 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedded Encoder-Decoder in Convolutional Networks Towards Explainable AI
Jun 19, 2020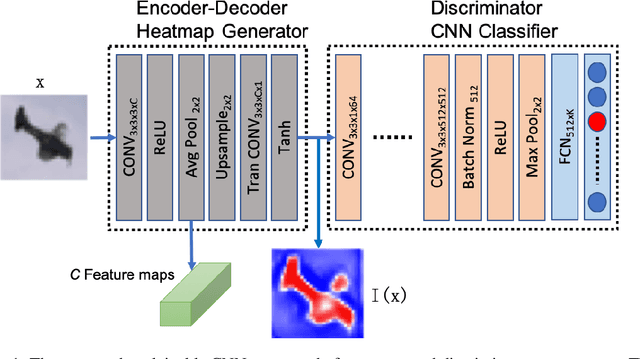


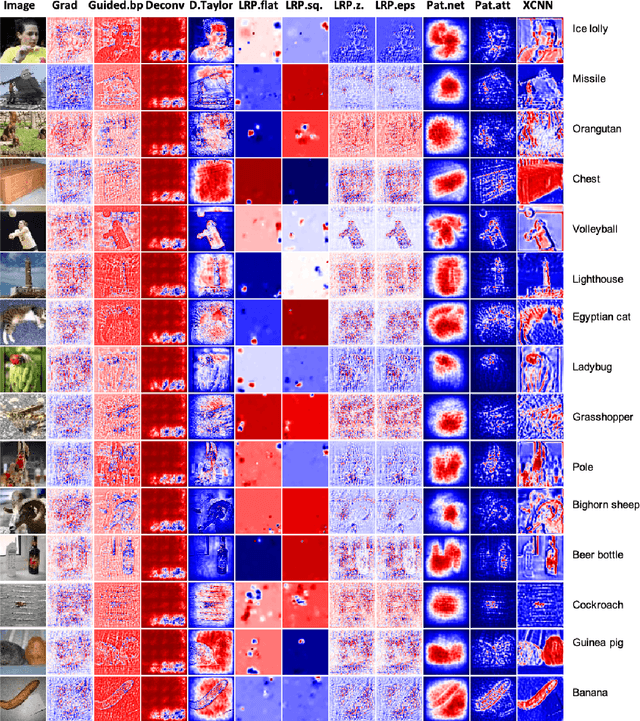
Understanding intermediate layers of a deep learning model and discovering the driving features of stimuli have attracted much interest, recently. Explainable artificial intelligence (XAI) provides a new way to open an AI black box and makes a transparent and interpretable decision. This paper proposes a new explainable convolutional neural network (XCNN) which represents important and driving visual features of stimuli in an end-to-end model architecture. This network employs encoder-decoder neural networks in a CNN architecture to represent regions of interest in an image based on its category. The proposed model is trained without localization labels and generates a heat-map as part of the network architecture without extra post-processing steps. The experimental results on the CIFAR-10, Tiny ImageNet, and MNIST datasets showed the success of our algorithm (XCNN) to make CNNs explainable. Based on visual assessment, the proposed model outperforms the current algorithms in class-specific feature representation and interpretable heatmap generation while providing a simple and flexible network architecture. The initial success of this approach warrants further study to enhance weakly supervised localization and semantic segmentation in explainable frameworks.
