 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Natural Language to SQL: Review of LLM-based Text-to-SQL Systems
Oct 01, 2024

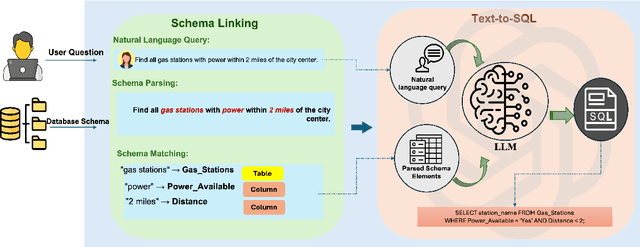

Since the onset of LLMs, translating natural language queries to structured SQL commands is assuming increasing. Unlike the previous reviews, this survey provides a comprehensive study of the evolution of LLM-based text-to-SQL systems, from early rule-based models to advanced LLM approaches, and how LLMs impacted this field. We discuss benchmarks, evaluation methods and evaluation metrics. Also, we uniquely study the role of integration of knowledge graphs for better contextual accuracy and schema linking in these systems. The current techniques fall into two categories: in-context learning of corpus and fine-tuning, which then leads to approaches such as zero-shot, few-shot learning from the end, and data augmentation. Finally, we highlight key challenges such as computational efficiency, model robustness, and data privacy with perspectives toward their development and improvements in potential areas for future of LLM-based text-to-SQL system.
LiteLSTM Architecture Based on Weights Sharing for Recurrent Neural Networks
Jan 12, 2023Long short-term memory (LSTM) is one of the robust recurrent neural network architectures for learning sequential data. However, it requires considerable computational power to learn and implement both software and hardware aspects. This paper proposed a novel LiteLSTM architecture based on reducing the LSTM computation components via the weights sharing concept to reduce the overall architecture computation cost and maintain the architecture performance. The proposed LiteLSTM can be significant for processing large data where time-consuming is crucial while hardware resources are limited, such as the security of IoT devices and medical data processing. The proposed model was evaluated and tested empirically on three different datasets from the computer vision, cybersecurity, speech emotion recognition domains. The proposed LiteLSTM has comparable accuracy to the other state-of-the-art recurrent architecture while using a smaller computation budget.
Enhancing ResNet Image Classification Performance by using Parameterized Hypercomplex Multiplication
Jan 11, 2023Recently, many deep networks have introduced hypercomplex and related calculations into their architectures. In regard to convolutional networks for classification, these enhancements have been applied to the convolution operations in the frontend to enhance accuracy and/or reduce the parameter requirements while maintaining accuracy. Although these enhancements have been applied to the convolutional frontend, it has not been studied whether adding hypercomplex calculations improves performance when applied to the densely connected backend. This paper studies ResNet architectures and incorporates parameterized hypercomplex multiplication (PHM) into the backend of residual, quaternion, and vectormap convolutional neural networks to assess the effect. We show that PHM does improve classification accuracy performance on several image datasets, including small, low-resolution CIFAR 10/100 and large high-resolution ImageNet and ASL, and can achieve state-of-the-art accuracy for hypercomplex networks.
Deep Residual Axial Networks
Jan 11, 2023



While residual networks (ResNets) demonstrate outstanding performance on computer vision tasks, their computational cost still remains high. Here, we focus on reducing this cost by proposing a new network architecture, axial ResNet, which replaces spatial 2D convolution operations with two consecutive 1D convolution operations. Convergence of very deep axial ResNets has faced degradation problems which prevent the networks from performing efficiently. To mitigate this, we apply a residual connection to each 1D convolutional operation and propose our final novel architecture namely residual axial networks (RANs). Extensive benchmark evaluation shows that RANs outperform with about 49% fewer parameters than ResNets on CIFAR benchmarks, SVHN, and Tiny ImageNet image classification datasets. Moreover, our proposed RANs show significant improvement in validation performance in comparison to the wide ResNets on CIFAR benchmarks and the deep recursive residual networks on image super-resolution dataset.
Deep Axial Hypercomplex Networks
Jan 11, 2023



