 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSometimes Painful but Certainly Promising: Feasibility and Trade-offs of Language Model Inference at the Edge
Paper and Code
Mar 12, 2025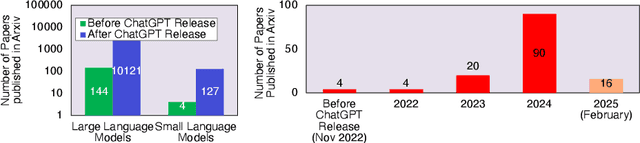
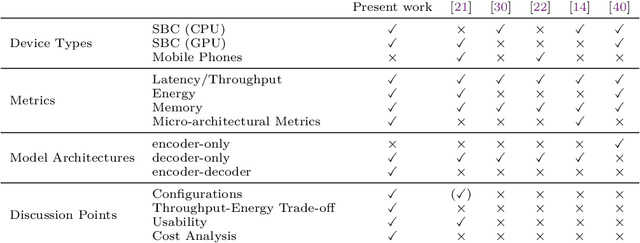
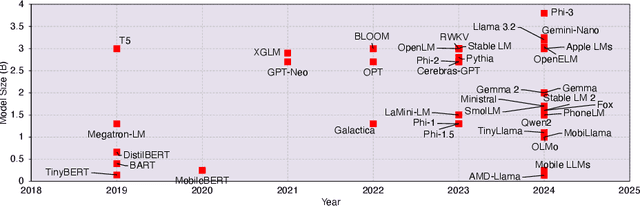

The rapid rise of Language Models (LMs) has expanded the capabilities of natural language processing, powering applications from text generation to complex decision-making. While state-of-the-art LMs often boast hundreds of billions of parameters and are primarily deployed in data centers, recent trends show a growing focus on compact models-typically under 10 billion parameters-enabled by techniques such as quantization and other model compression techniques. This shift paves the way for LMs on edge devices, offering potential benefits such as enhanced privacy, reduced latency, and improved data sovereignty. However, the inherent complexity of even these smaller models, combined with the limited computing resources of edge hardware, raises critical questions about the practical trade-offs in executing LM inference outside the cloud. To address these challenges, we present a comprehensive evaluation of generative LM inference on representative CPU-based and GPU-accelerated edge devices. Our study measures key performance indicators-including memory usage, inference speed, and energy consumption-across various device configurations. Additionally, we examine throughput-energy trade-offs, cost considerations, and usability, alongside an assessment of qualitative model performance. While quantization helps mitigate memory overhead, it does not fully eliminate resource bottlenecks, especially for larger models. Our findings quantify the memory and energy constraints that must be considered for practical real-world deployments, offering concrete insights into the trade-offs between model size, inference performance, and efficiency. The exploration of LMs at the edge is still in its early stages. We hope this study provides a foundation for future research, guiding the refinement of models, the enhancement of inference efficiency, and the advancement of edge-centric AI systems.