 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Assembly: Semi-Supervised Multi-Task Learning from Multiple Datasets with Disjoint Labels
Jun 15, 2023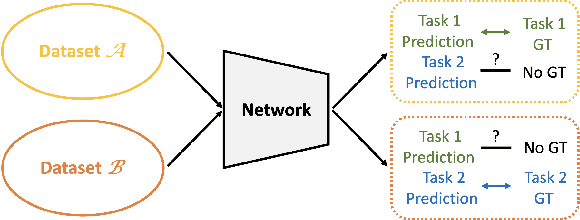



In real-world scenarios we often need to perform multiple tasks simultaneously. Multi-Task Learning (MTL) is an adequate method to do so, but usually requires datasets labeled for all tasks. We propose a method that can leverage datasets labeled for only some of the tasks in the MTL framework. Our work, Knowledge Assembly (KA), learns multiple tasks from disjoint datasets by leveraging the unlabeled data in a semi-supervised manner, using model augmentation for pseudo-supervision. Whilst KA can be implemented on any existing MTL networks, we test our method on jointly learning person re-identification (reID) and pedestrian attribute recognition (PAR). We surpass the single task fully-supervised performance by $4.2\%$ points for reID and $0.9\%$ points for PAR.
Booster-SHOT: Boosting Stacked Homography Transformations for Multiview Pedestrian Detection with Attention
Aug 19, 2022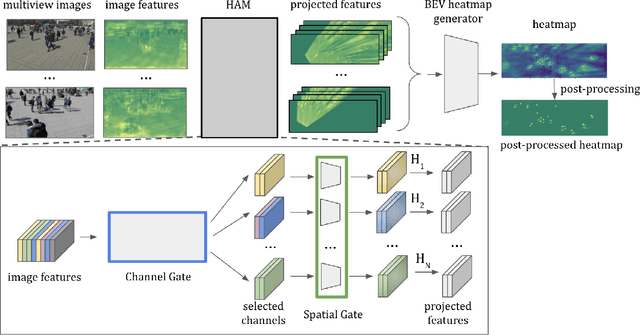
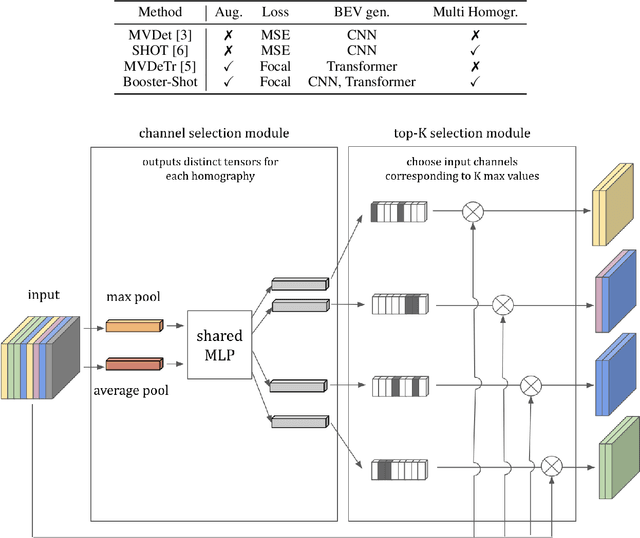
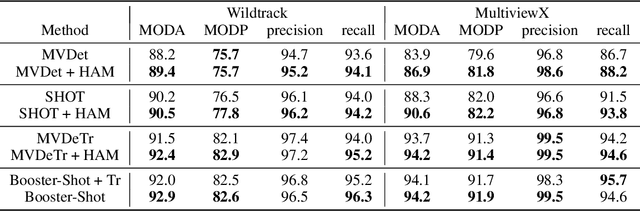
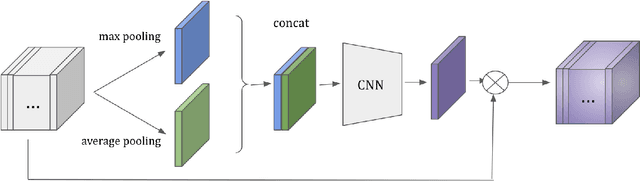
Improving multi-view aggregation is integral for multi-view pedestrian detection, which aims to obtain a bird's-eye-view pedestrian occupancy map from images captured through a set of calibrated cameras. Inspired by the success of attention modules for deep neural networks, we first propose a Homography Attention Module (HAM) which is shown to boost the performance of existing end-to-end multiview detection approaches by utilizing a novel channel gate and spatial gate. Additionally, we propose Booster-SHOT, an end-to-end convolutional approach to multiview pedestrian detection incorporating our proposed HAM as well as elements from previous approaches such as view-coherent augmentation or stacked homography transformations. Booster-SHOT achieves 92.9% and 94.2% for MODA on Wildtrack and MultiviewX respectively, outperforming the state-of-the-art by 1.4% on Wildtrack and 0.5% on MultiviewX, achieving state-of-the-art performance overall for standard evaluation metrics used in multi-view pedestrian detection.
