 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Lumigraph Rendering
Mar 22, 2021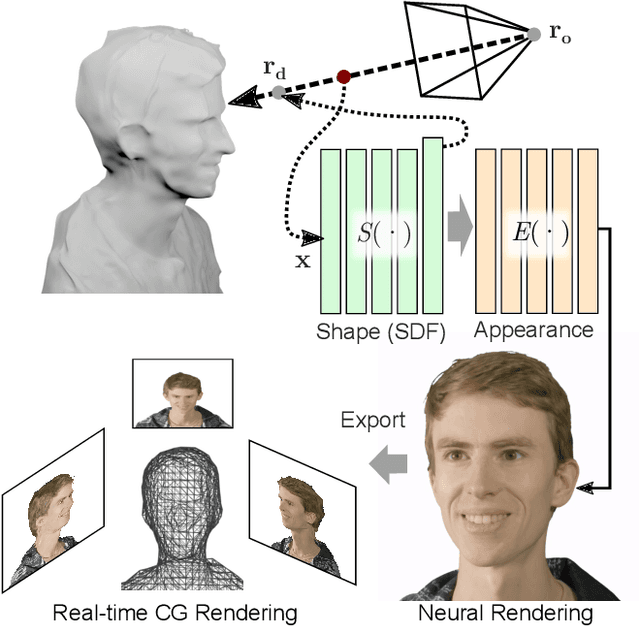


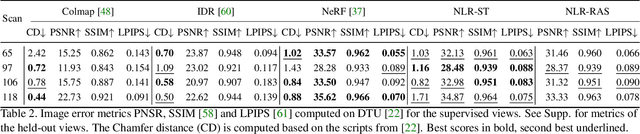
Novel view synthesis is a challenging and ill-posed inverse rendering problem. Neural rendering techniques have recently achieved photorealistic image quality for this task. State-of-the-art (SOTA) neural volume rendering approaches, however, are slow to train and require minutes of inference (i.e., rendering) time for high image resolutions. We adopt high-capacity neural scene representations with periodic activations for jointly optimizing an implicit surface and a radiance field of a scene supervised exclusively with posed 2D images. Our neural rendering pipeline accelerates SOTA neural volume rendering by about two orders of magnitude and our implicit surface representation is unique in allowing us to export a mesh with view-dependent texture information. Thus, like other implicit surface representations, ours is compatible with traditional graphics pipelines, enabling real-time rendering rates, while achieving unprecedented image quality compared to other surface methods. We assess the quality of our approach using existing datasets as well as high-quality 3D face data captured with a custom multi-camera rig.
Training with the Invisibles: Obfuscating Images to Share Safely for Learning Visual Recognition Models
Jan 01, 2019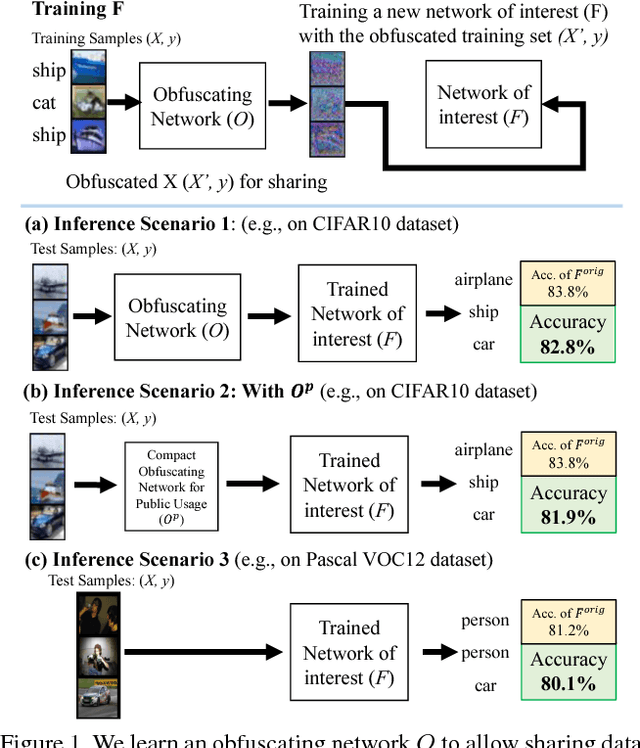


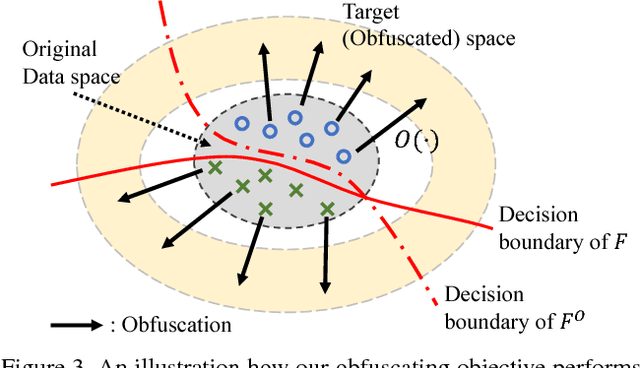
High-performance visual recognition systems generally require a large collection of labeled images to train. The expensive data curation can be an obstacle for improving recognition performance. Sharing more data allows training for better models. But personal and private information in the data prevent such sharing. To promote sharing visual data for learning a recognition model, we propose to obfuscate the images so that humans are not able to recognize their detailed contents, while machines can still utilize them to train new models. We validate our approach by comprehensive experiments on three challenging visual recognition tasks; image classification, attribute classification, and facial landmark detection on several datasets including SVHN, CIFAR10, Pascal VOC 2012, CelebA, and MTFL. Our method successfully obfuscates the images from humans recognition, but a machine model trained with them performs within about 1% margin (up to 0.48%) of the performance of a model trained with the original, non-obfuscated data.
Locally Non-rigid Registration for Mobile HDR Photography
May 05, 2015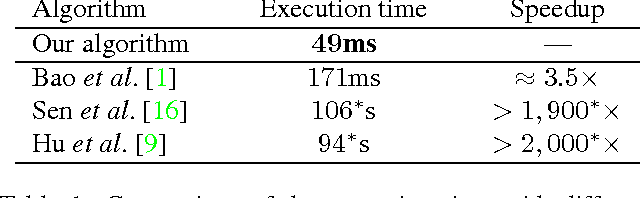



Image registration for stack-based HDR photography is challenging. If not properly accounted for, camera motion and scene changes result in artifacts in the composite image. Unfortunately, existing methods to address this problem are either accurate, but too slow for mobile devices, or fast, but prone to failing. We propose a method that fills this void: our approach is extremely fast---under 700ms on a commercial tablet for a pair of 5MP images---and prevents the artifacts that arise from insufficient registration quality.