 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Internet of Physical AI Agents: Interoperability, Longevity, and the Cost of Getting It Wrong
Mar 16, 2026The Internet has evolved by progressively expanding what humanity connects: first computers, then people, and later billions of devices through the Internet of Things (IoT). While IoT succeeded in digitizing perception at scale, it also exposed fundamental limitations, including fragmentation, weak security, limited autonomy, and poor long-term sustainability. Today, advances in edge hardware, sensing, connectivity, and artificial intelligence enable a new phase: the Internet of Physical AI Agents. Unlike IoT devices that primarily sense and report, Physical AI Agents perceive, reason, and act in real time, operating autonomously and cooperatively across safety-critical domains such as disaster response, healthcare, industrial automation, and mobility. However, embedding fast-evolving AI capabilities into long-lived physical infrastructure introduces new architectural risks, particularly around interoperability, lifecycle management, and premature ossification. This article revisits lessons from IoT and Internet evolution, and articulates design principles for building resilient, evolvable, and trustworthy agentic systems. We present an architectural blueprint encompassing agentic identity, secure agent-to-agent communication, semantic interoperability, policy-governed runtimes, and observability-driven governance. We argue that treating evolution, trust, and interoperability as first-class requirements is essential to avoid hard-coding today's assumptions into tomorrow's intelligent infrastructure, and to prevent the high technical and economic cost of getting it wrong.
Bio-inspired Agentic Self-healing Framework for Resilient Distributed Computing Continuum Systems
Jan 01, 2026Human biological systems sustain life through extraordinary resilience, continually detecting damage, orchestrating targeted responses, and restoring function through self-healing. Inspired by these capabilities, this paper introduces ReCiSt, a bio-inspired agentic self-healing framework designed to achieve resilience in Distributed Computing Continuum Systems (DCCS). Modern DCCS integrate heterogeneous computing resources, ranging from resource-constrained IoT devices to high-performance cloud infrastructures, and their inherent complexity, mobility, and dynamic operating conditions expose them to frequent faults that disrupt service continuity. These challenges underscore the need for scalable, adaptive, and self-regulated resilience strategies. ReCiSt reconstructs the biological phases of Hemostasis, Inflammation, Proliferation, and Remodeling into the computational layers Containment, Diagnosis, Meta-Cognitive, and Knowledge for DCCS. These four layers perform autonomous fault isolation, causal diagnosis, adaptive recovery, and long-term knowledge consolidation through Language Model (LM)-powered agents. These agents interpret heterogeneous logs, infer root causes, refine reasoning pathways, and reconfigure resources with minimal human intervention. The proposed ReCiSt framework is evaluated on public fault datasets using multiple LMs, and no baseline comparison is included due to the scarcity of similar approaches. Nevertheless, our results, evaluated under different LMs, confirm ReCiSt's self-healing capabilities within tens of seconds with minimum of 10% of agent CPU usage. Our results also demonstrated depth of analysis to over come uncertainties and amount of micro-agents invoked to achieve resilience.
Towards Efficient Multi-LLM Inference: Characterization and Analysis of LLM Routing and Hierarchical Techniques
Jun 06, 2025Recent progress in Language Models (LMs) has dramatically advanced the field of natural language processing (NLP), excelling at tasks like text generation, summarization, and question answering. However, their inference remains computationally expensive and energy intensive, especially in settings with limited hardware, power, or bandwidth. This makes it difficult to deploy LMs in mobile, edge, or cost sensitive environments. To address these challenges, recent approaches have introduced multi LLM intelligent model selection strategies that dynamically allocate computational resources based on query complexity -- using lightweight models for simpler queries and escalating to larger models only when necessary. This survey explores two complementary strategies for efficient LLM inference: (i) routing, which selects the most suitable model based on the query, and (ii) cascading or hierarchical inference (HI), which escalates queries through a sequence of models until a confident response is found. Both approaches aim to reduce computation by using lightweight models for simpler tasks while offloading only when needed. We provide a comparative analysis of these techniques across key performance metrics, discuss benchmarking efforts, and outline open challenges. Finally, we outline future research directions to enable faster response times, adaptive model selection based on task complexity, and scalable deployment across heterogeneous environments, making LLM based systems more efficient and accessible for real world applications.