Privacy Safe Representation Learning via Frequency Filtering Encoder
Aug 04, 2022

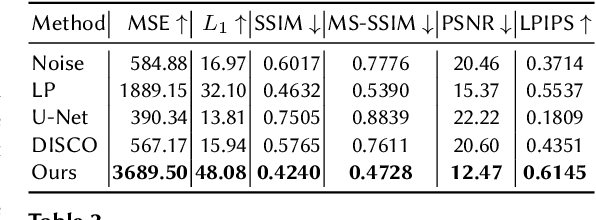
Deep learning models are increasingly deployed in real-world applications. These models are often deployed on the server-side and receive user data in an information-rich representation to solve a specific task, such as image classification. Since images can contain sensitive information, which users might not be willing to share, privacy protection becomes increasingly important. Adversarial Representation Learning (ARL) is a common approach to train an encoder that runs on the client-side and obfuscates an image. It is assumed, that the obfuscated image can safely be transmitted and used for the task on the server without privacy concerns. However, in this work, we find that training a reconstruction attacker can successfully recover the original image of existing ARL methods. To this end, we introduce a novel ARL method enhanced through low-pass filtering, limiting the available information amount to be encoded in the frequency domain. Our experimental results reveal that our approach withstands reconstruction attacks while outperforming previous state-of-the-art methods regarding the privacy-utility trade-off. We further conduct a user study to qualitatively assess our defense of the reconstruction attack.
Investigating Top-$k$ White-Box and Transferable Black-box Attack
Mar 30, 2022
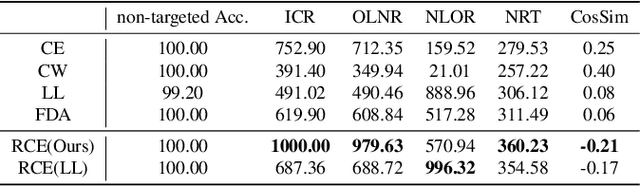


Existing works have identified the limitation of top-$1$ attack success rate (ASR) as a metric to evaluate the attack strength but exclusively investigated it in the white-box setting, while our work extends it to a more practical black-box setting: transferable attack. It is widely reported that stronger I-FGSM transfers worse than simple FGSM, leading to a popular belief that transferability is at odds with the white-box attack strength. Our work challenges this belief with empirical finding that stronger attack actually transfers better for the general top-$k$ ASR indicated by the interest class rank (ICR) after attack. For increasing the attack strength, with an intuitive interpretation of the logit gradient from the geometric perspective, we identify that the weakness of the commonly used losses lie in prioritizing the speed to fool the network instead of maximizing its strength. To this end, we propose a new normalized CE loss that guides the logit to be updated in the direction of implicitly maximizing its rank distance from the ground-truth class. Extensive results in various settings have verified that our proposed new loss is simple yet effective for top-$k$ attack. Code is available at: \url{https://bit.ly/3uCiomP}
