 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuReasoner: Towards Explainable, Controllable, and Unified Reasoning via Mixture-of-Neurons
Apr 03, 2026Large Reasoning Models (LRMs) have recently achieved remarkable success in complex reasoning tasks. However, closer scrutiny reveals persistent failure modes compromising performance and cost: I) Intra-step level, marked by calculation or derivation errors; II) Inter-step level, involving oscillation and stagnation; and III) Instance level, causing maladaptive over-thinking. Existing endeavors target isolated levels without unification, while their black-box nature and reliance on RL hinder explainability and controllability. To bridge these gaps, we conduct an in-depth white-box analysis, identifying key neurons (Mixture of Neurons, MoN) and their fluctuation patterns associated with distinct failures. Building upon these insights, we propose NeuReasoner, an explainable, controllable, and unified reasoning framework driven by MoN. Technically, NeuReasoner integrates lightweight MLPs for failure detection with a special token-triggered self-correction mechanism learned via SFT. During inference, special tokens are inserted upon failure detection to actuate controllable remedial behaviors. Extensive evaluations across six benchmarks, six backbone models (8B~70B) against nine competitive baselines, demonstrate that NeuReasoner achieves performance gains of up to 27.0% while reducing token consumption by 19.6% ~ 63.3%.
Meta-R1: Empowering Large Reasoning Models with Metacognition
Aug 24, 2025Large Reasoning Models (LRMs) demonstrate remarkable capabilities on complex tasks, exhibiting emergent, human-like thinking patterns. Despite their advances, we identify a fundamental limitation: current LRMs lack a dedicated meta-level cognitive system-an essential faculty in human cognition that enables "thinking about thinking". This absence leaves their emergent abilities uncontrollable (non-adaptive reasoning), unreliable (intermediate error), and inflexible (lack of a clear methodology). To address this gap, we introduce Meta-R1, a systematic and generic framework that endows LRMs with explicit metacognitive capabilities. Drawing on principles from cognitive science, Meta-R1 decomposes the reasoning process into distinct object-level and meta-level components, orchestrating proactive planning, online regulation, and adaptive early stopping within a cascaded framework. Experiments on three challenging benchmarks and against eight competitive baselines demonstrate that Meta-R1 is: (I) high-performing, surpassing state-of-the-art methods by up to 27.3%; (II) token-efficient, reducing token consumption to 15.7% ~ 32.7% and improving efficiency by up to 14.8% when compared to its vanilla counterparts; and (III) transferable, maintaining robust performance across datasets and model backbones.
DuPO: Enabling Reliable LLM Self-Verification via Dual Preference Optimization
Aug 20, 2025We present DuPO, a dual learning-based preference optimization framework that generates annotation-free feedback via a generalized duality. DuPO addresses two key limitations: Reinforcement Learning with Verifiable Rewards (RLVR)'s reliance on costly labels and applicability restricted to verifiable tasks, and traditional dual learning's restriction to strictly dual task pairs (e.g., translation and back-translation). Specifically, DuPO decomposes a primal task's input into known and unknown components, then constructs its dual task to reconstruct the unknown part using the primal output and known information (e.g., reversing math solutions to recover hidden variables), broadening applicability to non-invertible tasks. The quality of this reconstruction serves as a self-supervised reward to optimize the primal task, synergizing with LLMs' ability to instantiate both tasks via a single model. Empirically, DuPO achieves substantial gains across diverse tasks: it enhances the average translation quality by 2.13 COMET over 756 directions, boosts the mathematical reasoning accuracy by an average of 6.4 points on three challenge benchmarks, and enhances performance by 9.3 points as an inference-time reranker (trading computation for accuracy). These results position DuPO as a scalable, general, and annotation-free paradigm for LLM optimization.