Smaller, Smarter, Closer: The Edge of Collaborative Generative AI
May 22, 2025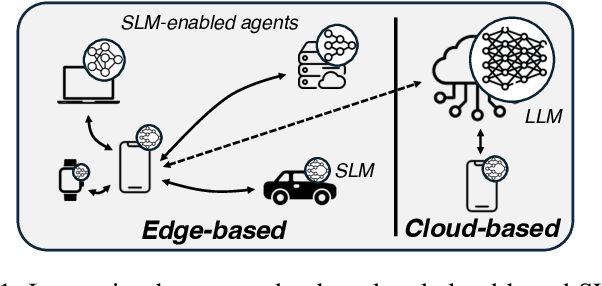
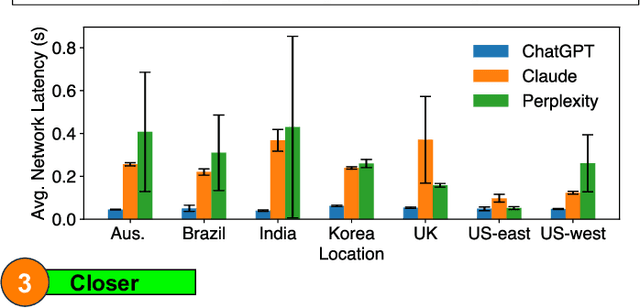

The rapid adoption of generative AI (GenAI), particularly Large Language Models (LLMs), has exposed critical limitations of cloud-centric deployments, including latency, cost, and privacy concerns. Meanwhile, Small Language Models (SLMs) are emerging as viable alternatives for resource-constrained edge environments, though they often lack the capabilities of their larger counterparts. This article explores the potential of collaborative inference systems that leverage both edge and cloud resources to address these challenges. By presenting distinct cooperation strategies alongside practical design principles and experimental insights, we offer actionable guidance for deploying GenAI across the computing continuum.
Edge-First Language Model Inference: Models, Metrics, and Tradeoffs
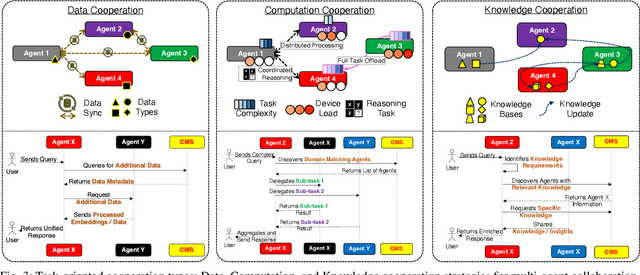
May 22, 2025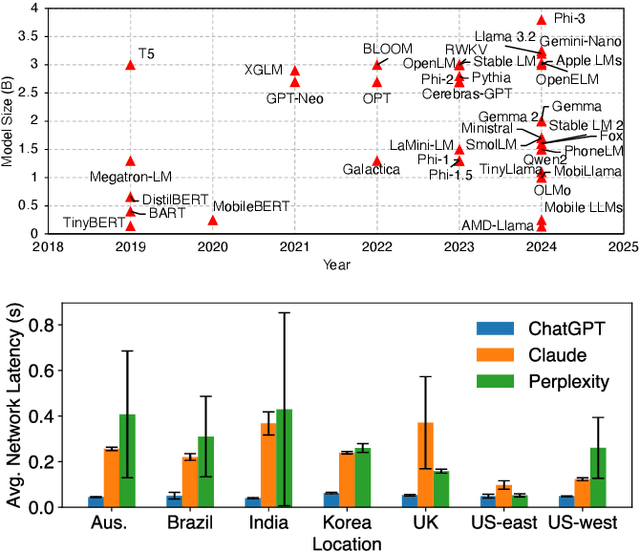
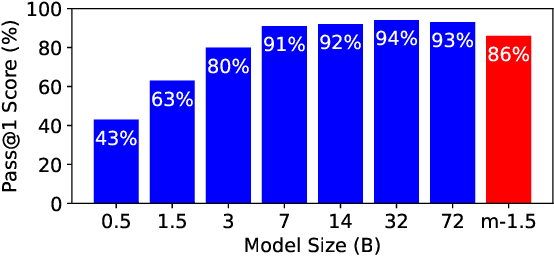
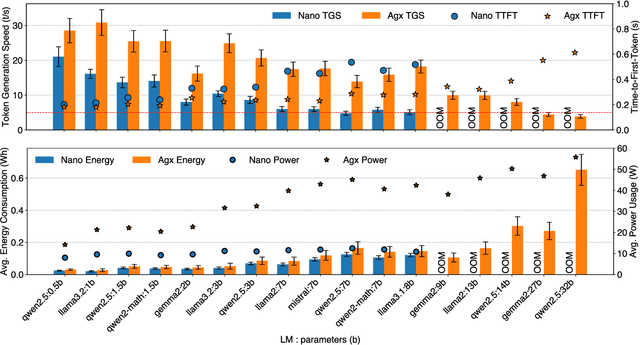
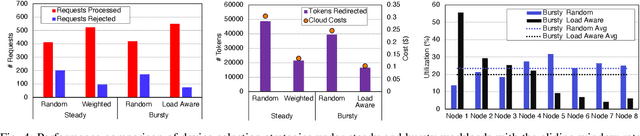
The widespread adoption of Language Models (LMs) across industries is driving interest in deploying these services across the computing continuum, from the cloud to the network edge. This shift aims to reduce costs, lower latency, and improve reliability and privacy. Small Language Models (SLMs), enabled by advances in model compression, are central to this shift, offering a path to on-device inference on resource-constrained edge platforms. This work examines the interplay between edge and cloud deployments, starting from detailed benchmarking of SLM capabilities on single edge devices, and extending to distributed edge clusters. We identify scenarios where edge inference offers comparable performance with lower costs, and others where cloud fallback becomes essential due to limits in scalability or model capacity. Rather than proposing a one-size-fits-all solution, we present platform-level comparisons and design insights for building efficient, adaptive LM inference systems across heterogeneous environments.
