 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Attributed Dynamic Network Embedding with Stability Guarantees
Mar 04, 2025Stability for dynamic network embeddings ensures that nodes behaving the same at different times receive the same embedding, allowing comparison of nodes in the network across time. We present attributed unfolded adjacency spectral embedding (AUASE), a stable unsupervised representation learning framework for dynamic networks in which nodes are attributed with time-varying covariate information. To establish stability, we prove uniform convergence to an associated latent position model. We quantify the benefits of our dynamic embedding by comparing with state-of-the-art network representation learning methods on three real attributed networks. To the best of our knowledge, AUASE is the only attributed dynamic embedding that satisfies stability guarantees without the need for ground truth labels, which we demonstrate provides significant improvements for link prediction and node classification.
Kernel Density Bayesian Inverse Reinforcement Learning
Mar 13, 2023Inverse reinforcement learning~(IRL) is a powerful framework to infer an agent's reward function by observing its behavior, but IRL algorithms that learn point estimates of the reward function can be misleading because there may be several functions that describe an agent's behavior equally well. A Bayesian approach to IRL models a distribution over candidate reward functions, alleviating the shortcomings of learning a point estimate. However, several Bayesian IRL algorithms use a $Q$-value function in place of the likelihood function. The resulting posterior is computationally intensive to calculate, has few theoretical guarantees, and the $Q$-value function is often a poor approximation for the likelihood. We introduce kernel density Bayesian IRL (KD-BIRL), which uses conditional kernel density estimation to directly approximate the likelihood, providing an efficient framework that, with a modified reward function parameterization, is applicable to environments with complex and infinite state spaces. We demonstrate KD-BIRL's benefits through a series of experiments in Gridworld environments and a simulated sepsis treatment task.
Nested Policy Reinforcement Learning
Oct 06, 2021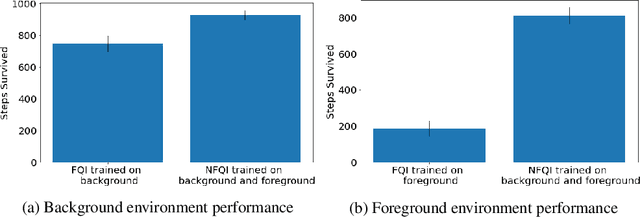

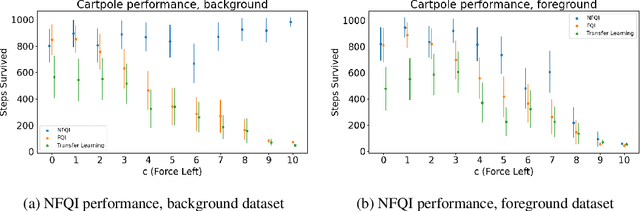

Off-policy reinforcement learning (RL) has proven to be a powerful framework for guiding agents' actions in environments with stochastic rewards and unknown or noisy state dynamics. In many real-world settings, these agents must operate in multiple environments, each with slightly different dynamics. For example, we may be interested in developing policies to guide medical treatment for patients with and without a given disease, or policies to navigate curriculum design for students with and without a learning disability. Here, we introduce nested policy fitted Q-iteration (NFQI), an RL framework that finds optimal policies in environments that exhibit such a structure. Our approach develops a nested $Q$-value function that takes advantage of the shared structure between two groups of observations from two separate environments while allowing their policies to be distinct from one another. We find that NFQI yields policies that rely on relevant features and perform at least as well as a policy that does not consider group structure. We demonstrate NFQI's performance using an OpenAI Gym environment and a clinical decision making RL task. Our results suggest that NFQI can develop policies that are better suited to many real-world clinical environments.
