 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning in Spiking Neural Networks
Sep 01, 2018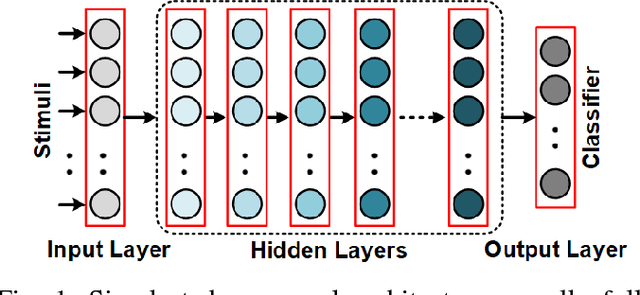
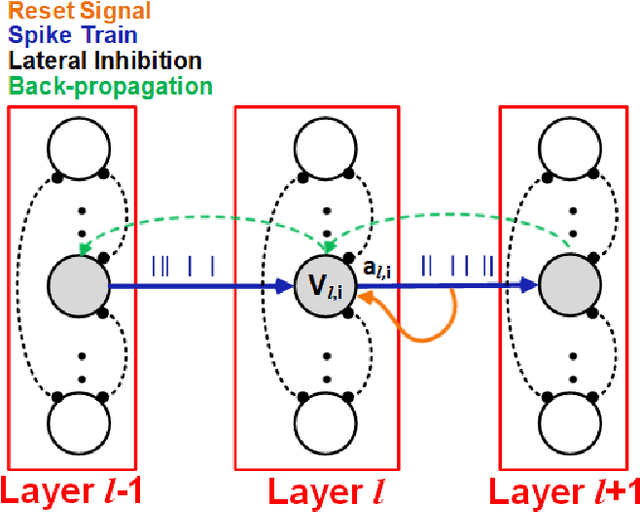
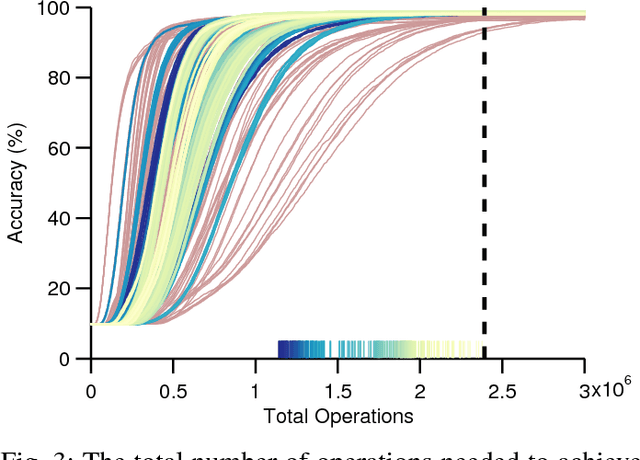
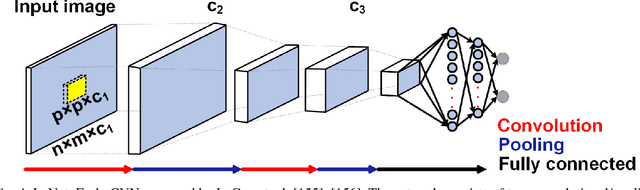
In recent years, deep learning has been a revolution in the field of machine learning, for computer vision in particular. In this approach, a deep (multilayer) artificial neural network (ANN) is trained in a supervised manner using backpropagation. Huge amounts of labeled examples are required, but the resulting classification accuracy is truly impressive, sometimes outperforming humans. Neurons in an ANN are characterized by a single, static, continuous-valued activation. Yet biological neurons use discrete spikes to compute and transmit information, and the spike times, in addition to the spike rates, matter. Spiking neural networks (SNNs) are thus more biologically realistic than ANNs, and arguably the only viable option if one wants to understand how the brain computes. SNNs are also more hardware friendly and energy-efficient than ANNs, and are thus appealing for technology, especially for portable devices. However, training deep SNNs remains a challenge. Spiking neurons' transfer function is usually non-differentiable, which prevents using backpropagation. Here we review recent supervised and unsupervised methods to train deep SNNs, and compare them in terms of accuracy, but also computational cost and hardware friendliness. The emerging picture is that SNNs still lag behind ANNs in terms of accuracy, but the gap is decreasing, and can even vanish on some tasks, while the SNNs typically require much fewer operations.