Sometimes Painful but Certainly Promising: Feasibility and Trade-offs of Language Model Inference at the Edge
Mar 12, 2025
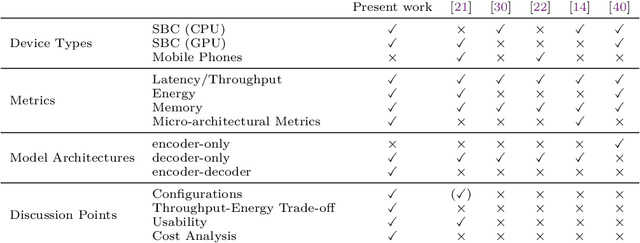
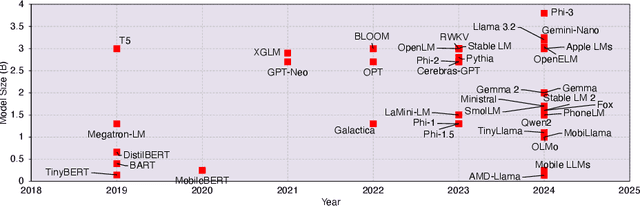

The rapid rise of Language Models (LMs) has expanded the capabilities of natural language processing, powering applications from text generation to complex decision-making. While state-of-the-art LMs often boast hundreds of billions of parameters and are primarily deployed in data centers, recent trends show a growing focus on compact models-typically under 10 billion parameters-enabled by techniques such as quantization and other model compression techniques. This shift paves the way for LMs on edge devices, offering potential benefits such as enhanced privacy, reduced latency, and improved data sovereignty. However, the inherent complexity of even these smaller models, combined with the limited computing resources of edge hardware, raises critical questions about the practical trade-offs in executing LM inference outside the cloud. To address these challenges, we present a comprehensive evaluation of generative LM inference on representative CPU-based and GPU-accelerated edge devices. Our study measures key performance indicators-including memory usage, inference speed, and energy consumption-across various device configurations. Additionally, we examine throughput-energy trade-offs, cost considerations, and usability, alongside an assessment of qualitative model performance. While quantization helps mitigate memory overhead, it does not fully eliminate resource bottlenecks, especially for larger models. Our findings quantify the memory and energy constraints that must be considered for practical real-world deployments, offering concrete insights into the trade-offs between model size, inference performance, and efficiency. The exploration of LMs at the edge is still in its early stages. We hope this study provides a foundation for future research, guiding the refinement of models, the enhancement of inference efficiency, and the advancement of edge-centric AI systems.