Spectral embedding for dynamic networks with stability guarantees
Jun 02, 2021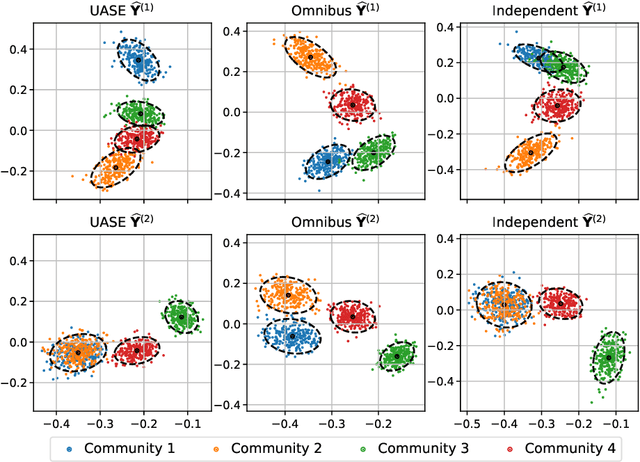
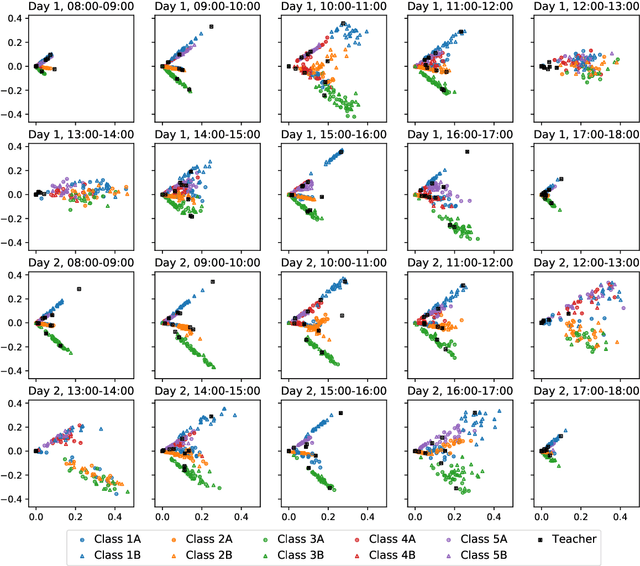
We consider the problem of embedding a dynamic network, to obtain time-evolving vector representations of each node, which can then be used to describe the changes in behaviour of a single node, one or more communities, or the entire graph. Given this open-ended remit, we wish to guarantee stability in the spatio-temporal positioning of the nodes: assigning the same position, up to noise, to nodes behaving similarly at a given time (cross-sectional stability) and a constant position, up to noise, to a single node behaving similarly across different times (longitudinal stability). These properties are defined formally within a generic dynamic latent position model. By showing how this model can be recast as a multilayer random dot product graph, we demonstrate that unfolded adjacency spectral embedding satisfies both stability conditions, allowing, for example, spatio-temporal clustering under the dynamic stochastic block model. We also show how alternative methods, such as omnibus, independent or time-averaged spectral embedding, lack one or the other form of stability.
Neural Lumigraph Rendering
Mar 22, 2021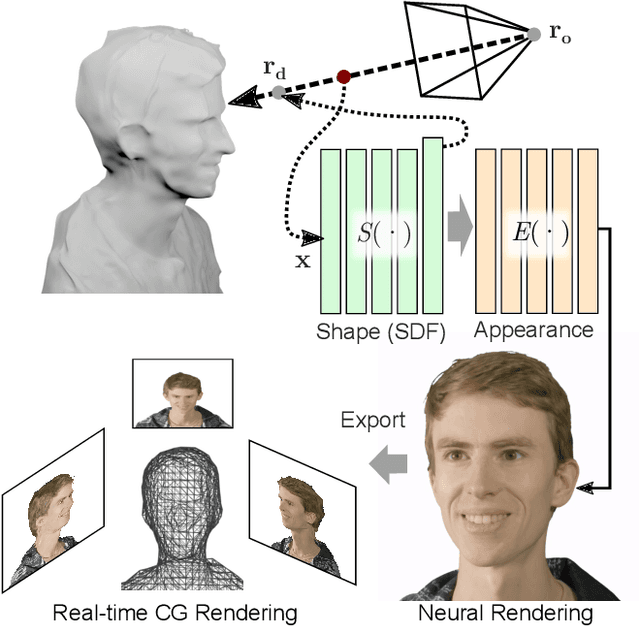


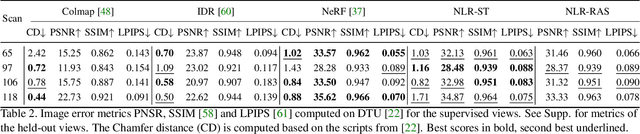
Novel view synthesis is a challenging and ill-posed inverse rendering problem. Neural rendering techniques have recently achieved photorealistic image quality for this task. State-of-the-art (SOTA) neural volume rendering approaches, however, are slow to train and require minutes of inference (i.e., rendering) time for high image resolutions. We adopt high-capacity neural scene representations with periodic activations for jointly optimizing an implicit surface and a radiance field of a scene supervised exclusively with posed 2D images. Our neural rendering pipeline accelerates SOTA neural volume rendering by about two orders of magnitude and our implicit surface representation is unique in allowing us to export a mesh with view-dependent texture information. Thus, like other implicit surface representations, ours is compatible with traditional graphics pipelines, enabling real-time rendering rates, while achieving unprecedented image quality compared to other surface methods. We assess the quality of our approach using existing datasets as well as high-quality 3D face data captured with a custom multi-camera rig.