Adversarial Robustness Comparison of Vision Transformer and MLP-Mixer to CNNs
Oct 11, 2021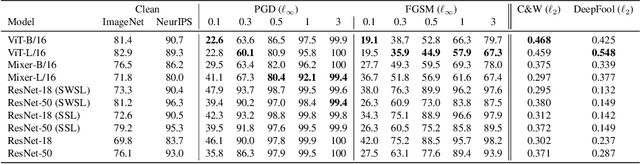


Convolutional Neural Networks (CNNs) have become the de facto gold standard in computer vision applications in the past years. Recently, however, new model architectures have been proposed challenging the status quo. The Vision Transformer (ViT) relies solely on attention modules, while the MLP-Mixer architecture substitutes the self-attention modules with Multi-Layer Perceptrons (MLPs). Despite their great success, CNNs have been widely known to be vulnerable to adversarial attacks, causing serious concerns for security-sensitive applications. Thus, it is critical for the community to know whether the newly proposed ViT and MLP-Mixer are also vulnerable to adversarial attacks. To this end, we empirically evaluate their adversarial robustness under several adversarial attack setups and benchmark them against the widely used CNNs. Overall, we find that the two architectures, especially ViT, are more robust than their CNN models. Using a toy example, we also provide empirical evidence that the lower adversarial robustness of CNNs can be partially attributed to their shift-invariant property. Our frequency analysis suggests that the most robust ViT architectures tend to rely more on low-frequency features compared with CNNs. Additionally, we have an intriguing finding that MLP-Mixer is extremely vulnerable to universal adversarial perturbations.
Universal Adversarial Training with Class-Wise Perturbations
Apr 07, 2021
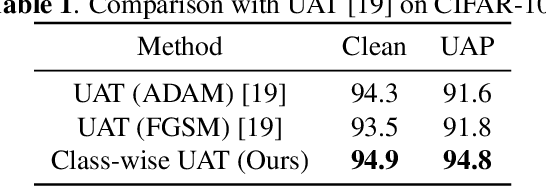

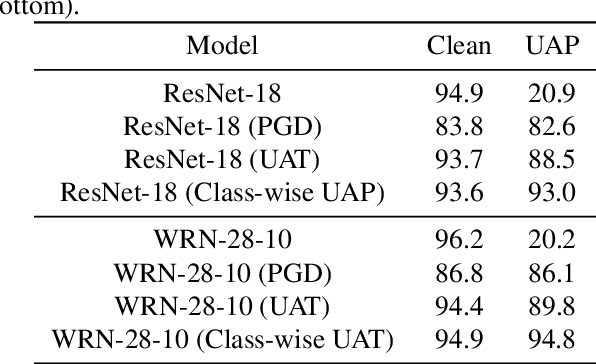
Despite their overwhelming success on a wide range of applications, convolutional neural networks (CNNs) are widely recognized to be vulnerable to adversarial examples. This intriguing phenomenon led to a competition between adversarial attacks and defense techniques. So far, adversarial training is the most widely used method for defending against adversarial attacks. It has also been extended to defend against universal adversarial perturbations (UAPs). The SOTA universal adversarial training (UAT) method optimizes a single perturbation for all training samples in the mini-batch. In this work, we find that a UAP does not attack all classes equally. Inspired by this observation, we identify it as the source of the model having unbalanced robustness. To this end, we improve the SOTA UAT by proposing to utilize class-wise UAPs during adversarial training. On multiple benchmark datasets, our class-wise UAT leads superior performance for both clean accuracy and adversarial robustness against universal attack.