Deep Learning in Spiking Neural Networks
Sep 01, 2018
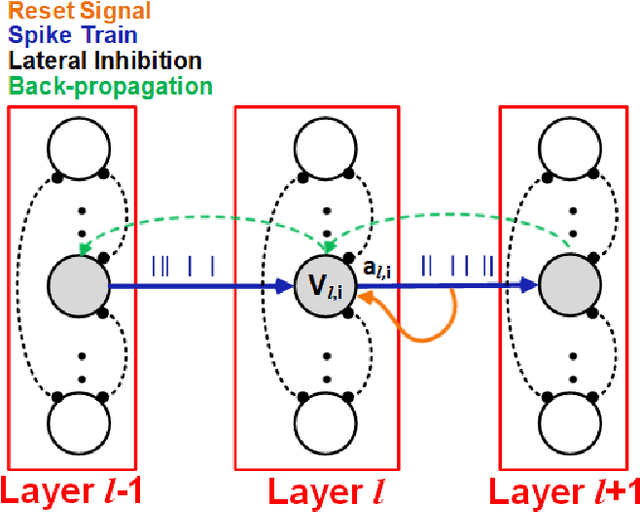
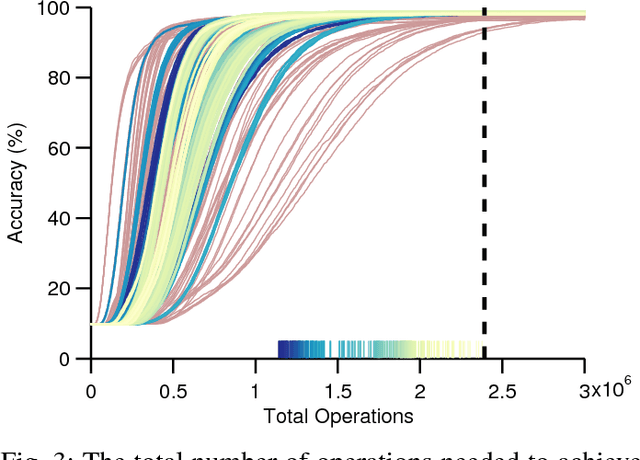
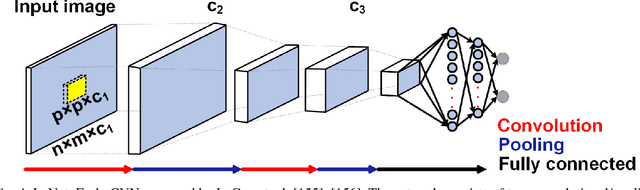
In recent years, deep learning has been a revolution in the field of machine learning, for computer vision in particular. In this approach, a deep (multilayer) artificial neural network (ANN) is trained in a supervised manner using backpropagation. Huge amounts of labeled examples are required, but the resulting classification accuracy is truly impressive, sometimes outperforming humans. Neurons in an ANN are characterized by a single, static, continuous-valued activation. Yet biological neurons use discrete spikes to compute and transmit information, and the spike times, in addition to the spike rates, matter. Spiking neural networks (SNNs) are thus more biologically realistic than ANNs, and arguably the only viable option if one wants to understand how the brain computes. SNNs are also more hardware friendly and energy-efficient than ANNs, and are thus appealing for technology, especially for portable devices. However, training deep SNNs remains a challenge. Spiking neurons' transfer function is usually non-differentiable, which prevents using backpropagation. Here we review recent supervised and unsupervised methods to train deep SNNs, and compare them in terms of accuracy, but also computational cost and hardware friendliness. The emerging picture is that SNNs still lag behind ANNs in terms of accuracy, but the gap is decreasing, and can even vanish on some tasks, while the SNNs typically require much fewer operations.
