 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile UMI: Cross-View Diffusion Policy with Decoupled Kinematics for Mobile Manipulation
May 20, 2026Mobile imitation learning on portable demonstration interfaces faces two coupled bottlenecks: locomotion-contaminated action labels and inference-induced execution latency on a continuously moving base. Recent wrist-mounted interfaces lower the cost of tabletop data collection, yet a single wrist view does not capture the global context required for base navigation. Adding a body-mounted camera entangles human walking with hand motion. Meanwhile, generative policies introduce hundreds of milliseconds of inference latency, during which the base advances past predicted waypoints, forcing backward corrections at action splices. This paper presents Mobile UMI, a hardware-free demonstration framework that addresses both gaps through three components. First, a dual-camera capture system records chest-centric global context and wrist-centric local interaction without any robot present. Second, a one-shot ChArUco-based spatial anchor unifies the chest and hand visual-inertial frames; the hand pose is then re-expressed relative to the chest to extract decoupled SE(3) manipulation and SE(2) base trajectories. Third, an asynchronous receding-horizon executor performs online state matching: each generated action chunk is realigned with the current physical pose so that expired waypoints are discarded before execution. The full system is evaluated on four long-horizon household tasks, achieving an average success rate of 83.8% over 100 trials per task. Controlled comparisons against ACT and Diffusion Policy show that the chest-relative label alone closes much of the gap; online state matching closes the remainder. These results indicate that, for mobile imitation learning under the tested conditions, explicit kinematic factorization combined with state-level latency alignment provides an effective solution without requiring architectural changes to the underlying policy class.
Agent-ValueBench: A Comprehensive Benchmark for Evaluating Agent Values
May 11, 2026Autonomous agents have rapidly matured as task executors and seen widespread deployment via harnesses such as OpenClaw. Safety concerns have rightly drawn growing research attention, and beneath them lie the values silently steering agent behavior. Existing value benchmarks, however, remain confined to LLMs, leaving agent values largely uncharted. From intuitive, empirical, and theoretical vantage points, we show that an agent's values diverge from those of its underlying LLM, and the agentic modality further introduces dataset-, evaluation-, and system-level challenges absent from text-only protocols. We close this gap with Agent-ValueBench, the first benchmark dedicated to agent values. It features 394 executable environments across 16 domains, offering 4,335 value-conflict tasks that cover 28 value systems and 332 dimensions. Every instance is co-synthesized through our purpose-built end-to-end pipeline and curated per-instance by professional psychologists. Each task ships with two pole-aligned golden trajectories whose checkpoints anchor a trajectory-level rubric-based judge. Benchmarking 14 frontier proprietary and open-weights models across 4 mainstream harnesses, we uncover three concerted findings. Agent values first manifest as a Value Tide of cross-model homogeneity beneath interpretable counter-currents. This tide bends non-additively under harness pull, and yet more decisively under deliberate steering via embedded skills. Together these results signal that the agent-alignment lever is shifting from classical model alignment and prompt steering toward harness alignment and skill steering.
NeuReasoner: Towards Explainable, Controllable, and Unified Reasoning via Mixture-of-Neurons
Apr 03, 2026Large Reasoning Models (LRMs) have recently achieved remarkable success in complex reasoning tasks. However, closer scrutiny reveals persistent failure modes compromising performance and cost: I) Intra-step level, marked by calculation or derivation errors; II) Inter-step level, involving oscillation and stagnation; and III) Instance level, causing maladaptive over-thinking. Existing endeavors target isolated levels without unification, while their black-box nature and reliance on RL hinder explainability and controllability. To bridge these gaps, we conduct an in-depth white-box analysis, identifying key neurons (Mixture of Neurons, MoN) and their fluctuation patterns associated with distinct failures. Building upon these insights, we propose NeuReasoner, an explainable, controllable, and unified reasoning framework driven by MoN. Technically, NeuReasoner integrates lightweight MLPs for failure detection with a special token-triggered self-correction mechanism learned via SFT. During inference, special tokens are inserted upon failure detection to actuate controllable remedial behaviors. Extensive evaluations across six benchmarks, six backbone models (8B~70B) against nine competitive baselines, demonstrate that NeuReasoner achieves performance gains of up to 27.0% while reducing token consumption by 19.6% ~ 63.3%.