A specialized face-processing network consistent with the representational geometry of monkey face patches
Oct 30, 2016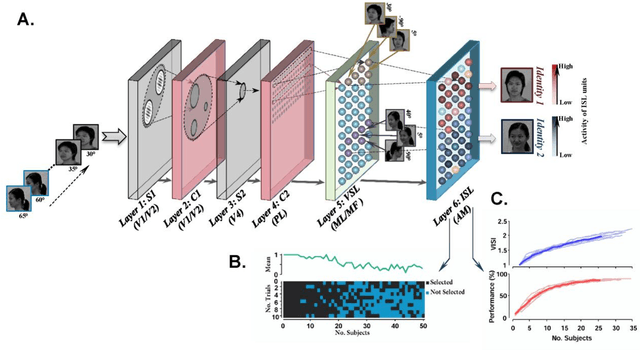
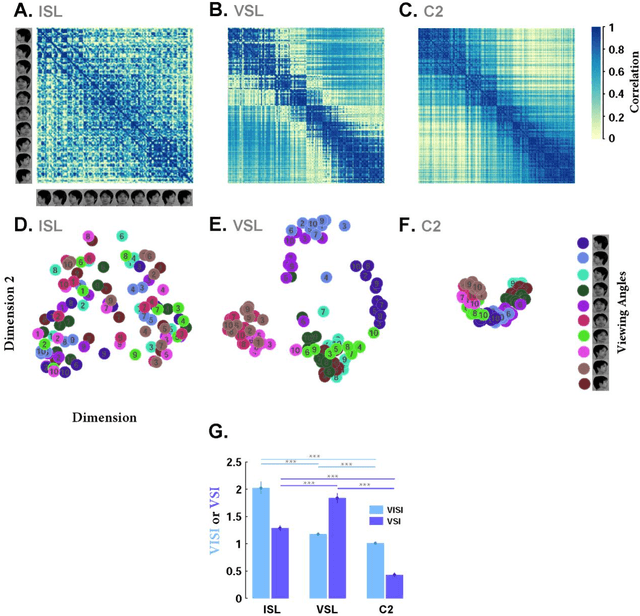
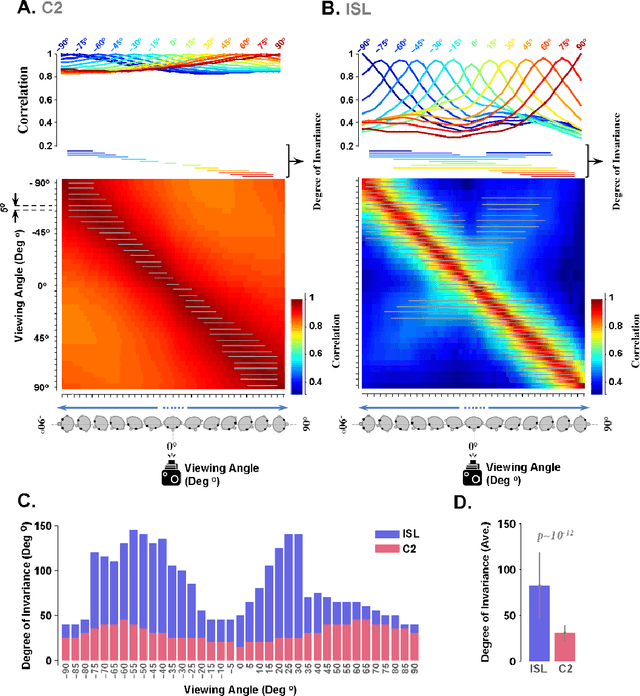
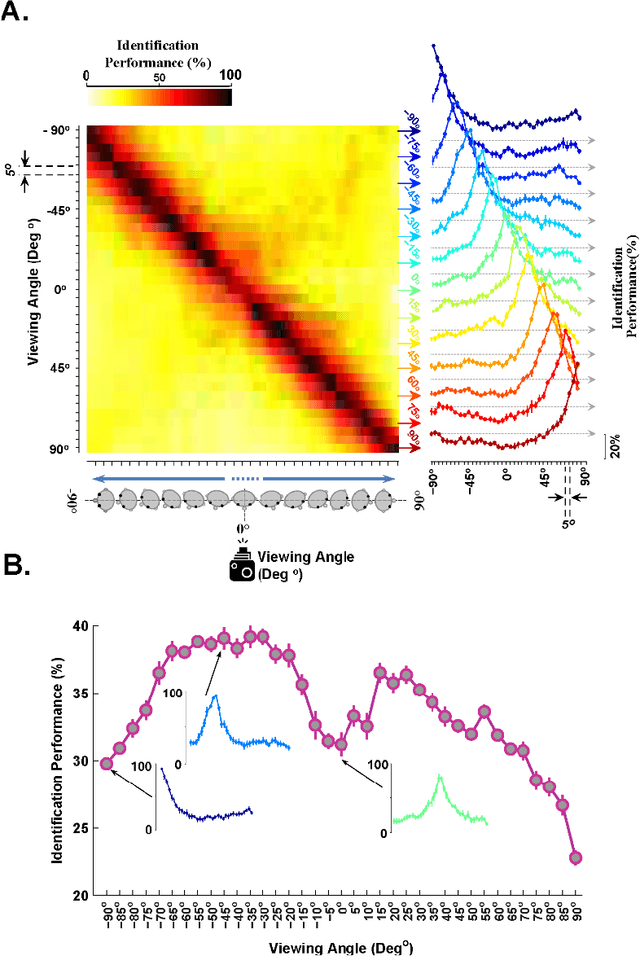
Ample evidence suggests that face processing in human and non-human primates is performed differently compared with other objects. Converging reports, both physiologically and psychophysically, indicate that faces are processed in specialized neural networks in the brain -i.e. face patches in monkeys and the fusiform face area (FFA) in humans. We are all expert face-processing agents, and able to identify very subtle differences within the category of faces, despite substantial visual and featural similarities. Identification is performed rapidly and accurately after viewing a whole face, while significantly drops if some of the face configurations (e.g. inversion, misalignment) are manipulated or if partial views of faces are shown due to occlusion. This refers to a hotly-debated, yet highly-supported concept, known as holistic face processing. We built a hierarchical computational model