Representation Learning using Event-based STDP
Mar 09, 2018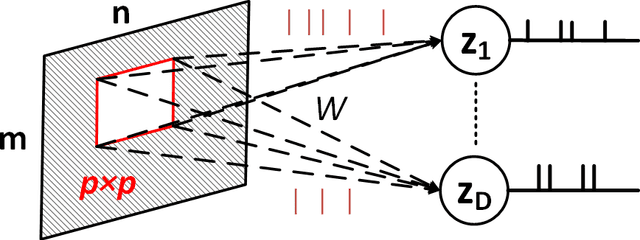


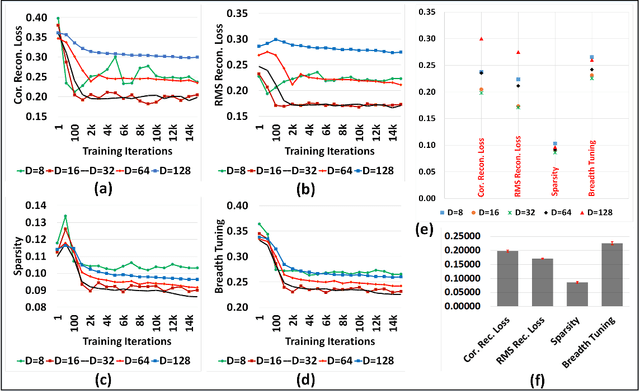
Although representation learning methods developed within the framework of traditional neural networks are relatively mature, developing a spiking representation model remains a challenging problem. This paper proposes an event-based method to train a feedforward spiking neural network (SNN) layer for extracting visual features. The method introduces a novel spike-timing-dependent plasticity (STDP) learning rule and a threshold adjustment rule both derived from a vector quantization-like objective function subject to a sparsity constraint. The STDP rule is obtained by the gradient of a vector quantization criterion that is converted to spike-based, spatio-temporally local update rules in a spiking network of leaky, integrate-and-fire (LIF) neurons. Independence and sparsity of the model are achieved by the threshold adjustment rule and by a softmax function implementing inhibition in the representation layer consisting of WTA-thresholded spiking neurons. Together, these mechanisms implement a form of spike-based, competitive learning. Two sets of experiments are performed on the MNIST and natural image datasets. The results demonstrate a sparse spiking visual representation model with low reconstruction loss comparable with state-of-the-art visual coding approaches, yet our rule is local in both time and space, thus biologically plausible and hardware friendly.
BP-STDP: Approximating Backpropagation using Spike Timing Dependent Plasticity
Mar 09, 2018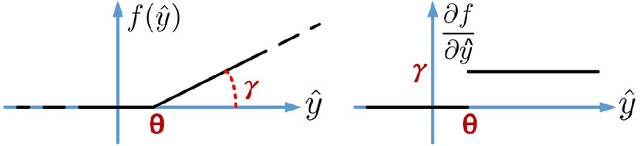
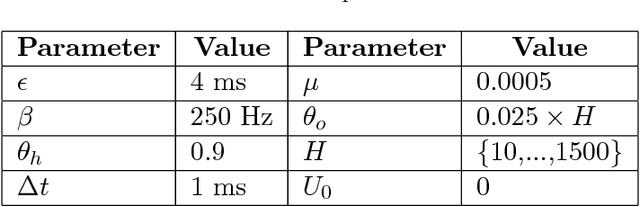
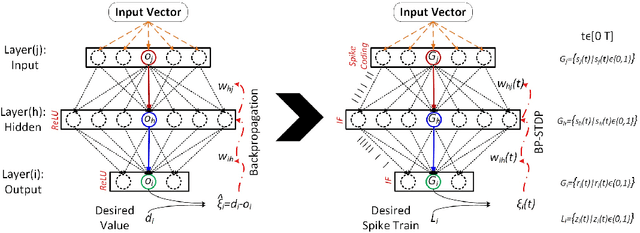
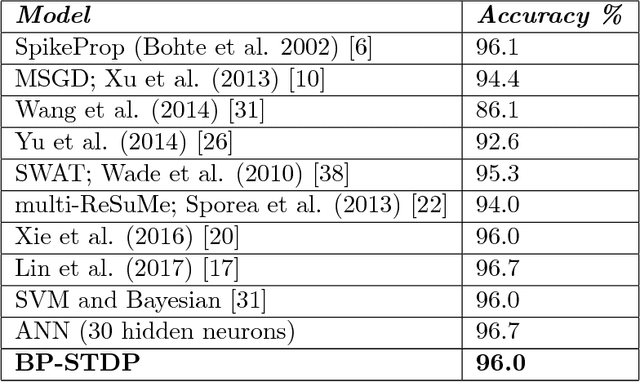
The problem of training spiking neural networks (SNNs) is a necessary precondition to understanding computations within the brain, a field still in its infancy. Previous work has shown that supervised learning in multi-layer SNNs enables bio-inspired networks to recognize patterns of stimuli through hierarchical feature acquisition. Although gradient descent has shown impressive performance in multi-layer (and deep) SNNs, it is generally not considered biologically plausible and is also computationally expensive. This paper proposes a novel supervised learning approach based on an event-based spike-timing-dependent plasticity (STDP) rule embedded in a network of integrate-and-fire (IF) neurons. The proposed temporally local learning rule follows the backpropagation weight change updates applied at each time step. This approach enjoys benefits of both accurate gradient descent and temporally local, efficient STDP. Thus, this method is able to address some open questions regarding accurate and efficient computations that occur in the brain. The experimental results on the XOR problem, the Iris data, and the MNIST dataset demonstrate that the proposed SNN performs as successfully as the traditional NNs. Our approach also compares favorably with the state-of-the-art multi-layer SNNs.