Probabilistic Contrastive Principal Component Analysis
Dec 14, 2020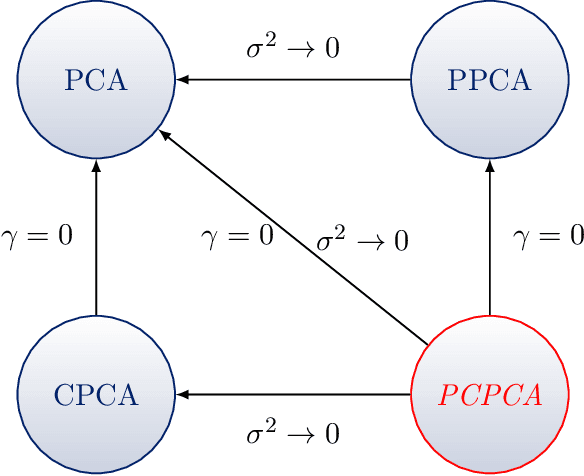
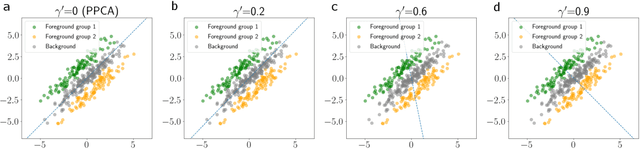
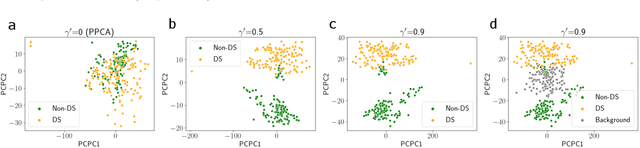
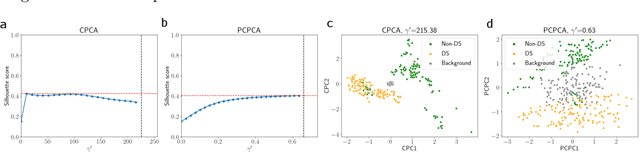
Dimension reduction is useful for exploratory data analysis. In many applications, it is of interest to discover variation that is enriched in a "foreground" dataset relative to a "background" dataset. Recently, contrastive principal component analysis (CPCA) was proposed for this setting. However, the lack of a formal probabilistic model makes it difficult to reason about CPCA and to tune its hyperparameter. In this work, we propose probabilistic contrastive principal component analysis (PCPCA), a model-based alternative to CPCA. We discuss how to set the hyperparameter in theory and in practice, and we show several of PCPCA's advantages, including greater interpretability, uncertainty quantification, robustness to noise and missing data, and the ability to generate data from the model. We demonstrate PCPCA's performance through a series of simulations and experiments with datasets of gene expression, protein expression, and images.
The multilayer random dot product graph
Jul 20, 2020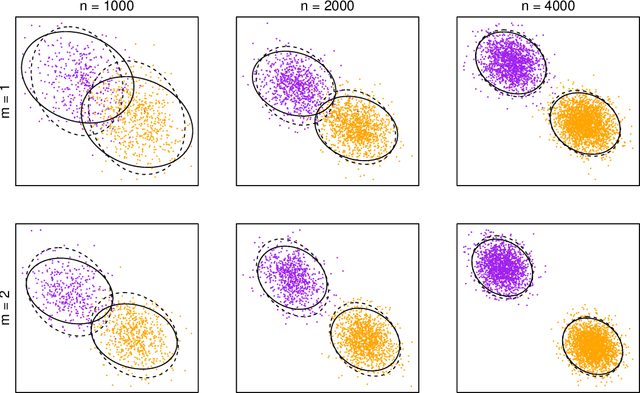

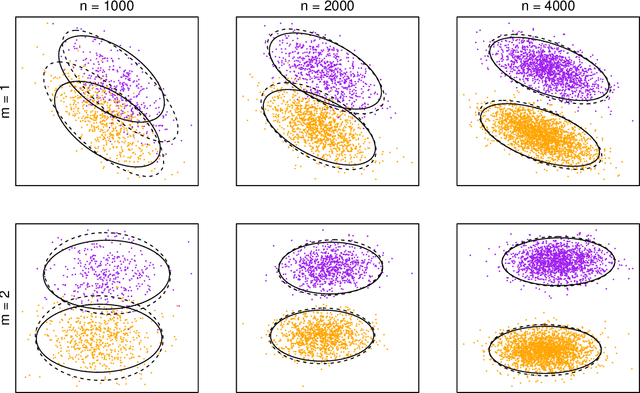
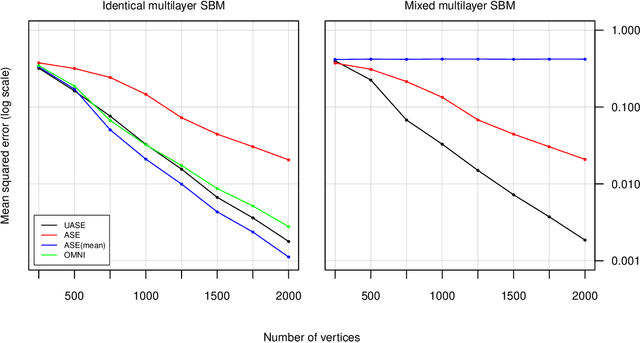
We present an extension of the latent position network model known as the generalised random dot product graph to accommodate multiple graphs with a common node structure, based on a matrix representation of the natural third-order tensor created from the adjacency matrices of these graphs. Theoretical results concerning the asymptotic behaviour of the node representations obtained by spectral embedding are established, showing that after the application of a linear transformation these converge uniformly in the Euclidean norm to the latent positions with a Gaussian error. The flexibility of the model is demonstrated through application to the tasks of latent position recovery and two-graph hypothesis testing, in which it performs favourably compared to existing models. Empirical improvements in link prediction over single graph embeddings are exhibited in a cyber-security example.