of face-processing based on evidence from recent neuronal and behavioural studies on faces processing in primates. Representational geometries of the last three layers of the model have characteristics similar to those observed in monkey face patches (posterior, middle and anterior patches). Furthermore, several face-processing-related phenomena reported in the literature automatically emerge as properties of this model. The representations are evolved through several computational layers, using biologically plausible learning rules. The model satisfies face inversion effect, composite face effect, other race effect, view and identity selectivity, and canonical face views. To our knowledge, no models have so far been proposed with this performance and agreement with biological data.
Deep Networks Can Resemble Human Feed-forward Vision in Invariant Object Recognition
Jun 28, 2016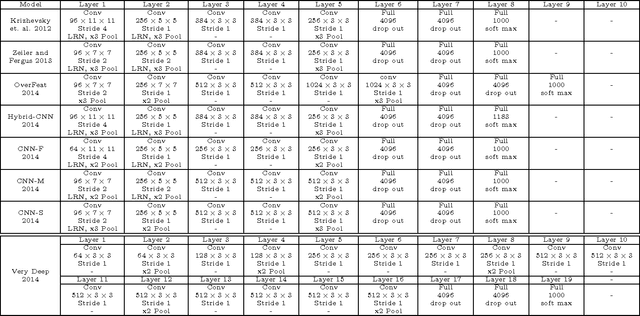

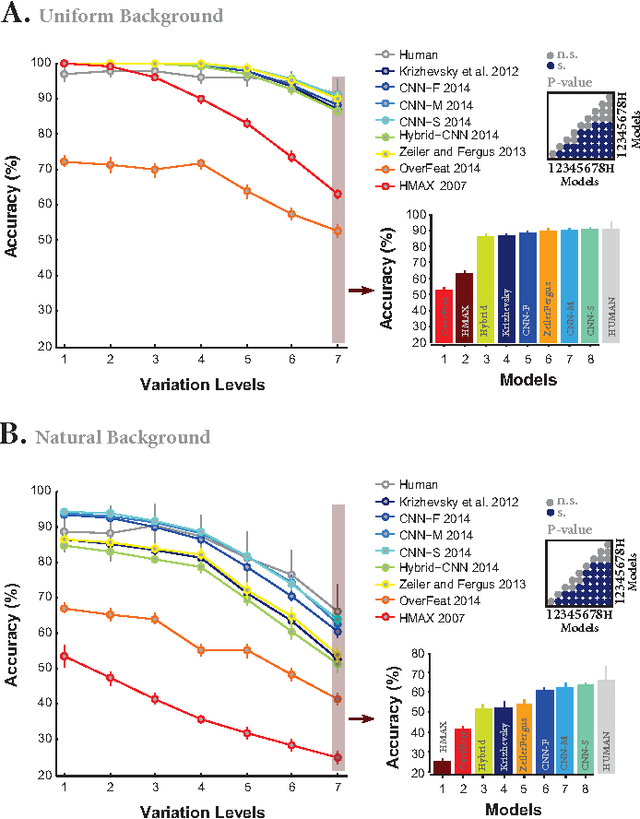
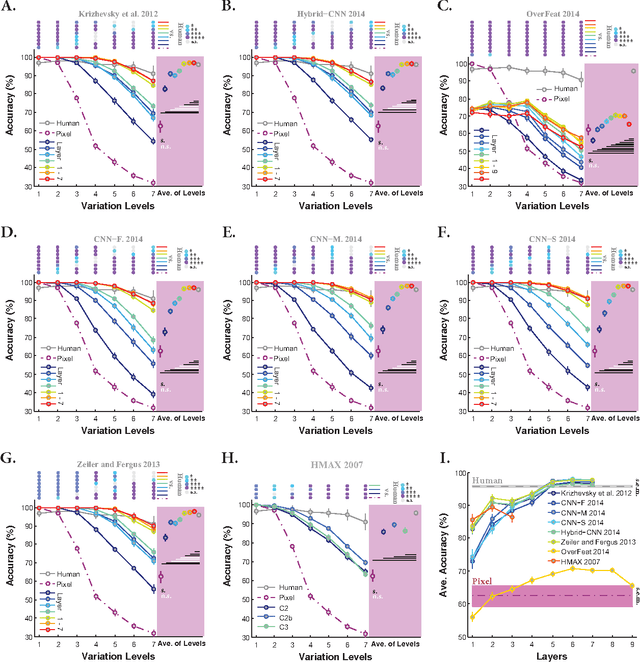
Deep convolutional neural networks (DCNNs) have attracted much attention recently, and have shown to be able to recognize thousands of object categories in natural image databases. Their architecture is somewhat similar to that of the human visual system: both use restricted receptive fields, and a hierarchy of layers which progressively extract more and more abstracted features. Yet it is unknown whether DCNNs match human performance at the task of view-invariant object recognition, whether they make similar errors and use similar representations for this task, and whether the answers depend on the magnitude of the viewpoint variations. To investigate these issues, we benchmarked eight state-of-the-art DCNNs, the HMAX model, and a baseline shallow model and compared their results to those of humans with backward masking. Unlike in all previous DCNN studies, we carefully controlled the magnitude of the viewpoint variations to demonstrate that shallow nets can outperform deep nets and humans when variations are weak. When facing larger variations, however, more layers were needed to match human performance and error distributions, and to have representations that are consistent with human behavior. A very deep net with 18 layers even outperformed humans at the highest variation level, using the most human-like representations.