Bio-Inspired Spiking Convolutional Neural Network using Layer-wise Sparse Coding and STDP Learning
Jun 24, 2017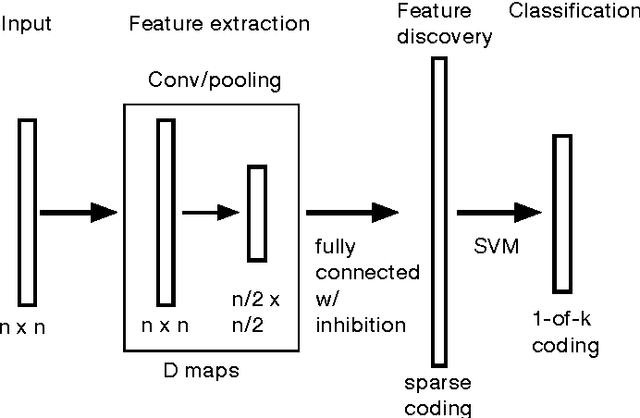
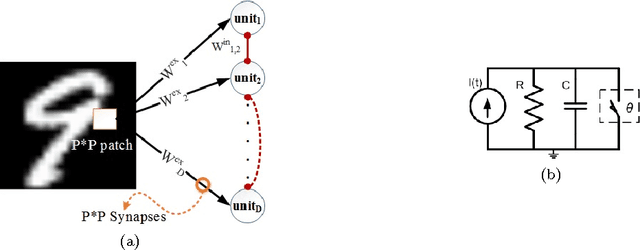
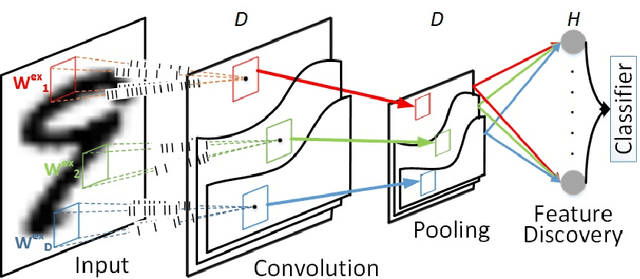
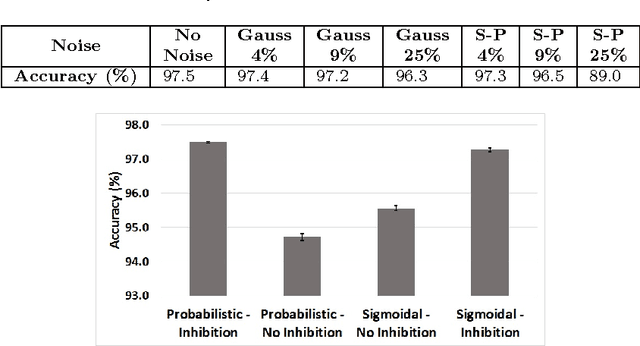
Hierarchical feature discovery using non-spiking convolutional neural networks (CNNs) has attracted much recent interest in machine learning and computer vision. However, it is still not well understood how to create a biologically plausible network of brain-like, spiking neurons with multi-layer, unsupervised learning. This paper explores a novel bio-inspired spiking CNN that is trained in a greedy, layer-wise fashion. The proposed network consists of a spiking convolutional-pooling layer followed by a feature discovery layer extracting independent visual features. Kernels for the convolutional layer are trained using local learning. The learning is implemented using a sparse, spiking auto-encoder representing primary visual features. The feature discovery layer extracts independent features by probabilistic, leaky integrate-and-fire (LIF) neurons that are sparsely active in response to stimuli. The layer of the probabilistic, LIF neurons implicitly provides lateral inhibitions to extract sparse and independent features. Experimental results show that the convolutional layer is stack-admissible, enabling it to support a multi-layer learning. The visual features obtained from the proposed probabilistic LIF neurons in the feature discovery layer are utilized for training a classifier. Classification results contribute to the independent and informative visual features extracted in a hierarchy of convolutional and feature discovery layers. The proposed model is evaluated on the MNIST digit dataset using clean and noisy images. The recognition performance for clean images is above 98%. The performance loss for recognizing the noisy images is in the range 0.1% to 8.5% depending on noise types and densities. This level of performance loss indicates that the network is robust to additive noise.
