 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaMAX: Scaling Linguistic Horizons of LLM by Enhancing Translation Capabilities Beyond 100 Languages
Jul 08, 2024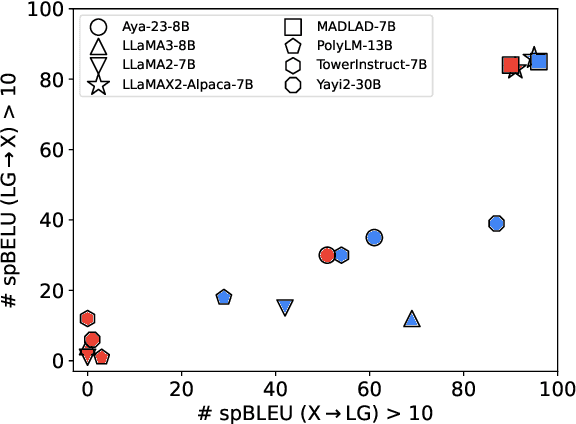
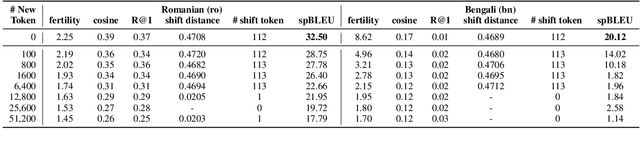
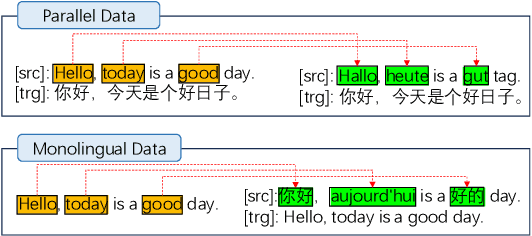
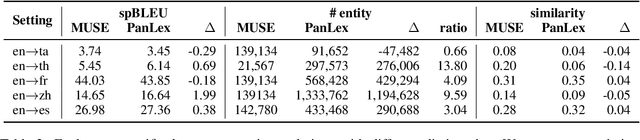
Large Language Models~(LLMs) demonstrate remarkable translation capabilities in high-resource language tasks, yet their performance in low-resource languages is hindered by insufficient multilingual data during pre-training. To address this, we dedicate 35,000 A100-SXM4-80GB GPU hours in conducting extensive multilingual continual pre-training on the LLaMA series models, enabling translation support across more than 100 languages. Through a comprehensive analysis of training strategies, such as vocabulary expansion and data augmentation, we develop LLaMAX. Remarkably, without sacrificing its generalization ability, LLaMAX achieves significantly higher translation performance compared to existing open-source LLMs~(by more than 10 spBLEU points) and performs on-par with specialized translation model~(M2M-100-12B) on the Flores-101 benchmark. Extensive experiments indicate that LLaMAX can serve as a robust multilingual foundation model. The code~\footnote{\url{https://github.com/CONE-MT/LLaMAX/.}} and models~\footnote{\url{https://huggingface.co/LLaMAX/.}} are publicly available.
Lego-MT: Towards Detachable Models in Massively Multilingual Machine Translation
Dec 20, 2022Traditional multilingual neural machine translation (MNMT) uses a single model to translate all directions. However, with the increasing scale of language pairs, simply using a single model for massive MNMT brings new challenges: parameter tension and large computations. In this paper, we revisit multi-way structures by assigning an individual branch for each language (group). Despite being a simple architecture, it is challenging to train de-centralized models due to the lack of constraints to align representations from all languages. We propose a localized training recipe to map different branches into a unified space, resulting in an efficient detachable model, Lego-MT. For a fair comparison, we collect data from OPUS and build the first large-scale open-source translation benchmark covering 7 language-centric data, each containing 445 language pairs. Experiments show that Lego-MT (1.2B) brings gains of more than 4 BLEU while outperforming M2M-100 (12B) (We will public all training data, models, and checkpoints)
KELM: Knowledge Enhanced Pre-Trained Language Representations with Message Passing on Hierarchical Relational Graphs
Sep 09, 2021


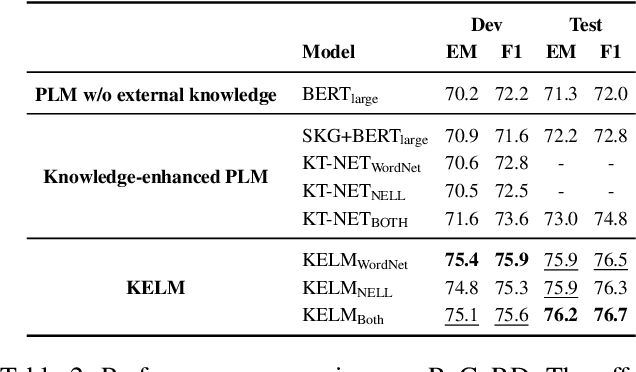
Incorporating factual knowledge into pre-trained language models (PLM) such as BERT is an emerging trend in recent NLP studies. However, most of the existing methods combine the external knowledge integration module with a modified pre-training loss and re-implement the pre-training process on the large-scale corpus. Re-pretraining these models is usually resource-consuming, and difficult to adapt to another domain with a different knowledge graph (KG). Besides, those works either cannot embed knowledge context dynamically according to textual context or struggle with the knowledge ambiguity issue. In this paper, we propose a novel knowledge-aware language model framework based on fine-tuning process, which equips PLM with a unified knowledge-enhanced text graph that contains both text and multi-relational sub-graphs extracted from KG. We design a hierarchical relational-graph-based message passing mechanism, which can allow the representations of injected KG and text to mutually update each other and can dynamically select ambiguous mentioned entities that share the same text. Our empirical results show that our model can efficiently incorporate world knowledge from KGs into existing language models such as BERT, and achieve significant improvement on the machine reading comprehension (MRC) task compared with other knowledge-enhanced models.