Humans and deep networks largely agree on which kinds of variation make object recognition harder
Apr 21, 2016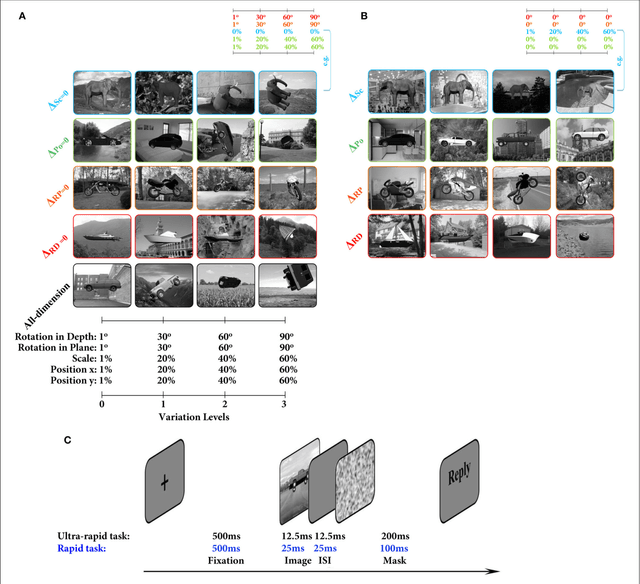

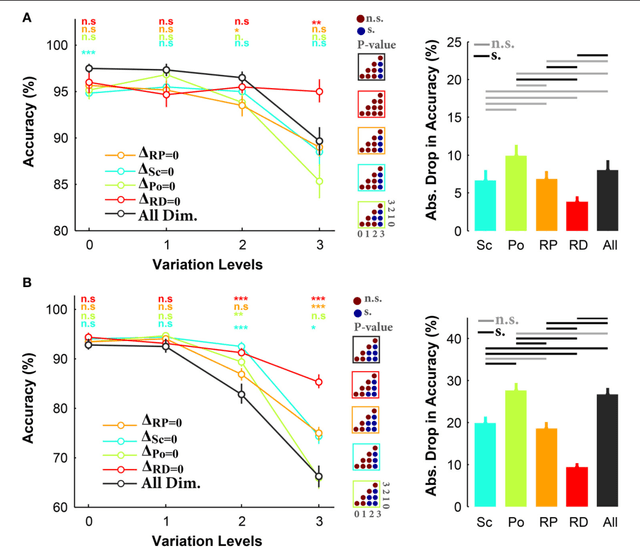
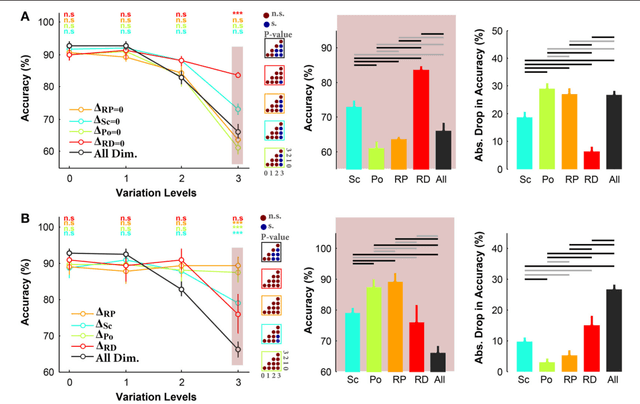
View-invariant object recognition is a challenging problem, which has attracted much attention among the psychology, neuroscience, and computer vision communities. Humans are notoriously good at it, even if some variations are presumably more difficult to handle than others (e.g. 3D rotations). Humans are thought to solve the problem through hierarchical processing along the ventral stream, which progressively extracts more and more invariant visual features. This feed-forward architecture has inspired a new generation of bio-inspired computer vision systems called deep convolutional neural networks (DCNN), which are currently the best algorithms for object recognition in natural images. Here, for the first time, we systematically compared human feed-forward vision and DCNNs at view-invariant object recognition using the same images and controlling for both the kinds of transformation as well as their magnitude. We used four object categories and images were rendered from 3D computer models. In total, 89 human subjects participated in 10 experiments in which they had to discriminate between two or four categories after rapid presentation with backward masking. We also tested two recent DCNNs on the same tasks. We found that humans and DCNNs largely agreed on the relative difficulties of each kind of variation: rotation in depth is by far the hardest transformation to handle, followed by scale, then rotation in plane, and finally position. This suggests that humans recognize objects mainly through 2D template matching, rather than by constructing 3D object models, and that DCNNs are not too unreasonable models of human feed-forward vision. Also, our results show that the variation levels in rotation in depth and scale strongly modulate both humans' and DCNNs' recognition performances. We thus argue that these variations should be controlled in the image datasets used in vision research.