Over the past decade, deep hypercomplex-inspired networks have enhanced feature extraction for image classification by enabling weight sharing across input channels. Recent works make it possible to improve representational capabilities by using hypercomplex-inspired networks which consume high computational costs. This paper reduces this cost by factorizing a quaternion 2D convolutional module into two consecutive vectormap 1D convolutional modules. Also, we use 5D parameterized hypercomplex multiplication based fully connected layers. Incorporating both yields our proposed hypercomplex network, a novel architecture that can be assembled to construct deep axial-hypercomplex networks (DANs) for image classifications. We conduct experiments on CIFAR benchmarks, SVHN, and Tiny ImageNet datasets and achieve better performance with fewer trainable parameters and FLOPS. Our proposed model achieves almost 2% higher performance for CIFAR and SVHN datasets, and more than 3% for the ImageNet-Tiny dataset and takes six times fewer parameters than the real-valued ResNets. Also, it shows state-of-the-art performance on CIFAR benchmarks in hypercomplex space.
Vision-Based American Sign Language Classification Approach via Deep Learning
Apr 08, 2022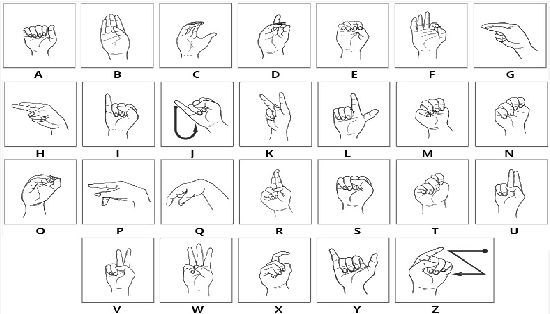

Hearing-impaired is the disability of partial or total hearing loss that causes a significant problem for communication with other people in society. American Sign Language (ASL) is one of the sign languages that most commonly used language used by Hearing impaired communities to communicate with each other. In this paper, we proposed a simple deep learning model that aims to classify the American Sign Language letters as a step in a path for removing communication barriers that are related to disabilities.
LiteLSTM Architecture for Deep Recurrent Neural Networks
Jan 27, 2022
Long short-term memory (LSTM) is a robust recurrent neural network architecture for learning spatiotemporal sequential data. However, it requires significant computational power for learning and implementing from both software and hardware aspects. This paper proposes a novel LiteLSTM architecture based on reducing the computation components of the LSTM using the weights sharing concept to reduce the overall architecture cost and maintain the architecture performance. The proposed LiteLSTM can be significant for learning big data where time-consumption is crucial such as the security of IoT devices and medical data. Moreover, it helps to reduce the CO2 footprint. The proposed model was evaluated and tested empirically on two different datasets from computer vision and cybersecurity domains.
Adding Quaternion Representations to Attention Networks for Classification
Oct 04, 2021
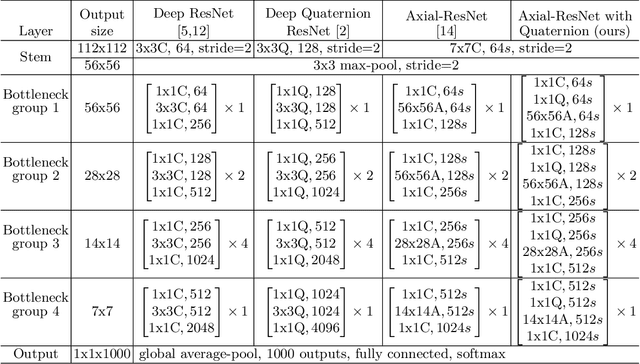
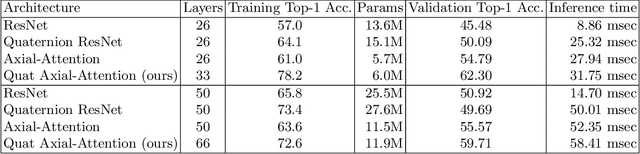