Seed LiveInterpret 2.0: End-to-end Simultaneous Speech-to-speech Translation with Your Voice
Jul 24, 2025



Simultaneous Interpretation (SI) represents one of the most daunting frontiers in the translation industry, with product-level automatic systems long plagued by intractable challenges: subpar transcription and translation quality, lack of real-time speech generation, multi-speaker confusion, and translated speech inflation, especially in long-form discourses. In this study, we introduce Seed-LiveInterpret 2.0, an end-to-end SI model that delivers high-fidelity, ultra-low-latency speech-to-speech generation with voice cloning capabilities. As a fully operational product-level solution, Seed-LiveInterpret 2.0 tackles these challenges head-on through our novel duplex speech-to-speech understanding-generating framework. Experimental results demonstrate that through large-scale pretraining and reinforcement learning, the model achieves a significantly better balance between translation accuracy and latency, validated by human interpreters to exceed 70% correctness in complex scenarios. Notably, Seed-LiveInterpret 2.0 outperforms commercial SI solutions by significant margins in translation quality, while slashing the average latency of cloned speech from nearly 10 seconds to a near-real-time 3 seconds, which is around a near 70% reduction that drastically enhances practical usability.
AuroRA: Breaking Low-Rank Bottleneck of LoRA with Nonlinear Mapping
May 24, 2025Low-Rank Adaptation (LoRA) is a widely adopted parameter-efficient fine-tuning (PEFT) method validated across NLP and CV domains. However, LoRA faces an inherent low-rank bottleneck: narrowing its performance gap with full finetuning requires increasing the rank of its parameter matrix, resulting in significant parameter overhead. Recent linear LoRA variants have attempted to enhance expressiveness by introducing additional linear mappings; however, their composition remains inherently linear and fails to fundamentally improve LoRA's representational capacity. To address this limitation, we propose AuroRA, which incorporates an Adaptive Nonlinear Layer (ANL) between two linear projectors to capture fixed and learnable nonlinearities. This combination forms an MLP-like structure with a compressed rank, enabling flexible and precise approximation of diverse target functions while theoretically guaranteeing lower approximation errors and bounded gradients. Extensive experiments on 22 datasets and 6 pretrained models demonstrate that AuroRA: (I) not only matches or surpasses full fine-tuning performance with only 6.18% ~ 25% of LoRA's parameters but also (II) outperforms state-of-the-art PEFT methods by up to 10.88% in both NLP and CV tasks, and (III) exhibits robust performance across various rank configurations.
EAVIT: Efficient and Accurate Human Value Identification from Text data via LLMs
May 19, 2025The rapid evolution of large language models (LLMs) has revolutionized various fields, including the identification and discovery of human values within text data. While traditional NLP models, such as BERT, have been employed for this task, their ability to represent textual data is significantly outperformed by emerging LLMs like GPTs. However, the performance of online LLMs often degrades when handling long contexts required for value identification, which also incurs substantial computational costs. To address these challenges, we propose EAVIT, an efficient and accurate framework for human value identification that combines the strengths of both locally fine-tunable and online black-box LLMs. Our framework employs a value detector - a small, local language model - to generate initial value estimations. These estimations are then used to construct concise input prompts for online LLMs, enabling accurate final value identification. To train the value detector, we introduce explanation-based training and data generation techniques specifically tailored for value identification, alongside sampling strategies to optimize the brevity of LLM input prompts. Our approach effectively reduces the number of input tokens by up to 1/6 compared to directly querying online LLMs, while consistently outperforming traditional NLP methods and other LLM-based strategies.
Could Thinking Multilingually Empower LLM Reasoning?
Apr 16, 2025Previous work indicates that large language models exhibit a significant "English bias", i.e. they often perform better when tasks are presented in English. Interestingly, we have observed that using certain other languages in reasoning tasks can yield better performance than English. However, this phenomenon remains under-explored. In this paper, we explore the upper bound of harnessing multilingualism in reasoning tasks, suggesting that multilingual reasoning promises significantly (by nearly 10 Acc@$k$ points) and robustly (tolerance for variations in translation quality and language choice) higher upper bounds than English-only reasoning. Besides analyzing the reason behind the upper bound and challenges in reaching it, we also find that common answer selection methods cannot achieve this upper bound, due to their limitations and biases. These insights could pave the way for future research aimed at fully harnessing the potential of multilingual reasoning in LLMs.