FoE: Forest of Errors Makes the First Solution the Best in Large Reasoning Models
Apr 03, 2026Recent Large Reasoning Models (LRMs) like DeepSeek-R1 have demonstrated remarkable success in complex reasoning tasks, exhibiting human-like patterns in exploring multiple alternative solutions. Upon closer inspection, however, we uncover a surprising phenomenon: The First is The Best, where alternative solutions are not merely suboptimal but potentially detrimental. This observation challenges widely accepted test-time scaling laws, leading us to hypothesize that errors within the reasoning path scale concurrently with test time. Through comprehensive empirical analysis, we characterize errors as a forest-structured Forest of Errors (FoE) and conclude that FoE makes the First the Best, which is underpinned by rigorous theoretical analysis. Leveraging these insights, we propose RED, a self-guided efficient reasoning framework comprising two components: I) Refining First, which suppresses FoE growth in the first solution; and II) Discarding Subs, which prunes subsequent FoE via dual-consistency. Extensive experiments across five benchmarks and six backbone models demonstrate that RED outperforms eight competitive baselines, achieving performance gains of up to 19.0% while reducing token consumption by 37.7% ~ 70.4%. Moreover, comparative experiments on FoE metrics shed light on how RED achieves effectiveness.
IG-RFT: An Interaction-Guided RL Framework for VLA Models in Long-Horizon Robotic Manipulation
Feb 24, 2026Vision-Language-Action (VLA) models have demonstrated significant potential for generalist robotic policies; however, they struggle to generalize to long-horizon complex tasks in novel real-world domains due to distribution shifts and the scarcity of high-quality demonstrations. Although reinforcement learning (RL) offers a promising avenue for policy improvement, applying it to real-world VLA fine-tuning faces challenges regarding exploration efficiency, training stability, and sample cost. To address these issues, we propose IG-RFT, a novel Interaction-Guided Reinforced Fine-Tuning system designed for flow-based VLA models. Firstly, to facilitate effective policy optimization, we introduce Interaction-Guided Advantage Weighted Regression (IG-AWR), an RL algorithm that dynamically modulates exploration intensity based on the robot's interaction status. Furthermore, to address the limitations of sparse or task-specific rewards, we design a novel hybrid dense reward function that integrates the trajectory-level reward and the subtask-level reward. Finally, we construct a three-stage RL system comprising SFT, Offline RL, and Human-in-the-Loop RL for fine-tuning VLA models. Extensive real-world experiments on four challenging long-horizon tasks demonstrate that IG-RFT achieves an average success rate of 85.0%, significantly outperforming SFT (18.8%) and standard Offline RL baselines (40.0%). Ablation studies confirm the critical contributions of IG-AWR and hybrid reward shaping. In summary, our work establishes and validates a novel reinforced fine-tuning system for VLA models in real-world robotic manipulation.
Product Interaction: An Algebraic Formalism for Deep Learning Architectures
Jan 31, 2026In this paper, we introduce product interactions, an algebraic formalism in which neural network layers are constructed from compositions of a multiplication operator defined over suitable algebras. Product interactions provide a principled way to generate and organize algebraic expressions by increasing interaction order. Our central observation is that algebraic expressions in modern neural networks admit a unified construction in terms of linear, quadratic, and higher-order product interactions. Convolutional and equivariant networks arise as symmetry-constrained linear product interactions, while attention and Mamba correspond to higher-order product interactions.