Large-Scale AI in Telecom: Charting the Roadmap for Innovation, Scalability, and Enhanced Digital Experiences
Mar 06, 2025



This white paper discusses the role of large-scale AI in the telecommunications industry, with a specific focus on the potential of generative AI to revolutionize network functions and user experiences, especially in the context of 6G systems. It highlights the development and deployment of Large Telecom Models (LTMs), which are tailored AI models designed to address the complex challenges faced by modern telecom networks. The paper covers a wide range of topics, from the architecture and deployment strategies of LTMs to their applications in network management, resource allocation, and optimization. It also explores the regulatory, ethical, and standardization considerations for LTMs, offering insights into their future integration into telecom infrastructure. The goal is to provide a comprehensive roadmap for the adoption of LTMs to enhance scalability, performance, and user-centric innovation in telecom networks.
Future-Proofing Mobile Networks: A Digital Twin Approach to Multi-Signal Management
Jul 22, 2024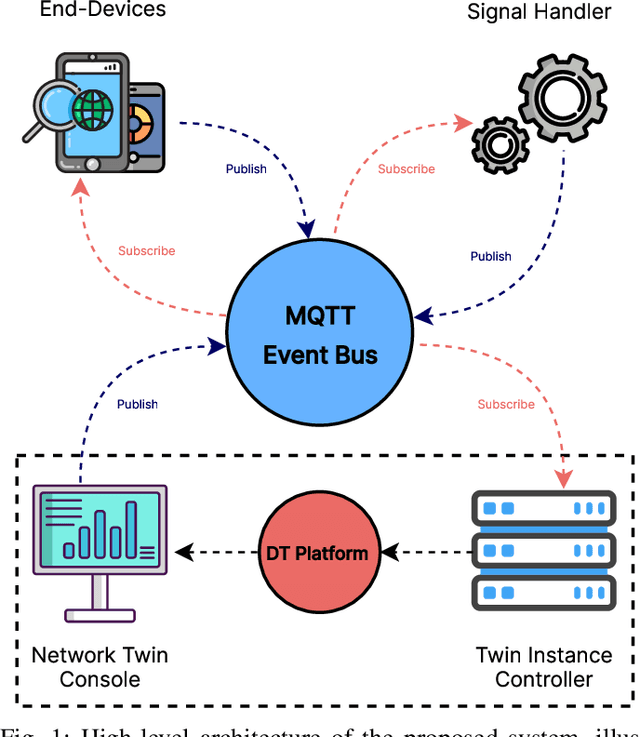
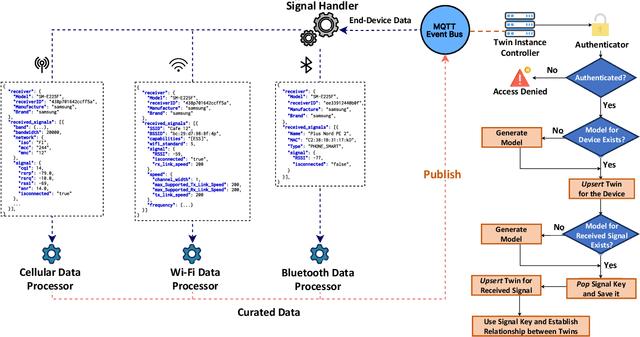
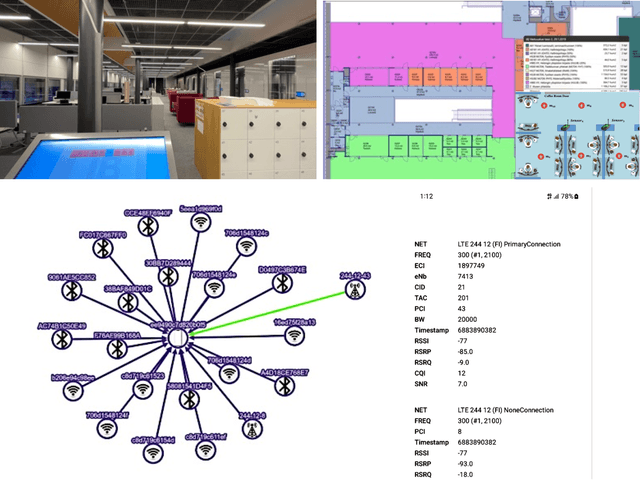
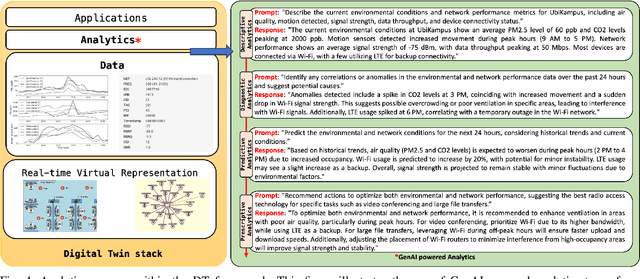
Digital Twins (DTs) are set to become a key enabling technology in future wireless networks, with their use in network management increasing significantly. We developed a DT framework that leverages the heterogeneity of network access technologies as a resource for enhanced network performance and management, enabling smart data handling in the physical network. Tested in a \textit{Campus Area Network} environment, our framework integrates diverse data sources to provide real-time, holistic insights into network performance and environmental sensing. We also envision that traditional analytics will evolve to rely on emerging AI models, such as Generative AI (GenAI), while leveraging current analytics capabilities. This capacity can simplify analytics processes through advanced ML models, enabling descriptive, diagnostic, predictive, and prescriptive analytics in a unified fashion. Finally, we present specific research opportunities concerning interoperability aspects and envision aligning advancements in DT technology with evolved AI integration.
Follow-Me AI: Energy-Efficient User Interaction with Smart Environments
Apr 18, 2024



This article introduces Follow-Me AI, a concept designed to enhance user interactions with smart environments, optimize energy use, and provide better control over data captured by these environments. Through AI agents that accompany users, Follow-Me AI negotiates data management based on user consent, aligns environmental controls as well as user communication and computes resources available in the environment with user preferences, and predicts user behavior to proactively adjust the smart environment. The manuscript illustrates this concept with a detailed example of Follow-Me AI in a smart campus setting, detailing the interactions with the building's management system for optimal comfort and efficiency. Finally, this article looks into the challenges and opportunities related to Follow-Me AI.