This paper introduces a novel modification to axial-attention networks to improve their image classification accuracy. The modification involves supplementing axial-attention modules with quaternion input representations to improve image classification accuracy. We chose axial-attention networks because they factor 2D attention operations into two consecutive 1D operations (similar to separable convolution) and are thus less resource intensive than non-axial attention networks. We chose a quaternion encoder because of they share weights across four real-valued input channels and the weight-sharing has been shown to produce a more interlinked/interwoven output representation. We hypothesize that an attention module can be more effective using these interlinked representations as input. Our experiments support this hypothesis as reflected in the improved classification accuracy compared to standard axial-attention networks. We think this happens because the attention modules have better input representations to work with.
Inception-inspired LSTM for Next-frame Video Prediction
Aug 28, 2019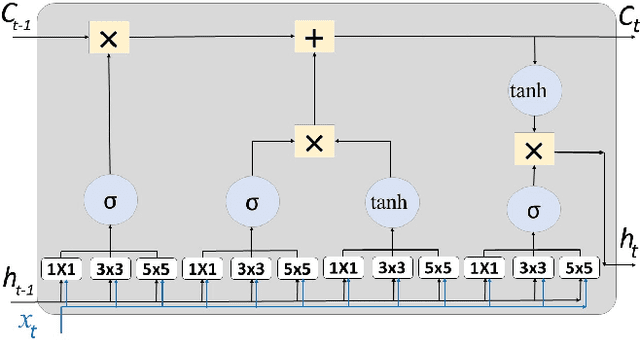
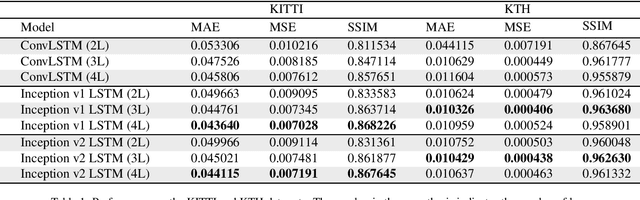
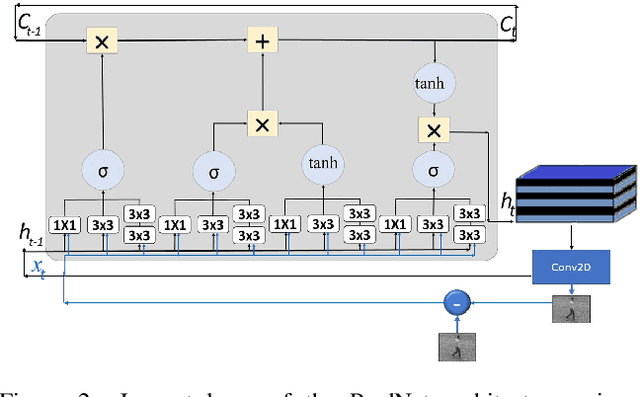

