these limitations, we introduce EraRAG, a novel multi-layered Graph-RAG framework that supports efficient and scalable dynamic updates. Our method leverages hyperplane-based Locality-Sensitive Hashing (LSH) to partition and organize the original corpus into hierarchical graph structures, enabling efficient and localized insertions of new data without disrupting the existing topology. The design eliminates the need for retraining or costly recomputation while preserving high retrieval accuracy and low latency. Experiments on large-scale benchmarks demonstrate that EraRag achieves up to an order of magnitude reduction in update time and token consumption compared to existing Graph-RAG systems, while providing superior accuracy performance. This work offers a practical path forward for RAG systems that must operate over continually growing corpora, bridging the gap between retrieval efficiency and adaptability. Our code and data are available at https://github.com/EverM0re/EraRAG-Official.
Can LLMs Alleviate Catastrophic Forgetting in Graph Continual Learning? A Systematic Study
May 24, 2025Nowadays, real-world data, including graph-structure data, often arrives in a streaming manner, which means that learning systems need to continuously acquire new knowledge without forgetting previously learned information. Although substantial existing works attempt to address catastrophic forgetting in graph machine learning, they are all based on training from scratch with streaming data. With the rise of pretrained models, an increasing number of studies have leveraged their strong generalization ability for continual learning. Therefore, in this work, we attempt to answer whether large language models (LLMs) can mitigate catastrophic forgetting in Graph Continual Learning (GCL). We first point out that current experimental setups for GCL have significant flaws, as the evaluation stage may lead to task ID leakage. Then, we evaluate the performance of LLMs in more realistic scenarios and find that even minor modifications can lead to outstanding results. Finally, based on extensive experiments, we propose a simple-yet-effective method, Simple Graph Continual Learning (SimGCL), that surpasses the previous state-of-the-art GNN-based baseline by around 20% under the rehearsal-free constraint. To facilitate reproducibility, we have developed an easy-to-use benchmark LLM4GCL for training and evaluating existing GCL methods. The code is available at: https://github.com/ZhixunLEE/LLM4GCL.