Bio-Inspired Multi-Layer Spiking Neural Network Extracts Discriminative Features from Speech Signals
Jun 10, 2017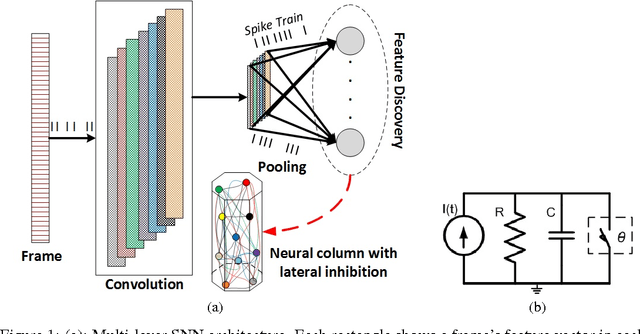

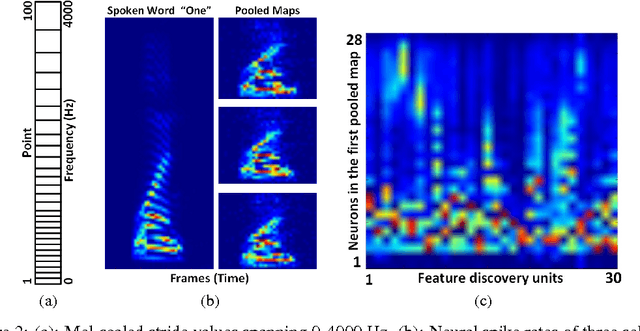

Spiking neural networks (SNNs) enable power-efficient implementations due to their sparse, spike-based coding scheme. This paper develops a bio-inspired SNN that uses unsupervised learning to extract discriminative features from speech signals, which can subsequently be used in a classifier. The architecture consists of a spiking convolutional/pooling layer followed by a fully connected spiking layer for feature discovery. The convolutional layer of leaky, integrate-and-fire (LIF) neurons represents primary acoustic features. The fully connected layer is equipped with a probabilistic spike-timing-dependent plasticity learning rule. This layer represents the discriminative features through probabilistic, LIF neurons. To assess the discriminative power of the learned features, they are used in a hidden Markov model (HMM) for spoken digit recognition. The experimental results show performance above 96% that compares favorably with popular statistical feature extraction methods. Our results provide a novel demonstration of unsupervised feature acquisition in an SNN.
