 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Intermediate Fusion Network with Manifold Learning for Stress Detection
Mar 12, 2024Multimodal deep learning methods capture synergistic features from multiple modalities and have the potential to improve accuracy for stress detection compared to unimodal methods. However, this accuracy gain typically comes from high computational cost due to the high-dimensional feature spaces, especially for intermediate fusion. Dimensionality reduction is one way to optimize multimodal learning by simplifying data and making the features more amenable to processing and analysis, thereby reducing computational complexity. This paper introduces an intermediate multimodal fusion network with manifold learning-based dimensionality reduction. The multimodal network generates independent representations from biometric signals and facial landmarks through 1D-CNN and 2D-CNN. Finally, these features are fused and fed to another 1D-CNN layer, followed by a fully connected dense layer. We compared various dimensionality reduction techniques for different variations of unimodal and multimodal networks. We observe that the intermediate-level fusion with the Multi-Dimensional Scaling (MDS) manifold method showed promising results with an accuracy of 96.00\% in a Leave-One-Subject-Out Cross-Validation (LOSO-CV) paradigm over other dimensional reduction methods. MDS had the highest computational cost among manifold learning methods. However, while outperforming other networks, it managed to reduce the computational cost of the proposed networks by 25\% when compared to six well-known conventional feature selection methods used in the preprocessing step.
Multimodal Stress Detection Using Facial Landmarks and Biometric Signals
Nov 06, 2023


The development of various sensing technologies is improving measurements of stress and the well-being of individuals. Although progress has been made with single signal modalities like wearables and facial emotion recognition, integrating multiple modalities provides a more comprehensive understanding of stress, given that stress manifests differently across different people. Multi-modal learning aims to capitalize on the strength of each modality rather than relying on a single signal. Given the complexity of processing and integrating high-dimensional data from limited subjects, more research is needed. Numerous research efforts have been focused on fusing stress and emotion signals at an early stage, e.g., feature-level fusion using basic machine learning methods and 1D-CNN Methods. This paper proposes a multi-modal learning approach for stress detection that integrates facial landmarks and biometric signals. We test this multi-modal integration with various early-fusion and late-fusion techniques to integrate the 1D-CNN model from biometric signals and 2-D CNN using facial landmarks. We evaluate these architectures using a rigorous test of models' generalizability using the leave-one-subject-out mechanism, i.e., all samples related to a single subject are left out to train the model. Our findings show that late-fusion achieved 94.39\% accuracy, and early-fusion surpassed it with a 98.38\% accuracy rate. This research contributes valuable insights into enhancing stress detection through a multi-modal approach. The proposed research offers important knowledge in improving stress detection using a multi-modal approach.
Inception-inspired LSTM for Next-frame Video Prediction
Aug 28, 2019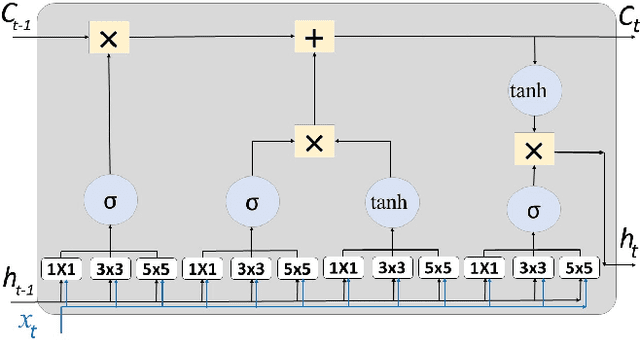
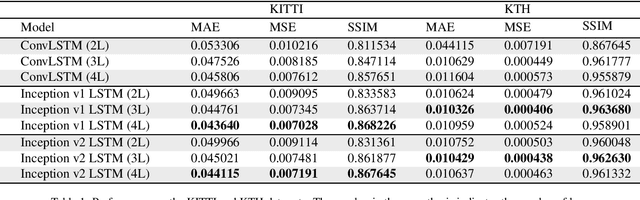
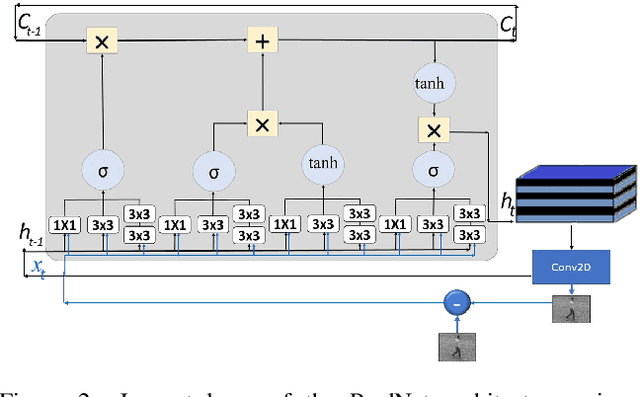

The problem of video frame prediction has received much interest due to its relevance to many computer vision applications such as autonomous vehicles or robotics. Supervised methods for video frame prediction rely on labeled data, which may not always be available. In this paper, we provide a novel unsupervised deep-learning method called Inception-based LSTM for video frame prediction. The general idea of inception networks is to implement wider networks instead of deeper networks. This network design was shown to improve the performance of image classification. The proposed method is evaluated on both Inception-v1 and Inception-v2 structures. The proposed Inception LSTM methods are compared with convolutional LSTM when applied using PredNet predictive coding framework for both the KITTI and KTH data sets. We observed that the Inception based LSTM outperforms the convolutional LSTM. Also, Inception LSTM has better prediction performance compared to Inception v2 LSTM. However, Inception v2 LSTM has a lower computational cost compared to Inception LSTM.