Materials Generation in the Era of Artificial Intelligence: A Comprehensive Survey
May 22, 2025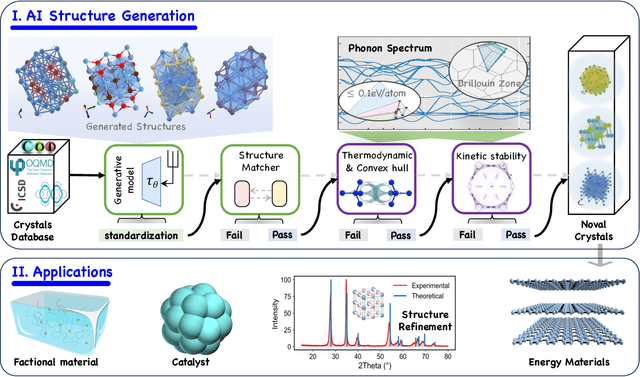

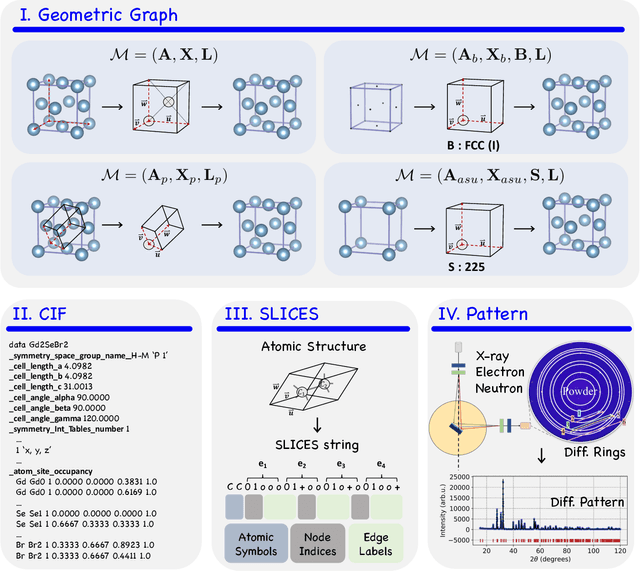
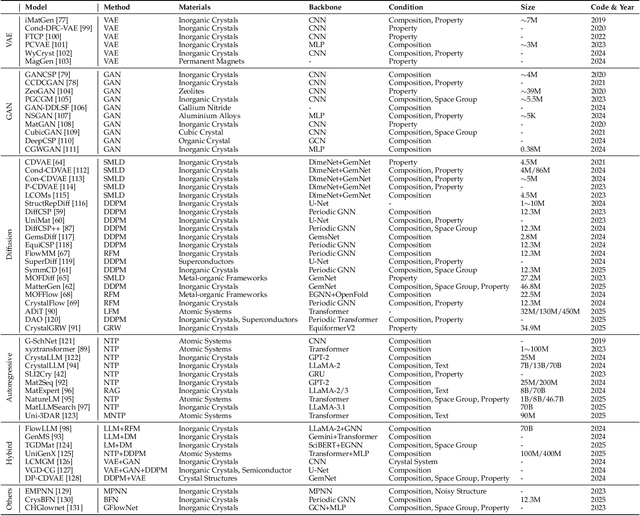
Materials are the foundation of modern society, underpinning advancements in energy, electronics, healthcare, transportation, and infrastructure. The ability to discover and design new materials with tailored properties is critical to solving some of the most pressing global challenges. In recent years, the growing availability of high-quality materials data combined with rapid advances in Artificial Intelligence (AI) has opened new opportunities for accelerating materials discovery. Data-driven generative models provide a powerful tool for materials design by directly create novel materials that satisfy predefined property requirements. Despite the proliferation of related work, there remains a notable lack of up-to-date and systematic surveys in this area. To fill this gap, this paper provides a comprehensive overview of recent progress in AI-driven materials generation. We first organize various types of materials and illustrate multiple representations of crystalline materials. We then provide a detailed summary and taxonomy of current AI-driven materials generation approaches. Furthermore, we discuss the common evaluation metrics and summarize open-source codes and benchmark datasets. Finally, we conclude with potential future directions and challenges in this fast-growing field. The related sources can be found at https://github.com/ZhixunLEE/Awesome-AI-for-Materials-Generation.
IceBerg: Debiased Self-Training for Class-Imbalanced Node Classification
Feb 10, 2025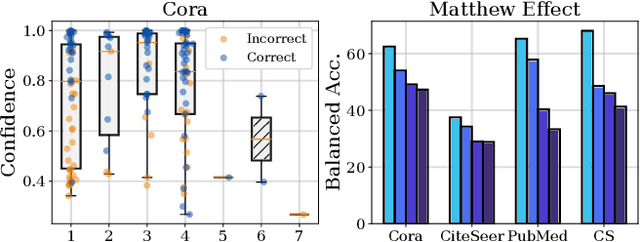
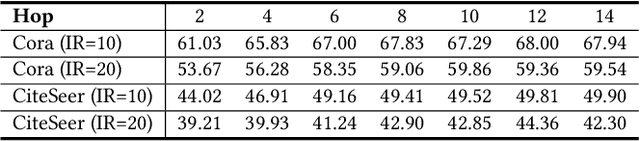
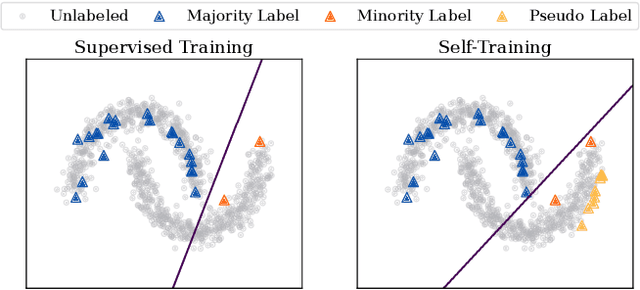
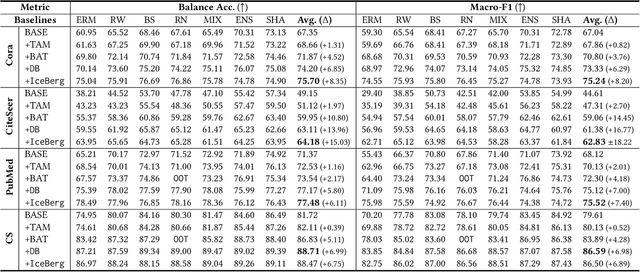
Graph Neural Networks (GNNs) have achieved great success in dealing with non-Euclidean graph-structured data and have been widely deployed in many real-world applications. However, their effectiveness is often jeopardized under class-imbalanced training sets. Most existing studies have analyzed class-imbalanced node classification from a supervised learning perspective, but they do not fully utilize the large number of unlabeled nodes in semi-supervised scenarios. We claim that the supervised signal is just the tip of the iceberg and a large number of unlabeled nodes have not yet been effectively utilized. In this work, we propose IceBerg, a debiased