 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing CTR Prediction through Sequential Recommendation Pre-training: Introducing the SRP4CTR Framework
Jul 29, 2024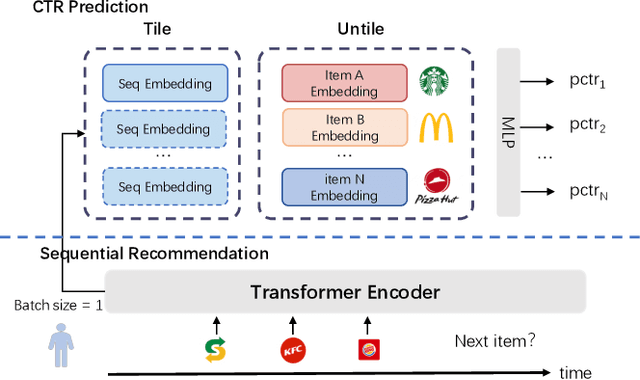
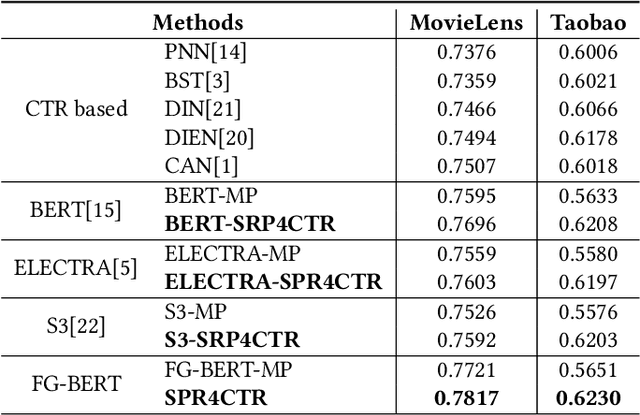
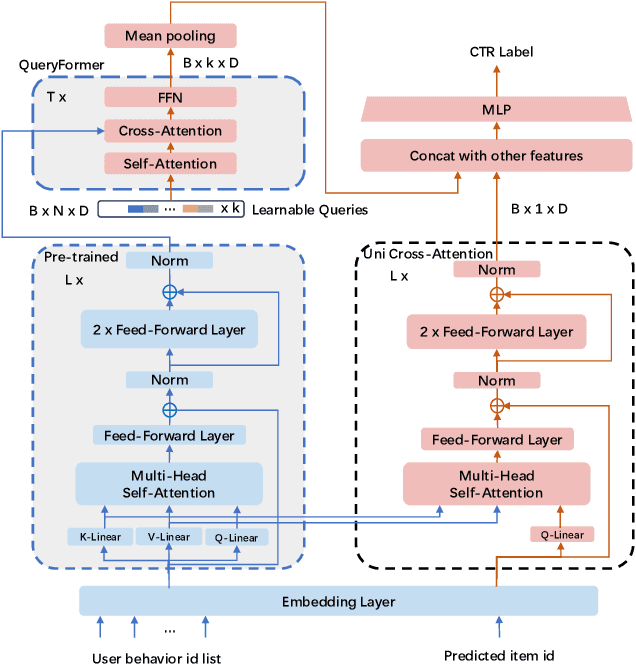
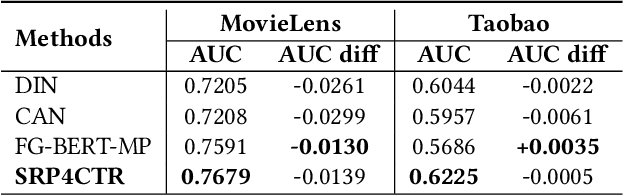
Understanding user interests is crucial for Click-Through Rate (CTR) prediction tasks. In sequential recommendation, pre-training from user historical behaviors through self-supervised learning can better comprehend user dynamic preferences, presenting the potential for direct integration with CTR tasks. Previous methods have integrated pre-trained models into downstream tasks with the sole purpose of extracting semantic information or well-represented user features, which are then incorporated as new features. However, these approaches tend to ignore the additional inference costs to the downstream tasks, and they do not consider how to transfer the effective information from the pre-trained models for specific estimated items in CTR prediction. In this paper, we propose a Sequential Recommendation Pre-training framework for CTR prediction (SRP4CTR) to tackle the above problems. Initially, we discuss the impact of introducing pre-trained models on inference costs. Subsequently, we introduced a pre-trained method to encode sequence side information concurrently.During the fine-tuning process, we incorporate a cross-attention block to establish a bridge between estimated items and the pre-trained model at a low cost. Moreover, we develop a querying transformer technique to facilitate the knowledge transfer from the pre-trained model to industrial CTR models. Offline and online experiments show that our method outperforms previous baseline models.
Aligning Explanations for Recommendation with Rating and Feature via Maximizing Mutual Information
Jul 18, 2024
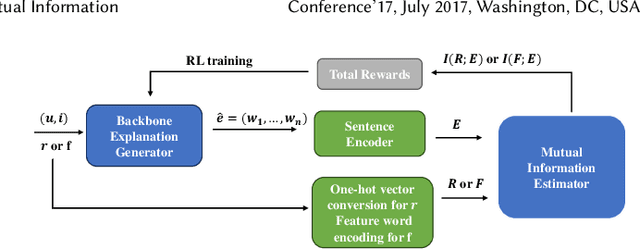
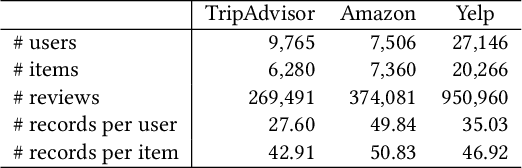
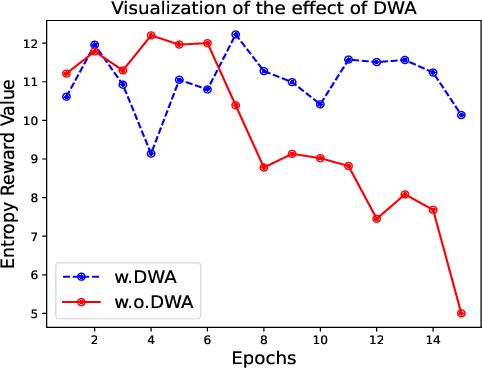
Providing natural language-based explanations to justify recommendations helps to improve users' satisfaction and gain users' trust. However, as current explanation generation methods are commonly trained with an objective to mimic existing user reviews, the generated explanations are often not aligned with the predicted ratings or some important features of the recommended items, and thus, are suboptimal in helping users make informed decision on the recommendation platform. To tackle this problem, we propose a flexible model-agnostic method named MMI (Maximizing Mutual Information) framework to enhance the alignment between the generated natural language explanations and the predicted rating/important item features. Specifically, we propose to use mutual information (MI) as a measure for the alignment and train a neural MI estimator. Then, we treat a well-trained explanation generation model as the backbone model and further fine-tune it through reinforcement learning with guidance from the MI estimator, which rewards a generated explanation that is more aligned with the predicted rating or a pre-defined feature of the recommended item. Experiments on three datasets demonstrate that our MMI framework can boost different backbone models, enabling them to outperform existing baselines in terms of alignment with predicted ratings and item features. Additionally, user studies verify that MI-enhanced explanations indeed facilitate users' decisions and are favorable compared with other baselines due to their better alignment properties.