A Brief Survey on Deep Learning Based Data Hiding, Steganography and Watermarking
Mar 02, 2021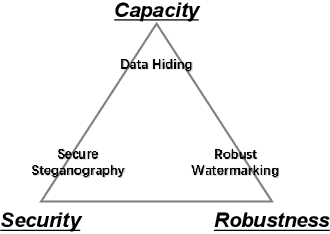
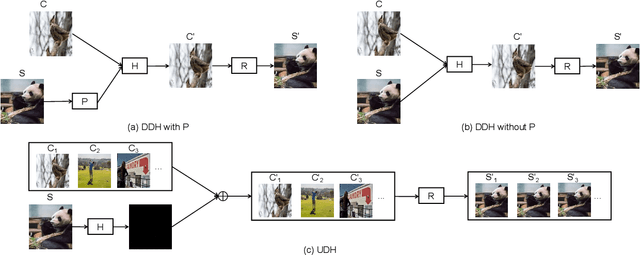
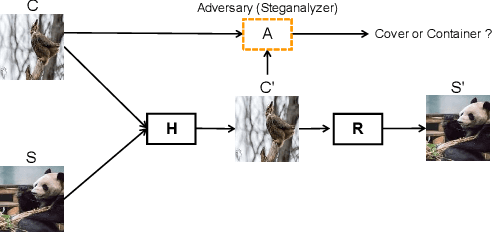
Data hiding is the art of concealing messages with limited perceptual changes. Recently, deep learning has provided enriching perspectives for it and made significant progress. In this work, we conduct a brief yet comprehensive review of existing literature and outline three meta-architectures. Based on this, we summarize specific strategies for various applications of deep hiding, including steganography, light field messaging and watermarking. Finally, further insight into deep hiding is provided through incorporating the perspective of adversarial attack.
A Survey On Universal Adversarial Attack
Mar 02, 2021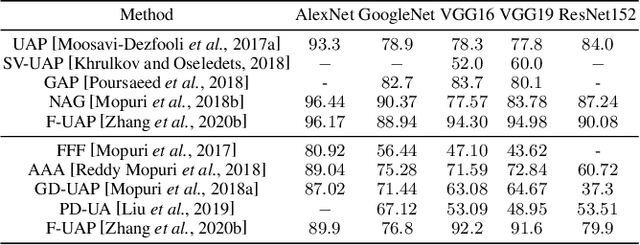
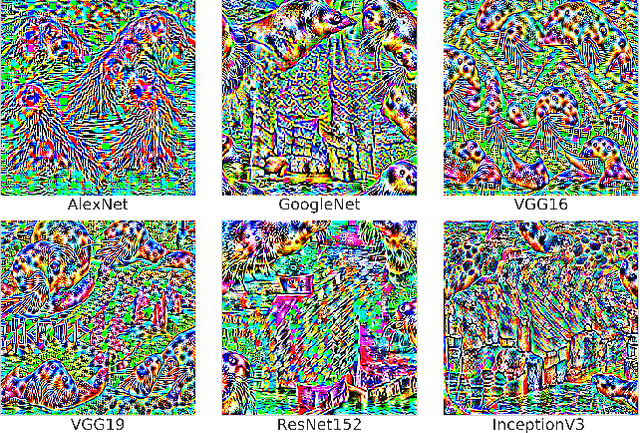
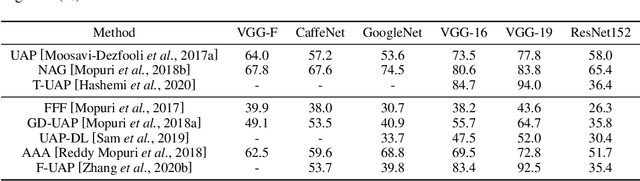
Deep neural networks (DNNs) have demonstrated remarkable performance for various applications, meanwhile, they are widely known to be vulnerable to the attack of adversarial perturbations. This intriguing phenomenon has attracted significant attention in machine learning and what might be more surprising to the community is the existence of universal adversarial perturbations (UAPs), i.e. a single perturbation to fool the target DNN for most images. The advantage of UAP is that it can be generated beforehand and then be applied on-the-fly during the attack. With the focus on UAP against deep classifiers, this survey summarizes the recent progress on universal adversarial attacks, discussing the challenges from both the attack and defense sides, as well as the reason for the existence of UAP. Additionally, universal attacks in a wide range of applications beyond deep classification are also covered.