A Spiking Network that Learns to Extract Spike Signatures from Speech Signals
Mar 12, 2017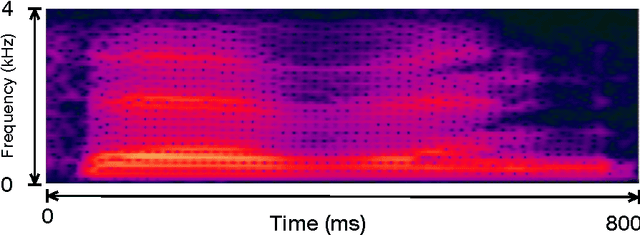
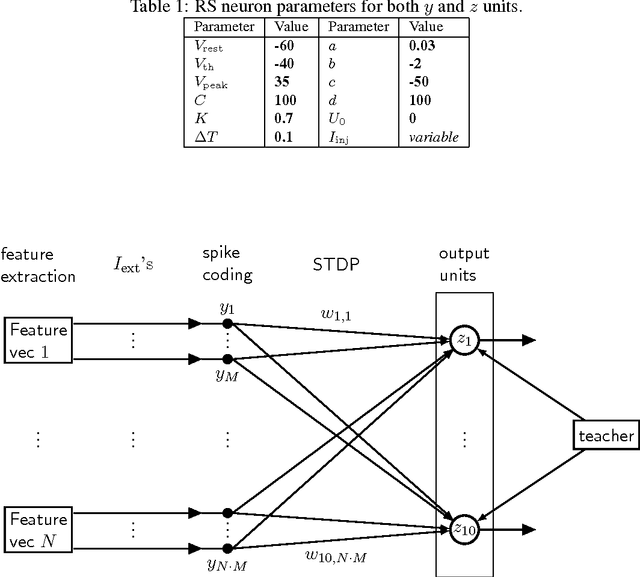

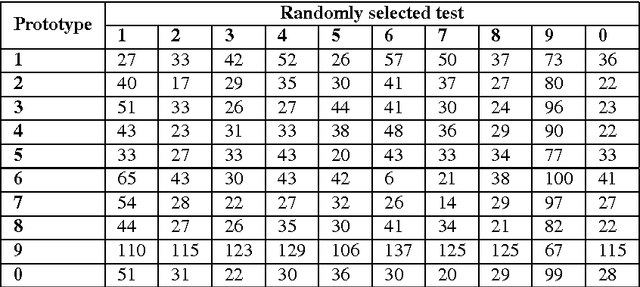
Spiking neural networks (SNNs) with adaptive synapses reflect core properties of biological neural networks. Speech recognition, as an application involving audio coding and dynamic learning, provides a good test problem to study SNN functionality. We present a simple, novel, and efficient nonrecurrent SNN that learns to convert a speech signal into a spike train signature. The signature is distinguishable from signatures for other speech signals representing different words, thereby enabling digit recognition and discrimination in devices that use only spiking neurons. The method uses a small, nonrecurrent SNN consisting of Izhikevich neurons equipped with spike timing dependent plasticity (STDP) and biologically realistic synapses. This approach introduces an efficient and fast network without error-feedback training, although it does require supervised training. The new simulation results produce discriminative spike train patterns for spoken digits in which highly correlated spike trains belong to the same category and low correlated patterns belong to different categories. The proposed SNN is evaluated using a spoken digit recognition task where a subset of the Aurora speech dataset is used. The experimental results show that the network performs well in terms of accuracy rate and complexity.
* Published in Neurocomputing Journal, Elsevier
Acquisition of Visual Features Through Probabilistic Spike-Timing-Dependent Plasticity
Nov 09, 2016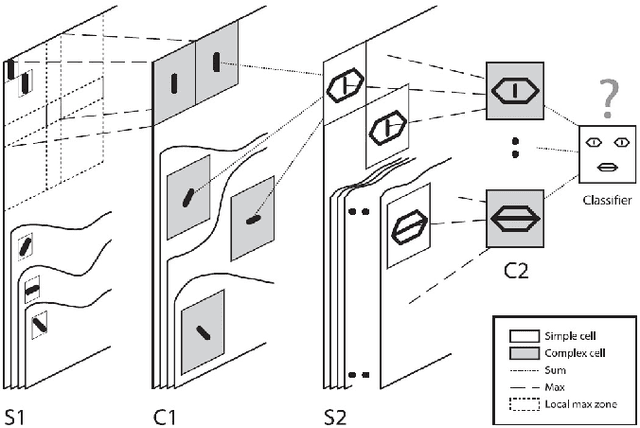

The final version of this paper has been published in IEEEXplore available at http://ieeexplore.ieee.org/document/7727213. Please cite this paper as: Amirhossein Tavanaei, Timothee Masquelier, and Anthony Maida, Acquisition of visual features through probabilistic spike-timing-dependent plasticity. IEEE International Joint Conference on Neural Networks. pp. 307-314, IJCNN 2016. This paper explores modifications to a feedforward five-layer spiking convolutional network (SCN) of the ventral visual stream [Masquelier, T., Thorpe, S., Unsupervised learning of visual features through spike timing dependent plasticity. PLoS Computational Biology, 3(2), 247-257]. The original model showed that a spike-timing-dependent plasticity (STDP) learning algorithm embedded in an appropriately selected SCN could perform unsupervised feature discovery. The discovered features where interpretable and could effectively be used to perform rapid binary decisions in a classifier. In order to study the robustness of the previous results, the present research examines the effects of modifying some of the components of the original model. For improved biological realism, we replace the original non-leaky integrate-and-fire neurons with Izhikevich-like neurons. We also replace the original STDP rule with a novel rule that has a probabilistic interpretation. The probabilistic STDP slightly but significantly improves the performance for both types of model neurons. Use of the Izhikevich-like neuron was not found to improve performance although performance was still comparable to the IF neuron. This shows that the model is robust enough to handle more biologically realistic neurons. We also conclude that the underlying reasons for stable performance in the model are preserved despite the overt changes to the explicit components of the model.
