 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Explanations for Recommendation with Rating and Feature via Maximizing Mutual Information
Jul 18, 2024
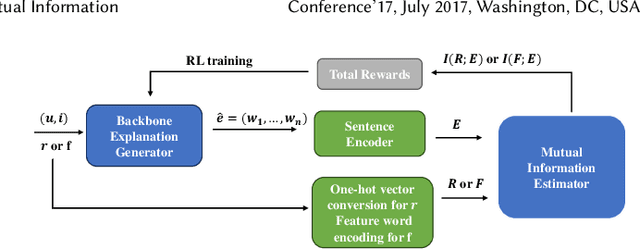
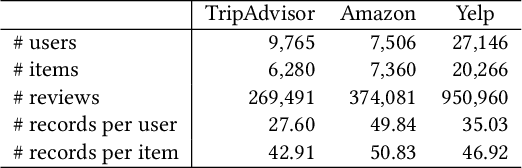
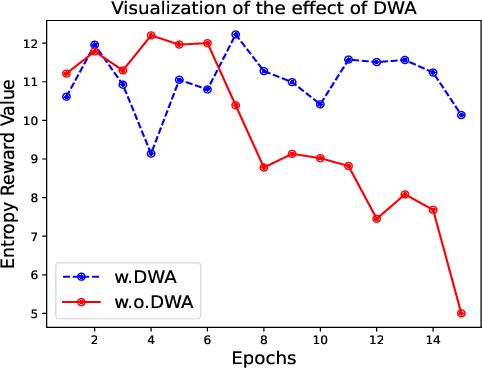
Providing natural language-based explanations to justify recommendations helps to improve users' satisfaction and gain users' trust. However, as current explanation generation methods are commonly trained with an objective to mimic existing user reviews, the generated explanations are often not aligned with the predicted ratings or some important features of the recommended items, and thus, are suboptimal in helping users make informed decision on the recommendation platform. To tackle this problem, we propose a flexible model-agnostic method named MMI (Maximizing Mutual Information) framework to enhance the alignment between the generated natural language explanations and the predicted rating/important item features. Specifically, we propose to use mutual information (MI) as a measure for the alignment and train a neural MI estimator. Then, we treat a well-trained explanation generation model as the backbone model and further fine-tune it through reinforcement learning with guidance from the MI estimator, which rewards a generated explanation that is more aligned with the predicted rating or a pre-defined feature of the recommended item. Experiments on three datasets demonstrate that our MMI framework can boost different backbone models, enabling them to outperform existing baselines in terms of alignment with predicted ratings and item features. Additionally, user studies verify that MI-enhanced explanations indeed facilitate users' decisions and are favorable compared with other baselines due to their better alignment properties.
RNE: A Scalable Network Embedding for Billion-scale Recommendation
Apr 09, 2020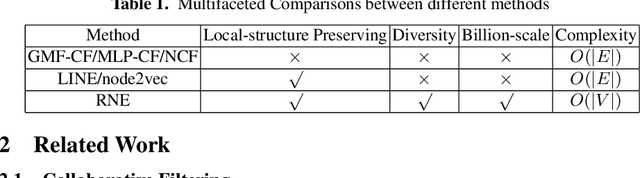
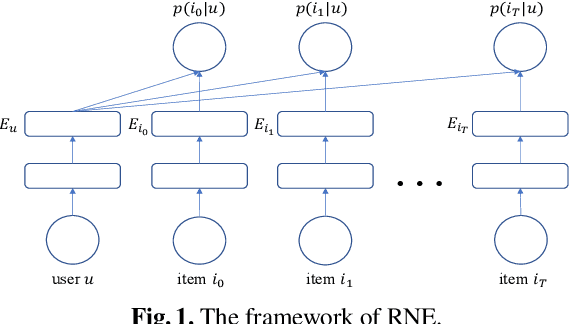


Nowadays designing a real recommendation system has been a critical problem for both academic and industry. However, due to the huge number of users and items, the diversity and dynamic property of the user interest, how to design a scalable recommendation system, which is able to efficiently produce effective and diverse recommendation results on billion-scale scenarios, is still a challenging and open problem for existing methods. In this paper, given the user-item interaction graph, we propose RNE, a data-efficient Recommendation-based Network Embedding method, to give personalized and diverse items to users. Specifically, we propose a diversity- and dynamics-aware neighbor sampling method for network embedding. On the one hand, the method is able to preserve the local structure between the users and items while modeling the diversity and dynamic property of the user interest to boost the recommendation quality. On the other hand the sampling method can reduce the complexity of the whole method theoretically to make it possible for billion-scale recommendation. We also implement the designed algorithm in a distributed way to further improves its scalability. Experimentally, we deploy RNE on a recommendation scenario of Taobao, the largest E-commerce platform in China, and train it on a billion-scale user-item graph. As is shown on several online metrics on A/B testing, RNE is able to achieve both high-quality and diverse results compared with CF-based methods. We also conduct the offline experiments on Pinterest dataset comparing with several state-of-the-art recommendation methods and network embedding methods. The results demonstrate that our method is able to produce a good result while runs much faster than the baseline methods.