Meta Context Engineering via Agentic Skill Evolution
Jan 29, 2026The operational efficacy of large language models relies heavily on their inference-time context. This has established Context Engineering (CE) as a formal discipline for optimizing these inputs. Current CE methods rely on manually crafted harnesses, such as rigid generation-reflection workflows and predefined context schemas. They impose structural biases and restrict context optimization to a narrow, intuition-bound design space. To address this, we introduce Meta Context Engineering (MCE), a bi-level framework that supersedes static CE heuristics by co-evolving CE skills and context artifacts. In MCE iterations, a meta-level agent refines engineering skills via agentic crossover, a deliberative search over the history of skills, their executions, and evaluations. A base-level agent executes these skills, learns from training rollouts, and optimizes context as flexible files and code. We evaluate MCE across five disparate domains under offline and online settings. MCE demonstrates consistent performance gains, achieving 5.6--53.8% relative improvement over state-of-the-art agentic CE methods (mean of 16.9%), while maintaining superior context adaptability, transferability, and efficiency in both context usage and training.
Meta-R1: Empowering Large Reasoning Models with Metacognition
Aug 24, 2025Large Reasoning Models (LRMs) demonstrate remarkable capabilities on complex tasks, exhibiting emergent, human-like thinking patterns. Despite their advances, we identify a fundamental limitation: current LRMs lack a dedicated meta-level cognitive system-an essential faculty in human cognition that enables "thinking about thinking". This absence leaves their emergent abilities uncontrollable (non-adaptive reasoning), unreliable (intermediate error), and inflexible (lack of a clear methodology). To address this gap, we introduce Meta-R1, a systematic and generic framework that endows LRMs with explicit metacognitive capabilities. Drawing on principles from cognitive science, Meta-R1 decomposes the reasoning process into distinct object-level and meta-level components, orchestrating proactive planning, online regulation, and adaptive early stopping within a cascaded framework. Experiments on three challenging benchmarks and against eight competitive baselines demonstrate that Meta-R1 is: (I) high-performing, surpassing state-of-the-art methods by up to 27.3%; (II) token-efficient, reducing token consumption to 15.7% ~ 32.7% and improving efficiency by up to 14.8% when compared to its vanilla counterparts; and (III) transferable, maintaining robust performance across datasets and model backbones.
AuroRA: Breaking Low-Rank Bottleneck of LoRA with Nonlinear Mapping
May 24, 2025Low-Rank Adaptation (LoRA) is a widely adopted parameter-efficient fine-tuning (PEFT) method validated across NLP and CV domains. However, LoRA faces an inherent low-rank bottleneck: narrowing its performance gap with full finetuning requires increasing the rank of its parameter matrix, resulting in significant parameter overhead. Recent linear LoRA variants have attempted to enhance expressiveness by introducing additional linear mappings; however, their composition remains inherently linear and fails to fundamentally improve LoRA's representational capacity. To address this limitation, we propose AuroRA, which incorporates an Adaptive Nonlinear Layer (ANL) between two linear projectors to capture fixed and learnable nonlinearities. This combination forms an MLP-like structure with a compressed rank, enabling flexible and precise approximation of diverse target functions while theoretically guaranteeing lower approximation errors and bounded gradients. Extensive experiments on 22 datasets and 6 pretrained models demonstrate that AuroRA: (I) not only matches or surpasses full fine-tuning performance with only 6.18% ~ 25% of LoRA's parameters but also (II) outperforms state-of-the-art PEFT methods by up to 10.88% in both NLP and CV tasks, and (III) exhibits robust performance across various rank configurations.