* IEEE-IJCNN 2016
Training a Hidden Markov Model with a Bayesian Spiking Neural Network
Jul 20, 2016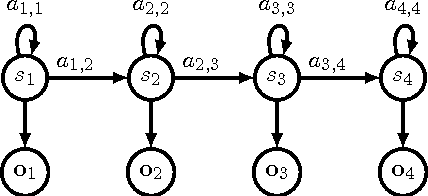
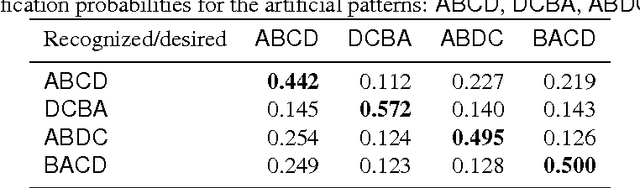
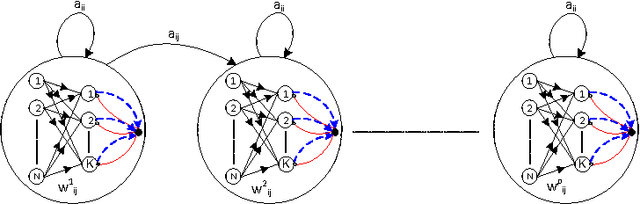
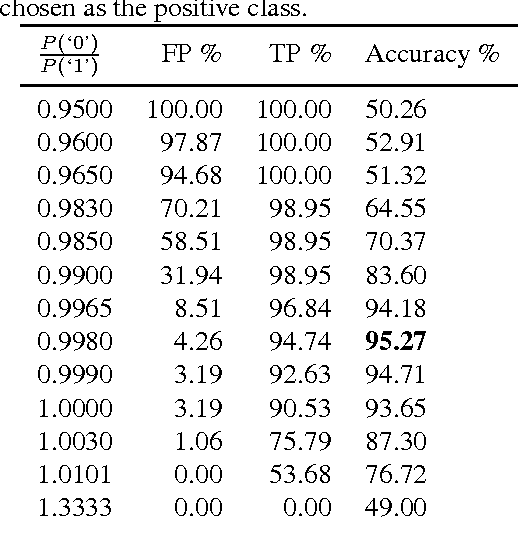
It is of some interest to understand how statistically based mechanisms for signal processing might be integrated with biologically motivated mechanisms such as neural networks. This paper explores a novel hybrid approach for classifying segments of sequential data, such as individual spoken works. The approach combines a hidden Markov model (HMM) with a spiking neural network (SNN). The HMM, consisting of states and transitions, forms a fixed backbone with nonadaptive transition probabilities. The SNN, however, implements a biologically based Bayesian computation that derives from the spike timing-dependent plasticity (STDP) learning rule. The emission (observation) probabilities of the HMM are represented in the SNN and trained with the STDP rule. A separate SNN, each with the same architecture, is associated with each of the states of the HMM. Because of the STDP training, each SNN implements an expectation maximization algorithm to learn the emission probabilities for one HMM state. The model was studied on synthesized spike-train data and also on spoken word data. Preliminary results suggest its performance compares favorably with other biologically motivated approaches. Because of the model's uniqueness and initial promise, it warrants further study. It provides some new ideas on how the brain might implement the equivalent of an HMM in a neural circuit.
* Bayesian Spiking Neural Network, Revision submitted: April-27-2016