 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Case for Hierarchical Deep Learning Inference at the Network Edge
Apr 23, 2023



Resource-constrained Edge Devices (EDs), e.g., IoT sensors and microcontroller units, are expected to make intelligent decisions using Deep Learning (DL) inference at the edge of the network. Toward this end, there is a significant research effort in developing tinyML models - Deep Learning (DL) models with reduced computation and memory storage requirements - that can be embedded on these devices. However, tinyML models have lower inference accuracy. On a different front, DNN partitioning and inference offloading techniques were studied for distributed DL inference between EDs and Edge Servers (ESs). In this paper, we explore Hierarchical Inference (HI), a novel approach proposed by Vishnu et al. 2023, arXiv:2304.00891v1 , for performing distributed DL inference at the edge. Under HI, for each data sample, an ED first uses a local algorithm (e.g., a tinyML model) for inference. Depending on the application, if the inference provided by the local algorithm is incorrect or further assistance is required from large DL models on edge or cloud, only then the ED offloads the data sample. At the outset, HI seems infeasible as the ED, in general, cannot know if the local inference is sufficient or not. Nevertheless, we present the feasibility of implementing HI for machine fault detection and image classification applications. We demonstrate its benefits using quantitative analysis and argue that using HI will result in low latency, bandwidth savings, and energy savings in edge AI systems.
Offloading Algorithms for Maximizing Inference Accuracy on Edge Device Under a Time Constraint
Dec 21, 2021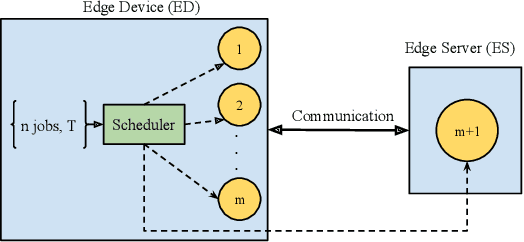
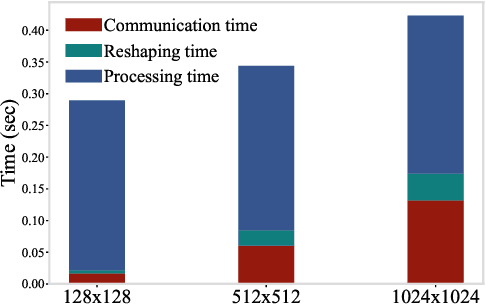
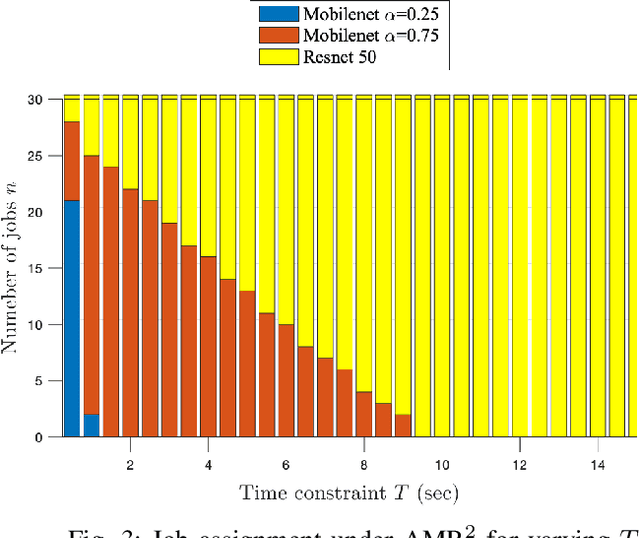
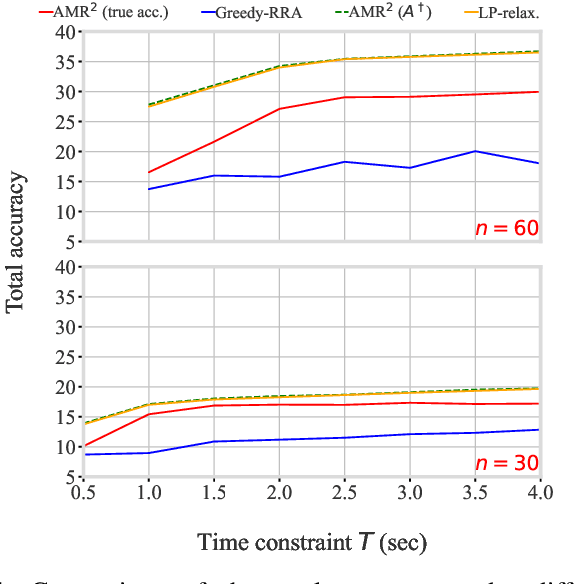
With the emergence of edge computing, the problem of offloading jobs between an Edge Device (ED) and an Edge Server (ES) received significant attention in the past. Motivated by the fact that an increasing number of applications are using Machine Learning (ML) inference, we study the problem of offloading inference jobs by considering the following novel aspects: 1) in contrast to a typical computational job, the processing time of an inference job depends on the size of the ML model, and 2) recently proposed Deep Neural Networks (DNNs) for resource-constrained devices provide the choice of scaling the model size. We formulate an assignment problem with the aim of maximizing the total inference accuracy of n data samples available at the ED, subject to a time constraint T on the makespan. We propose an approximation algorithm AMR2, and prove that it results in a makespan at most 2T, and achieves a total accuracy that is lower by a small constant from optimal total accuracy. As proof of concept, we implemented AMR2 on a Raspberry Pi, equipped with MobileNet, and is connected to a server equipped with ResNet, and studied the total accuracy and makespan performance of AMR2 for image classification application.