 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Performance of Smart Industry 4.0 Applications on Cloud Computing Systems
Paper and Code
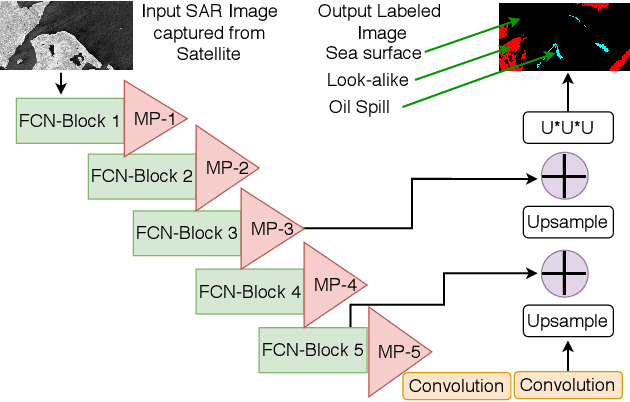
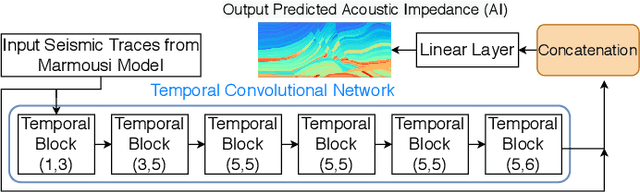

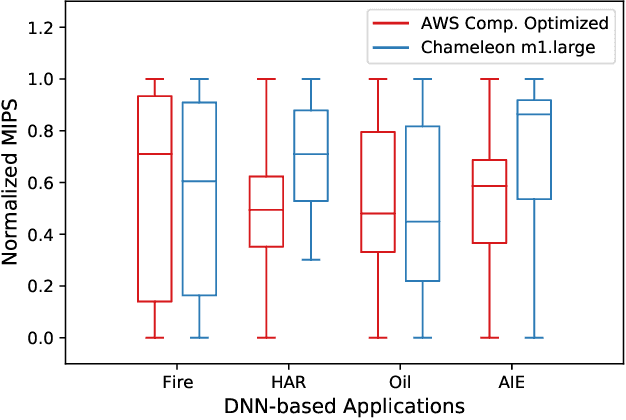
Cloud-based Deep Neural Network (DNN) applications that make latency-sensitive inference are becoming an indispensable part of Industry 4.0. Due to the multi-tenancy and resource heterogeneity, both inherent to the cloud computing environments, the inference time of DNN-based applications are stochastic. Such stochasticity, if not captured, can potentially lead to low Quality of Service (QoS) or even a disaster in critical sectors, such as Oil and Gas industry. To make Industry 4.0 robust, solution architects and researchers need to understand the behavior of DNN-based applications and capture the stochasticity exists in their inference times. Accordingly, in this study, we provide a descriptive analysis of the inference time from two perspectives. First, we perform an application-centric analysis and statistically model the execution time of four categorically different DNN applications on both Amazon and Chameleon clouds. Second, we take a resource-centric approach and analyze a rate-based metric in form of Million Instruction Per Second (MIPS) for heterogeneous machines in the cloud. This non-parametric modeling, achieved via Jackknife and Bootstrap re-sampling methods, provides the confidence interval of MIPS for heterogeneous cloud machines. The findings of this research can be helpful for researchers and cloud solution architects to develop solutions that are robust against the stochastic nature of the inference time of DNN applications in the cloud and can offer a higher QoS to their users and avoid unintended outcomes.