GDeR: Safeguarding Efficiency, Balancing, and Robustness via Prototypical Graph Pruning
Oct 17, 2024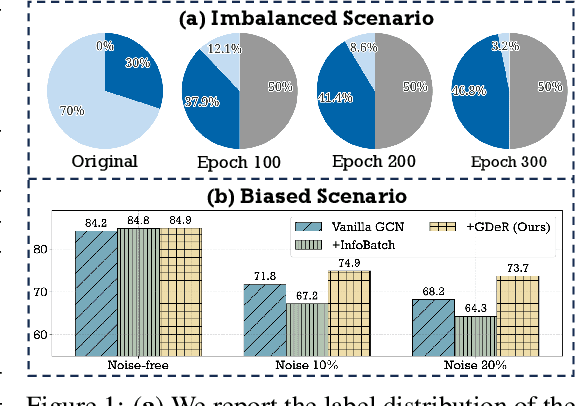
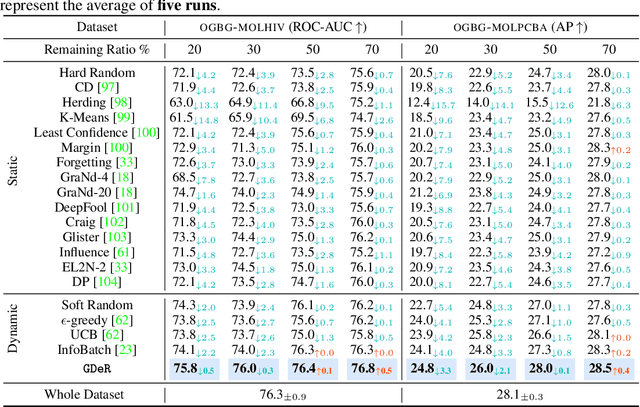
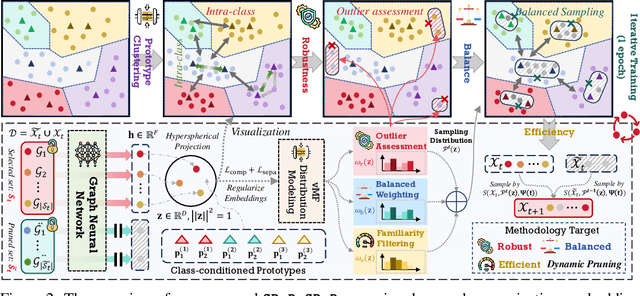
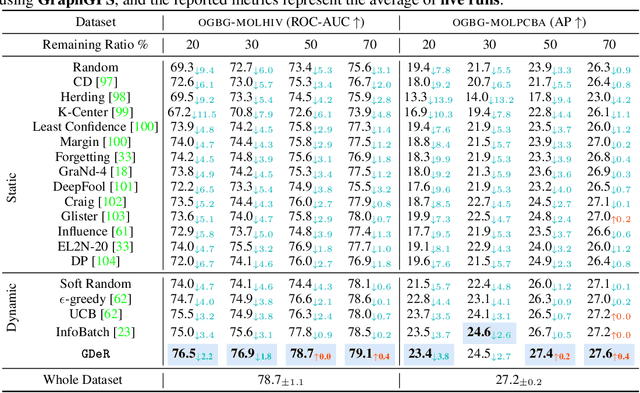
Training high-quality deep models necessitates vast amounts of data, resulting in overwhelming computational and memory demands. Recently, data pruning, distillation, and coreset selection have been developed to streamline data volume by retaining, synthesizing, or selecting a small yet informative subset from the full set. Among these methods, data pruning incurs the least additional training cost and offers the most practical acceleration benefits. However, it is the most vulnerable, often suffering significant performance degradation with imbalanced or biased data schema, thus raising concerns about its accuracy and reliability in on-device deployment. Therefore, there is a looming need for a new data pruning paradigm that maintains the efficiency of previous practices while ensuring balance and robustness. Unlike the fields of computer vision and natural language processing, where mature solutions have been developed to address these issues, graph neural networks (GNNs) continue to struggle with increasingly large-scale, imbalanced, and noisy datasets, lacking a unified dataset pruning solution. To achieve this, we introduce a novel dynamic soft-pruning method, GDeR, designed to update the training ``basket'' during the process using trainable prototypes. GDeR first constructs a well-modeled graph embedding hypersphere and then samples \textit{representative, balanced, and unbiased subsets} from this embedding space, which achieves the goal we called Graph Training Debugging. Extensive experiments on five datasets across three GNN backbones, demonstrate that GDeR (I) achieves or surpasses the performance of the full dataset with 30%~50% fewer training samples, (II) attains up to a 2.81x lossless training speedup, and (III) outperforms state-of-the-art pruning methods in imbalanced training and noisy training scenarios by 0.3%~4.3% and 3.6%~7.8%, respectively.