 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaMAX: Scaling Linguistic Horizons of LLM by Enhancing Translation Capabilities Beyond 100 Languages
Paper and Code
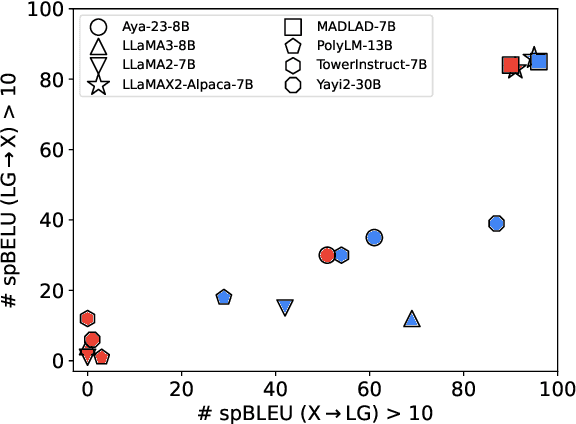
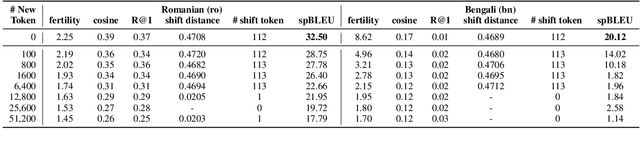
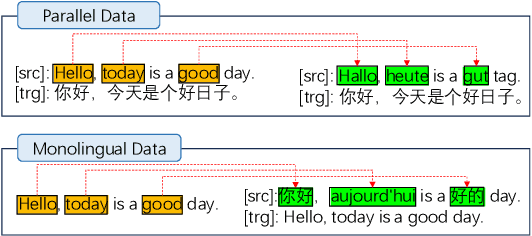
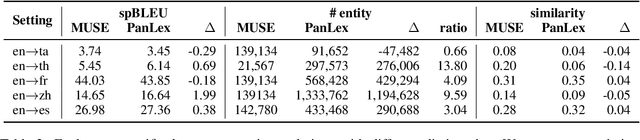
Large Language Models~(LLMs) demonstrate remarkable translation capabilities in high-resource language tasks, yet their performance in low-resource languages is hindered by insufficient multilingual data during pre-training. To address this, we dedicate 35,000 A100-SXM4-80GB GPU hours in conducting extensive multilingual continual pre-training on the LLaMA series models, enabling translation support across more than 100 languages. Through a comprehensive analysis of training strategies, such as vocabulary expansion and data augmentation, we develop LLaMAX. Remarkably, without sacrificing its generalization ability, LLaMAX achieves significantly higher translation performance compared to existing open-source LLMs~(by more than 10 spBLEU points) and performs on-par with specialized translation model~(M2M-100-12B) on the Flores-101 benchmark. Extensive experiments indicate that LLaMAX can serve as a robust multilingual foundation model. The code~\footnote{\url{https://github.com/CONE-MT/LLaMAX/.}} and models~\footnote{\url{https://huggingface.co/LLaMAX/.}} are publicly available.