AI-native Interconnect Framework for Integration of Large Language Model Technologies in 6G Systems
Nov 10, 2023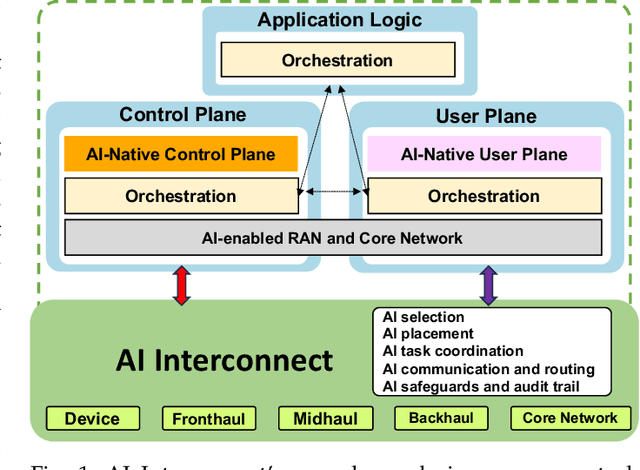
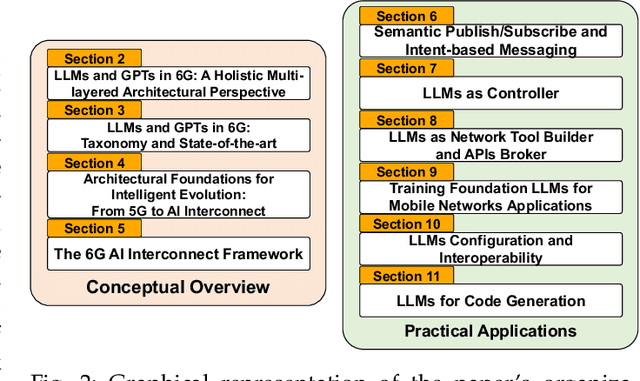
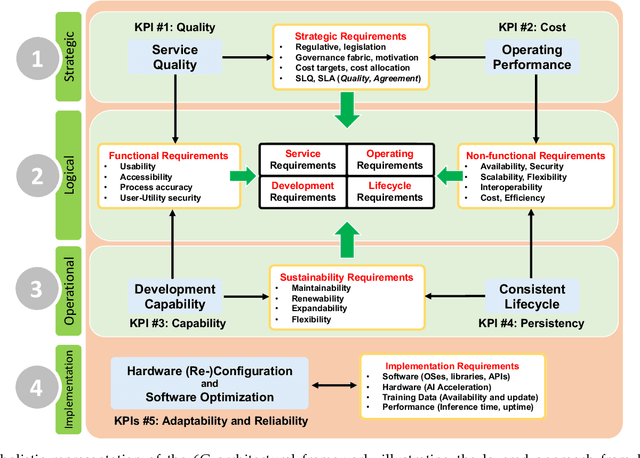
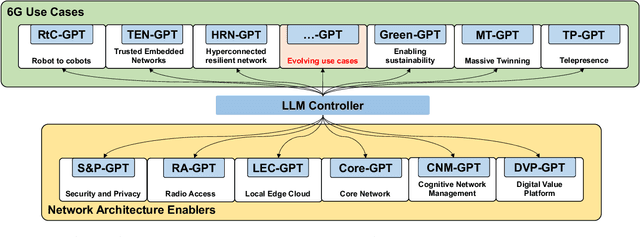
The evolution towards 6G architecture promises a transformative shift in communication networks, with artificial intelligence (AI) playing a pivotal role. This paper delves deep into the seamless integration of Large Language Models (LLMs) and Generalized Pretrained Transformers (GPT) within 6G systems. Their ability to grasp intent, strategize, and execute intricate commands will be pivotal in redefining network functionalities and interactions. Central to this is the AI Interconnect framework, intricately woven to facilitate AI-centric operations within the network. Building on the continuously evolving current state-of-the-art, we present a new architectural perspective for the upcoming generation of mobile networks. Here, LLMs and GPTs will collaboratively take center stage alongside traditional pre-generative AI and machine learning (ML) algorithms. This union promises a novel confluence of the old and new, melding tried-and-tested methods with transformative AI technologies. Along with providing a conceptual overview of this evolution, we delve into the nuances of practical applications arising from such an integration. Through this paper, we envisage a symbiotic integration where AI becomes the cornerstone of the next-generation communication paradigm, offering insights into the structural and functional facets of an AI-native 6G network.