self-training framework to address the class-imbalanced and few-shot challenges for GNNs at the same time. Specifically, to figure out the Matthew effect and label distribution shift in self-training, we propose Double Balancing, which can largely improve the performance of existing baselines with just a few lines of code as a simple plug-and-play module. Secondly, to enhance the long-range propagation capability of GNNs, we disentangle the propagation and transformation operations of GNNs. Therefore, the weak supervision signals can propagate more effectively to address the few-shot issue. In summary, we find that leveraging unlabeled nodes can significantly enhance the performance of GNNs in class-imbalanced and few-shot scenarios, and even small, surgical modifications can lead to substantial performance improvements. Systematic experiments on benchmark datasets show that our method can deliver considerable performance gain over existing class-imbalanced node classification baselines. Additionally, due to IceBerg's outstanding ability to leverage unsupervised signals, it also achieves state-of-the-art results in few-shot node classification scenarios. The code of IceBerg is available at: https://github.com/ZhixunLEE/IceBerg.
GDeR: Safeguarding Efficiency, Balancing, and Robustness via Prototypical Graph Pruning
Oct 17, 2024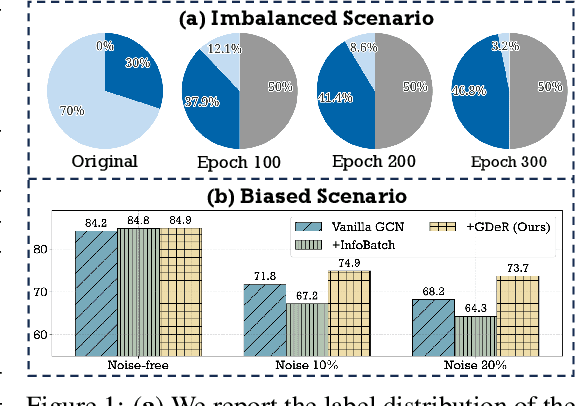
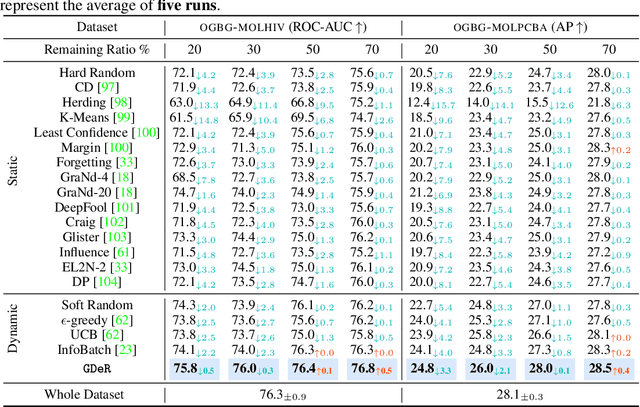
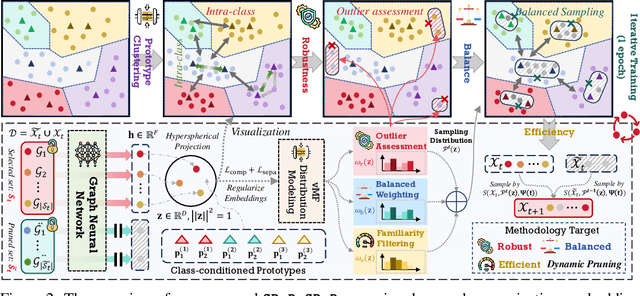
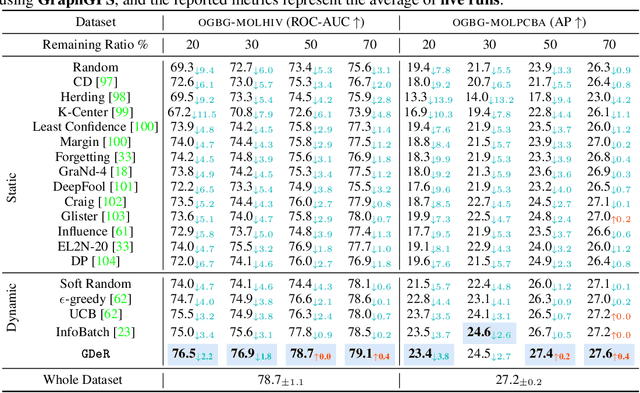
Training high-quality deep models necessitates vast amounts of data, resulting in overwhelming computational and memory demands. Recently, data pruning, distillation, and coreset selection have been developed to streamline data volume by retaining, synthesizing, or selecting a small yet informative subset from the full set. Among these methods, data pruning incurs the least additional training cost and offers the most practical acceleration benefits. However, it is the most vulnerable, often suffering significant performance degradation with imbalanced or biased data schema, thus raising concerns about its accuracy and reliability in on-device deployment. Therefore, there is a looming need for a new data pruning paradigm that maintains the efficiency of previous practices while ensuring balance and robustness. Unlike the fields of computer vision and natural language processing, where mature solutions have been developed to address these issues, graph neural networks (GNNs) continue to struggle