The problem of video frame prediction has received much interest due to its relevance to many computer vision applications such as autonomous vehicles or robotics. Supervised methods for video frame prediction rely on labeled data, which may not always be available. In this paper, we provide a novel unsupervised deep-learning method called Inception-based LSTM for video frame prediction. The general idea of inception networks is to implement wider networks instead of deeper networks. This network design was shown to improve the performance of image classification. The proposed method is evaluated on both Inception-v1 and Inception-v2 structures. The proposed Inception LSTM methods are compared with convolutional LSTM when applied using PredNet predictive coding framework for both the KITTI and KTH data sets. We observed that the Inception based LSTM outperforms the convolutional LSTM. Also, Inception LSTM has better prediction performance compared to Inception v2 LSTM. However, Inception v2 LSTM has a lower computational cost compared to Inception LSTM.
Deep Gated Recurrent and Convolutional Network Hybrid Model for Univariate Time Series Classification
Dec 27, 2018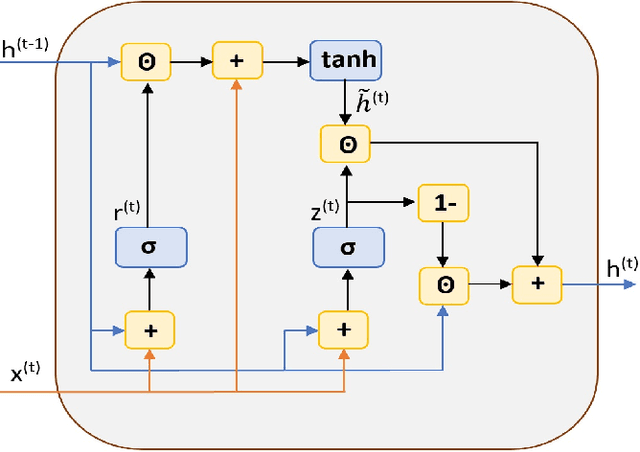
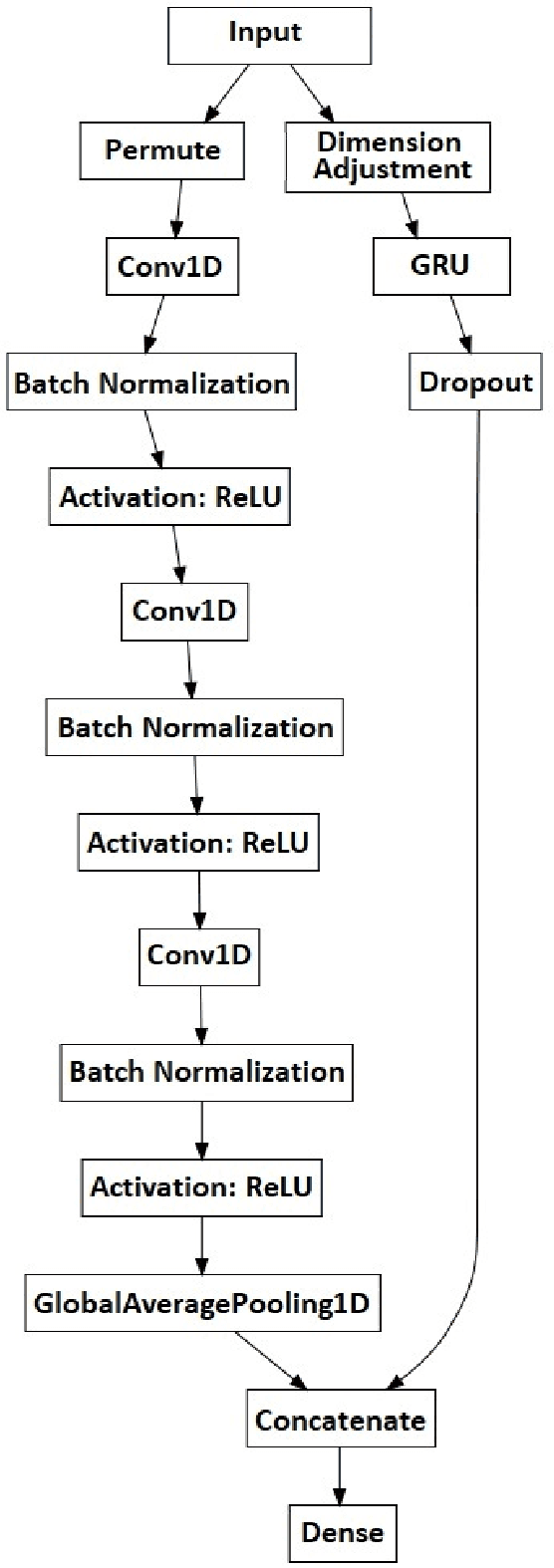
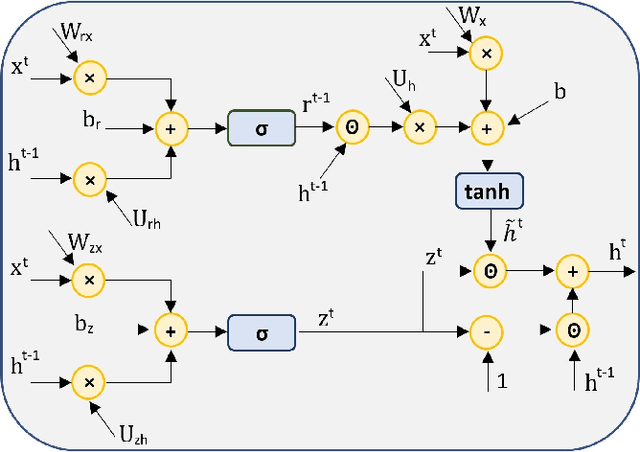
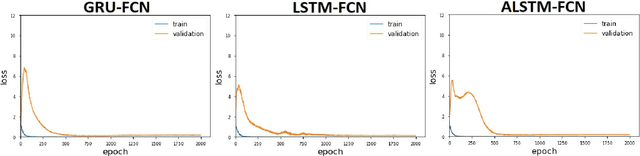
Hybrid LSTM-fully convolutional networks (LSTM-FCN) for time series classification have produced state-of-the-art classification results on univariate time series. We show that replacing the LSTM with a gated recurrent unit (GRU) to create a GRU-fully convolutional network hybrid model (GRU-FCN) can offer even better performance on many time series datasets. The proposed GRU-FCN model outperforms state-of-the-art classification performance in many univariate and multivariate time series datasets. In addition, since the GRU uses a simpler architecture than the LSTM, it has fewer training parameters, less training time, and a simpler hardware implementation, compared to the LSTM-based models.