Generalizing From Short to Long: Effective Data Synthesis for Long-Context Instruction Tuning
Feb 21, 2025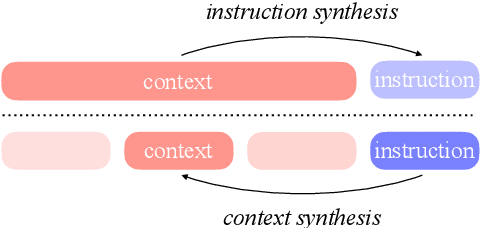

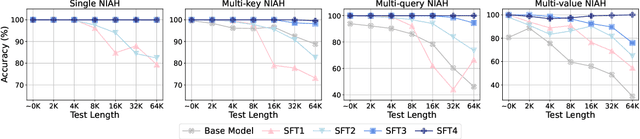
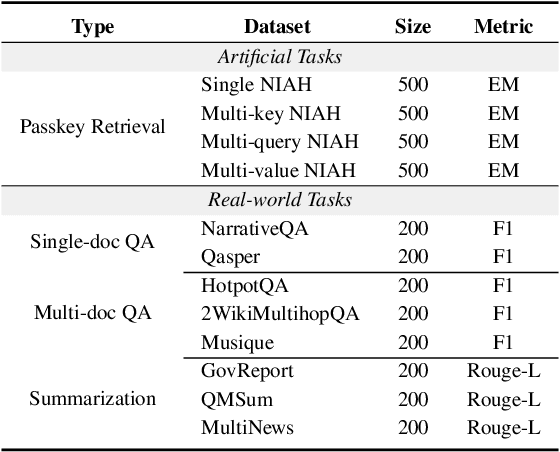
Long-context modelling for large language models (LLMs) has been a key area of recent research because many real world use cases require reasoning over longer inputs such as documents. The focus of research into modelling long context has been on how to model position and there has been little investigation into other important aspects of language modelling such as instruction tuning. Long context training examples are challenging and expensive to create and use. In this paper, we investigate how to design instruction data for the post-training phase of a long context pre-trained model: how much and what type of context is needed for optimal and efficient post-training. Our controlled study reveals that models instruction-tuned on short contexts can effectively generalize to longer ones, while also identifying other critical factors such as instruction difficulty and context composition. Based on these findings, we propose context synthesis, a novel data synthesis framework that leverages off-the-shelf LLMs to generate extended background contexts for high-quality instruction-answer pairs. Experiment results on the document-level benchmark (LongBench) demonstrate that our proposed approach outperforms previous instruction synthesis approaches and comes close to the performance of human-annotated long-context instruction data. The project will be available at: https://github.com/NJUNLP/context-synthesis.
BenchMAX: A Comprehensive Multilingual Evaluation Suite for Large Language Models
Feb 11, 2025Previous multilingual benchmarks focus primarily on simple understanding tasks, but for large language models(LLMs), we emphasize proficiency in instruction following, reasoning, long context understanding, code generation, and so on. However, measuring these advanced capabilities across languages is underexplored. To address the disparity, we introduce BenchMAX, a multi-way multilingual evaluation benchmark that allows for fair comparisons of these important abilities across languages. To maintain high quality, three distinct native-speaking annotators independently annotate each sample within all tasks after the data was machine-translated from English into 16 other languages. Additionally, we present a novel translation challenge stemming from dataset construction. Extensive experiments on BenchMAX reveal varying effectiveness of core capabilities across languages, highlighting performance gaps that cannot be bridged by simply scaling up model size. BenchMAX serves as a comprehensive multilingual evaluation platform, providing a promising test bed to promote the development of multilingual language models. The dataset and code are publicly accessible.
