 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Gesture Generation from the Trimodal Context of Text, Audio, and Speaker Identity
Sep 04, 2020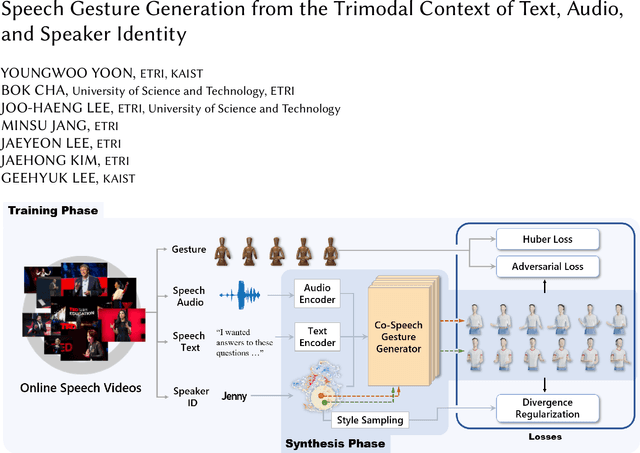
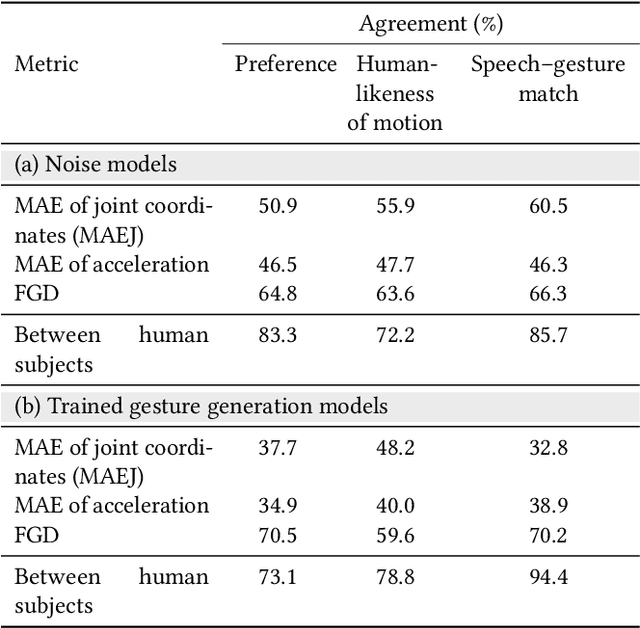
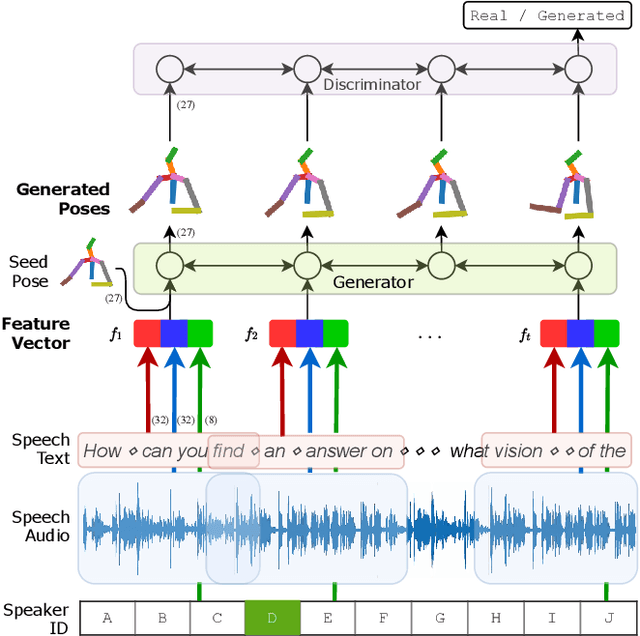

For human-like agents, including virtual avatars and social robots, making proper gestures while speaking is crucial in human--agent interaction. Co-speech gestures enhance interaction experiences and make the agents look alive. However, it is difficult to generate human-like gestures due to the lack of understanding of how people gesture. Data-driven approaches attempt to learn gesticulation skills from human demonstrations, but the ambiguous and individual nature of gestures hinders learning. In this paper, we present an automatic gesture generation model that uses the multimodal context of speech text, audio, and speaker identity to reliably generate gestures. By incorporating a multimodal context and an adversarial training scheme, the proposed model outputs gestures that are human-like and that match with speech content and rhythm. We also introduce a new quantitative evaluation metric for gesture generation models. Experiments with the introduced metric and subjective human evaluation showed that the proposed gesture generation model is better than existing end-to-end generation models. We further confirm that our model is able to work with synthesized audio in a scenario where contexts are constrained, and show that different gesture styles can be generated for the same speech by specifying different speaker identities in the style embedding space that is learned from videos of various speakers. All the code and data is available at https://github.com/ai4r/Gesture-Generation-from-Trimodal-Context.
Robots Learn Social Skills: End-to-End Learning of Co-Speech Gesture Generation for Humanoid Robots
Oct 30, 2018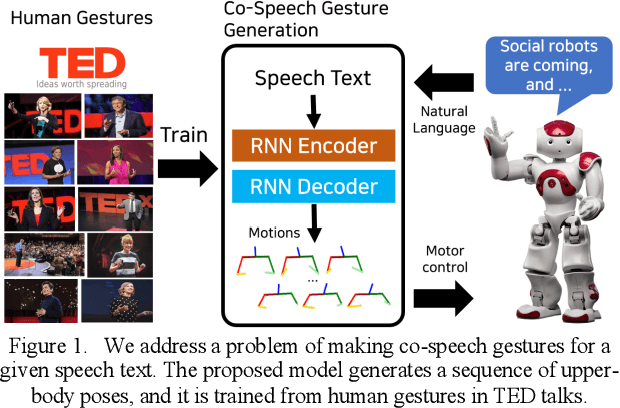

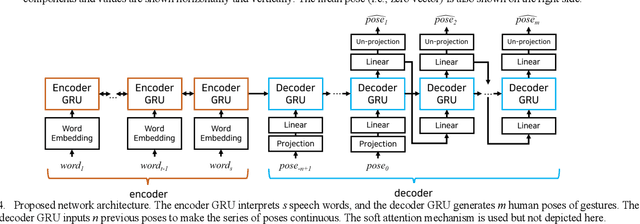
Co-speech gestures enhance interaction experiences between humans as well as between humans and robots. Existing robots use rule-based speech-gesture association, but this requires human labor and prior knowledge of experts to be implemented. We present a learning-based co-speech gesture generation that is learned from 52 h of TED talks. The proposed end-to-end neural network model consists of an encoder for speech text understanding and a decoder to generate a sequence of gestures. The model successfully produces various gestures including iconic, metaphoric, deictic, and beat gestures. In a subjective evaluation, participants reported that the gestures were human-like and matched the speech content. We also demonstrate a co-speech gesture with a NAO robot working in real time.