with increasingly large-scale, imbalanced, and noisy datasets, lacking a unified dataset pruning solution. To achieve this, we introduce a novel dynamic soft-pruning method, GDeR, designed to update the training ``basket'' during the process using trainable prototypes. GDeR first constructs a well-modeled graph embedding hypersphere and then samples \textit{representative, balanced, and unbiased subsets} from this embedding space, which achieves the goal we called Graph Training Debugging. Extensive experiments on five datasets across three GNN backbones, demonstrate that GDeR (I) achieves or surpasses the performance of the full dataset with 30%~50% fewer training samples, (II) attains up to a 2.81x lossless training speedup, and (III) outperforms state-of-the-art pruning methods in imbalanced training and noisy training scenarios by 0.3%~4.3% and 3.6%~7.8%, respectively.
Cut the Crap: An Economical Communication Pipeline for LLM-based Multi-Agent Systems
Oct 03, 2024



Recent advancements in large language model (LLM)-powered agents have shown that collective intelligence can significantly outperform individual capabilities, largely attributed to the meticulously designed inter-agent communication topologies. Though impressive in performance, existing multi-agent pipelines inherently introduce substantial token overhead, as well as increased economic costs, which pose challenges for their large-scale deployments. In response to this challenge, we propose an economical, simple, and robust multi-agent communication framework, termed $\texttt{AgentPrune}$, which can seamlessly integrate into mainstream multi-agent systems and prunes redundant or even malicious communication messages. Technically, $\texttt{AgentPrune}$ is the first to identify and formally define the \textit{communication redundancy} issue present in current LLM-based multi-agent pipelines, and efficiently performs one-shot pruning on the spatial-temporal message-passing graph, yielding a token-economic and high-performing communication topology. Extensive experiments across six benchmarks demonstrate that $\texttt{AgentPrune}$ \textbf{(I)} achieves comparable results as state-of-the-art topologies at merely $\$5.6$ cost compared to their $\$43.7$, \textbf{(II)} integrates seamlessly into existing multi-agent frameworks with $28.1\%\sim72.8\%\downarrow$ token reduction, and \textbf{(III)} successfully defend against two types of agent-based adversarial attacks with $3.5\%\sim10.8\%\uparrow$ performance boost.