Multilingual Contrastive Decoding via Language-Agnostic Layers Skipping
Jul 15, 2024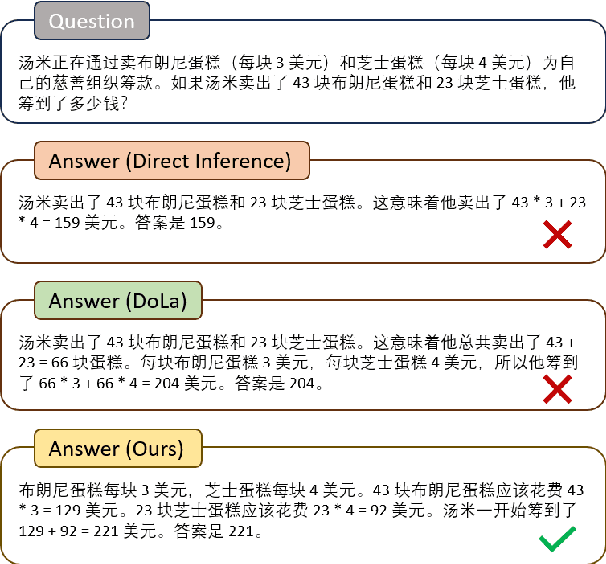
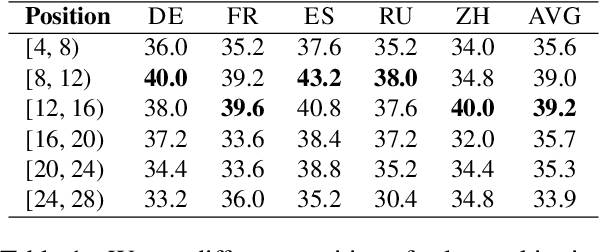
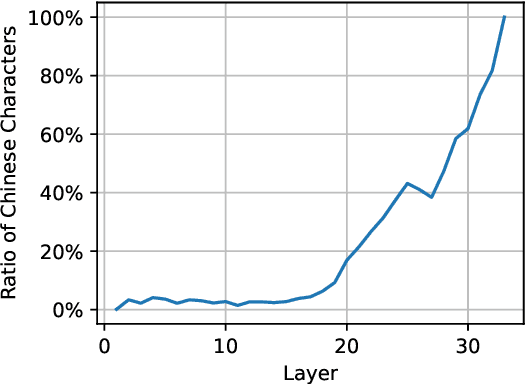
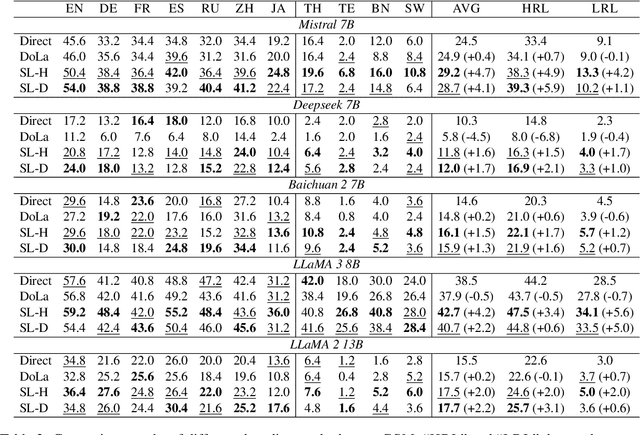
Decoding by contrasting layers (DoLa), is designed to improve the generation quality of large language models (LLMs) by contrasting the prediction probabilities between an early exit output (amateur logits) and the final output (expert logits). However, we find that this approach does not work well on non-English tasks. Inspired by previous interpretability work on language transition during the model's forward pass, we discover that this issue arises from a language mismatch between early exit output and final output. In this work, we propose an improved contrastive decoding algorithm that is effective for diverse languages beyond English. To obtain more helpful amateur logits, we devise two strategies to skip a set of bottom, language-agnostic layers based on our preliminary analysis. Experimental results on multilingual reasoning benchmarks demonstrate that our proposed method outperforms previous contrastive decoding baselines and substantially improves LLM's chain-of-thought reasoning accuracy across 11 languages. The project will be available at: https://github.com/NJUNLP/SkipLayerCD.