Universal Adversarial Perturbations Through the Lens of Deep Steganography: Towards A Fourier Perspective
Feb 12, 2021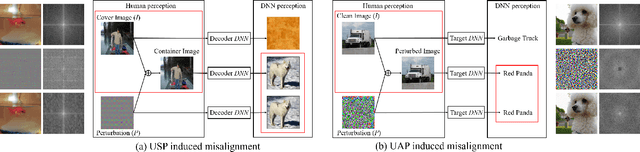

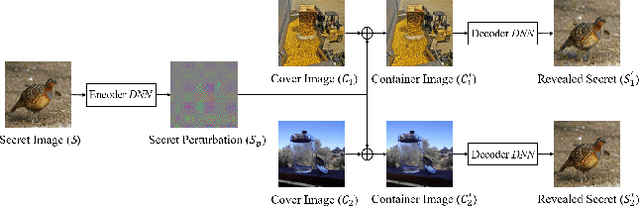

The booming interest in adversarial attacks stems from a misalignment between human vision and a deep neural network (DNN), i.e. a human imperceptible perturbation fools the DNN. Moreover, a single perturbation, often called universal adversarial perturbation (UAP), can be generated to fool the DNN for most images. A similar misalignment phenomenon has recently also been observed in the deep steganography task, where a decoder network can retrieve a secret image back from a slightly perturbed cover image. We attempt explaining the success of both in a unified manner from the Fourier perspective. We perform task-specific and joint analysis and reveal that (a) frequency is a key factor that influences their performance based on the proposed entropy metric for quantifying the frequency distribution; (b) their success can be attributed to a DNN being highly sensitive to high-frequency content. We also perform feature layer analysis for providing deep insight on model generalization and robustness. Additionally, we propose two new variants of universal perturbations: (1) Universal Secret Adversarial Perturbation (USAP) that simultaneously achieves attack and hiding; (2) high-pass UAP (HP-UAP) that is less visible to the human eye.
Towards Robust Data Hiding Against (JPEG) Compression: A Pseudo-Differentiable Deep Learning Approach
Dec 30, 2020
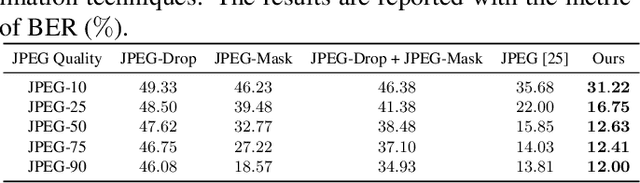
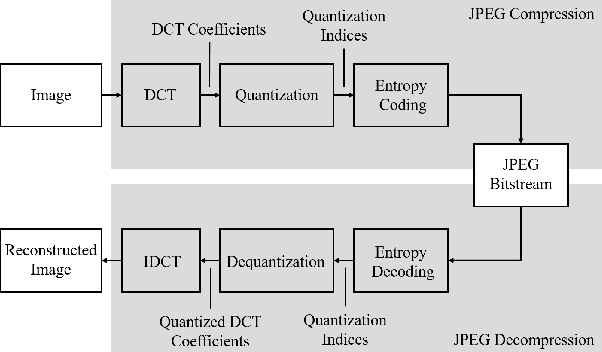

Data hiding is one widely used approach for protecting authentication and ownership. Most multimedia content like images and videos are transmitted or saved in the compressed form. This kind of lossy compression, such as JPEG, can destroy the hidden data, which raises the need of robust data hiding. It is still an open challenge to achieve the goal of data hiding that can be against these compressions. Recently, deep learning has shown large success in data hiding, while non-differentiability of JPEG makes it challenging to train a deep pipeline for improving robustness against lossy compression. The existing SOTA approaches replace the non-differentiable parts with differentiable modules that perform similar operations. Multiple limitations exist: (a) large engineering effort; (b) requiring a white-box knowledge of compression attacks; (c) only works for simple compression like JPEG. In this work, we propose a simple yet effective approach to address all the above limitations at once. Beyond JPEG, our approach has been shown to improve robustness against various image and video lossy compression algorithms.