 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Sequence-Level Training for Visual Tracking
Aug 11, 2022
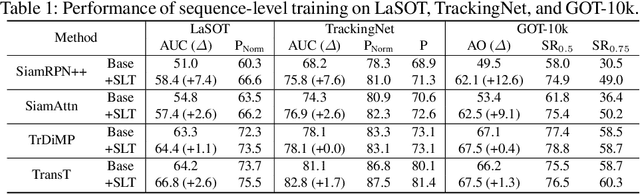
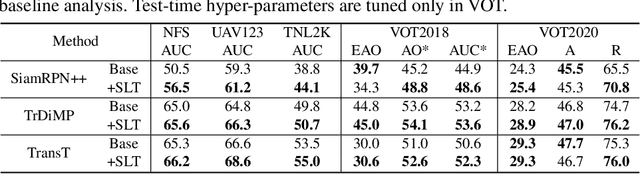

Despite the extensive adoption of machine learning on the task of visual object tracking, recent learning-based approaches have largely overlooked the fact that visual tracking is a sequence-level task in its nature; they rely heavily on frame-level training, which inevitably induces inconsistency between training and testing in terms of both data distributions and task objectives. This work introduces a sequence-level training strategy for visual tracking based on reinforcement learning and discusses how a sequence-level design of data sampling, learning objectives, and data augmentation can improve the accuracy and robustness of tracking algorithms. Our experiments on standard benchmarks including LaSOT, TrackingNet, and GOT-10k demonstrate that four representative tracking models, SiamRPN++, SiamAttn, TransT, and TrDiMP, consistently improve by incorporating the proposed methods in training without modifying architectures.
Privacy Safe Representation Learning via Frequency Filtering Encoder
Aug 04, 2022
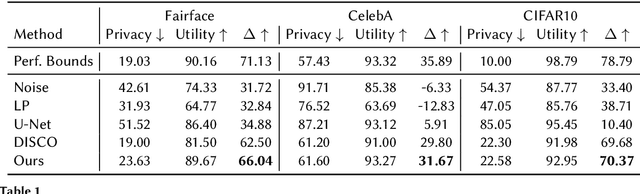

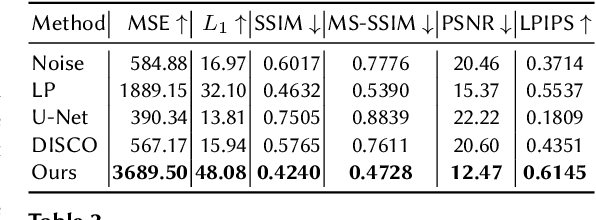
Deep learning models are increasingly deployed in real-world applications. These models are often deployed on the server-side and receive user data in an information-rich representation to solve a specific task, such as image classification. Since images can contain sensitive information, which users might not be willing to share, privacy protection becomes increasingly important. Adversarial Representation Learning (ARL) is a common approach to train an encoder that runs on the client-side and obfuscates an image. It is assumed, that the obfuscated image can safely be transmitted and used for the task on the server without privacy concerns. However, in this work, we find that training a reconstruction attacker can successfully recover the original image of existing ARL methods. To this end, we introduce a novel ARL method enhanced through low-pass filtering, limiting the available information amount to be encoded in the frequency domain. Our experimental results reveal that our approach withstands reconstruction attacks while outperforming previous state-of-the-art methods regarding the privacy-utility trade-off. We further conduct a user study to qualitatively assess our defense of the reconstruction attack.
Universal Bounding Box Regression and Its Applications
Apr 15, 2019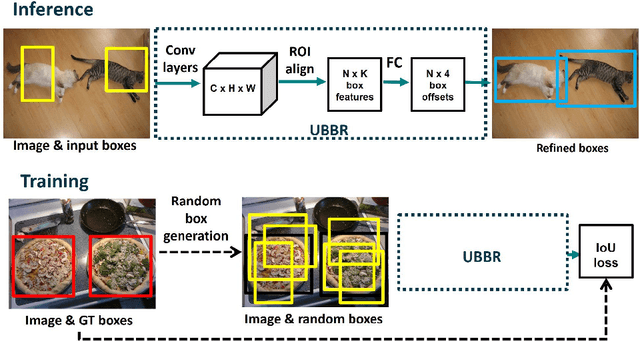


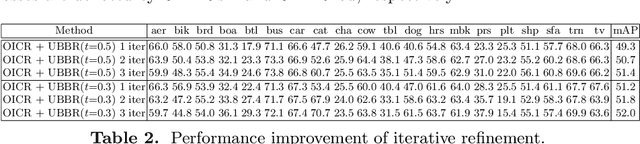
Bounding-box regression is a popular technique to refine or predict localization boxes in recent object detection approaches. Typically, bounding-box regressors are trained to regress from either region proposals or fixed anchor boxes to nearby bounding boxes of a pre-defined target object classes. This paper investigates whether the technique is generalizable to unseen classes and is transferable to other tasks beyond supervised object detection. To this end, we propose a class-agnostic and anchor-free box regressor, dubbed Universal Bounding-Box Regressor (UBBR), which predicts a bounding box of the nearest object from any given box. Trained on a relatively small set of annotated images, UBBR successfully generalizes to unseen classes, and can be used to improve localization in many vision problems. We demonstrate its effectivenss on weakly supervised object detection and object discovery.