Diversity-Promoting Deep Reinforcement Learning for Interactive Recommendation
Mar 19, 2019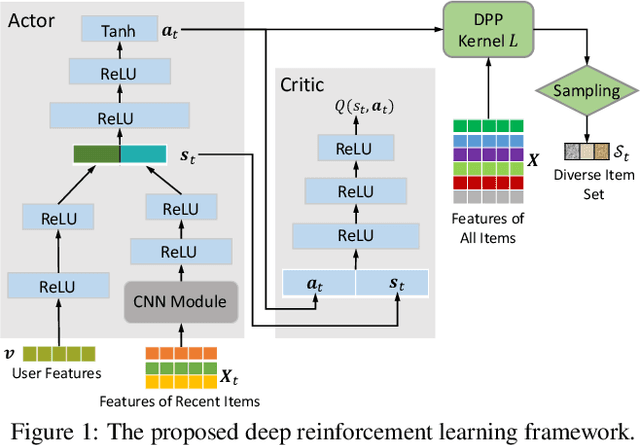

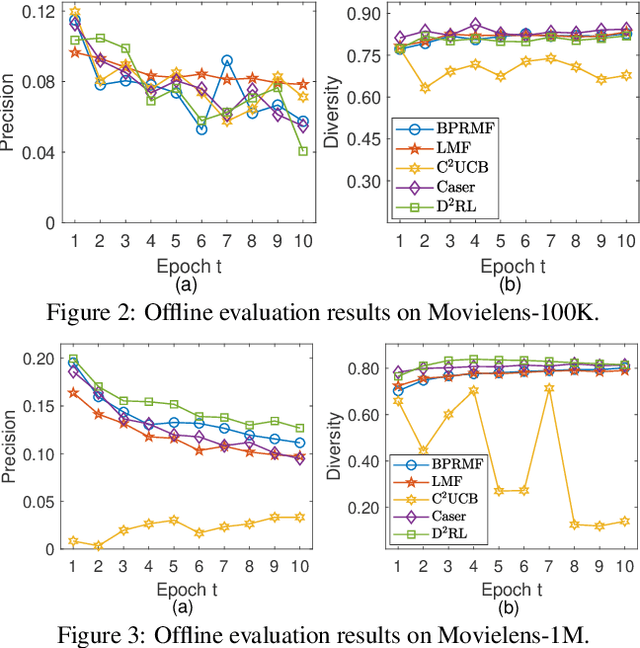
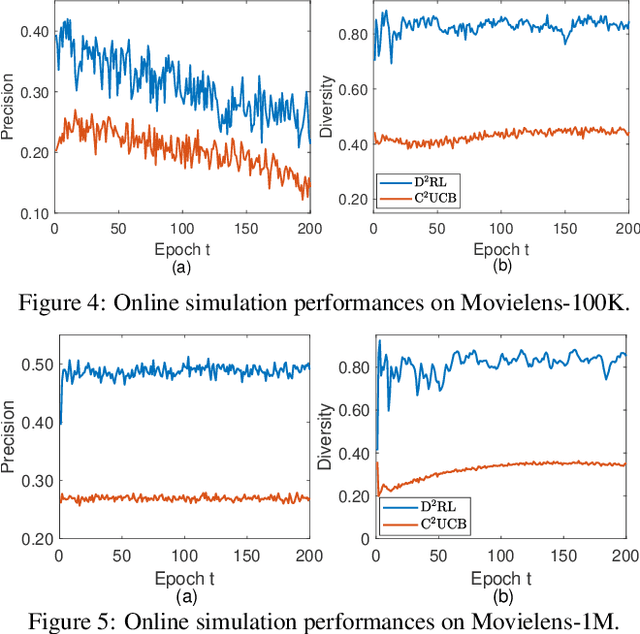
Interactive recommendation that models the explicit interactions between users and the recommender system has attracted a lot of research attentions in recent years. Most previous interactive recommendation systems only focus on optimizing recommendation accuracy while overlooking other important aspects of recommendation quality, such as the diversity of recommendation results. In this paper, we propose a novel recommendation model, named \underline{D}iversity-promoting \underline{D}eep \underline{R}einforcement \underline{L}earning (D$^2$RL), which encourages the diversity of recommendation results in interaction recommendations. More specifically, we adopt a Determinantal Point Process (DPP) model to generate diverse, while relevant item recommendations. A personalized DPP kernel matrix is maintained for each user, which is constructed from two parts: a fixed similarity matrix capturing item-item similarity, and the relevance of items dynamically learnt through an actor-critic reinforcement learning framework. We performed extensive offline experiments as well as simulated online experiments with real world datasets to demonstrate the effectiveness of the proposed model.