 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Stress Detection Using Facial Landmarks and Biometric Signals
Nov 06, 2023

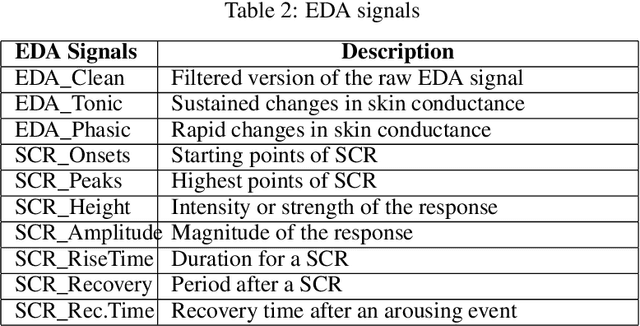

The development of various sensing technologies is improving measurements of stress and the well-being of individuals. Although progress has been made with single signal modalities like wearables and facial emotion recognition, integrating multiple modalities provides a more comprehensive understanding of stress, given that stress manifests differently across different people. Multi-modal learning aims to capitalize on the strength of each modality rather than relying on a single signal. Given the complexity of processing and integrating high-dimensional data from limited subjects, more research is needed. Numerous research efforts have been focused on fusing stress and emotion signals at an early stage, e.g., feature-level fusion using basic machine learning methods and 1D-CNN Methods. This paper proposes a multi-modal learning approach for stress detection that integrates facial landmarks and biometric signals. We test this multi-modal integration with various early-fusion and late-fusion techniques to integrate the 1D-CNN model from biometric signals and 2-D CNN using facial landmarks. We evaluate these architectures using a rigorous test of models' generalizability using the leave-one-subject-out mechanism, i.e., all samples related to a single subject are left out to train the model. Our findings show that late-fusion achieved 94.39\% accuracy, and early-fusion surpassed it with a 98.38\% accuracy rate. This research contributes valuable insights into enhancing stress detection through a multi-modal approach. The proposed research offers important knowledge in improving stress detection using a multi-modal approach.
Hierarchical Predictive Coding Models in a Deep-Learning Framework
May 07, 2020
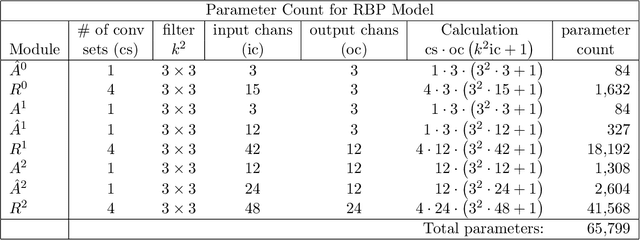
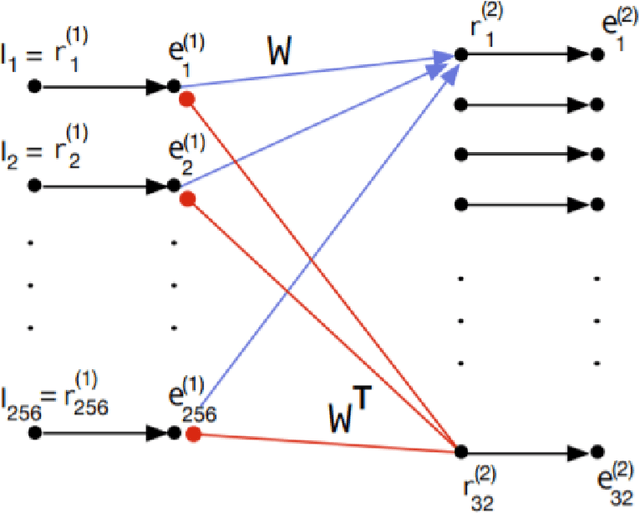
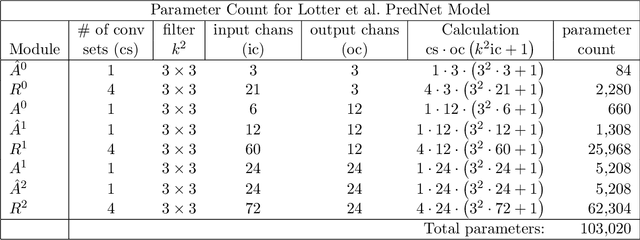
Bayesian predictive coding is a putative neuromorphic method for acquiring higher-level neural representations to account for sensory input. Although originating in the neuroscience community, there are also efforts in the machine learning community to study these models. This paper reviews some of the more well known models. Our review analyzes module connectivity and patterns of information transfer, seeking to find general principles used across the models. We also survey some recent attempts to cast these models within a deep learning framework. A defining feature of Bayesian predictive coding is that it uses top-down, reconstructive mechanisms to predict incoming sensory inputs or their lower-level representations. Discrepancies between the predicted and the actual inputs, known as prediction errors, then give rise to future learning that refines and improves the predictive accuracy of learned higher-level representations. Predictive coding models intended to describe computations in the neocortex emerged prior to the development of deep learning and used a communication structure between modules that we name the Rao-Ballard protocol. This protocol was derived from a Bayesian generative model with some rather strong statistical assumptions. The RB protocol provides a rubric to assess the fidelity of deep learning models that claim to implement predictive coding.
Deep Quaternion Networks
Jul 29, 2018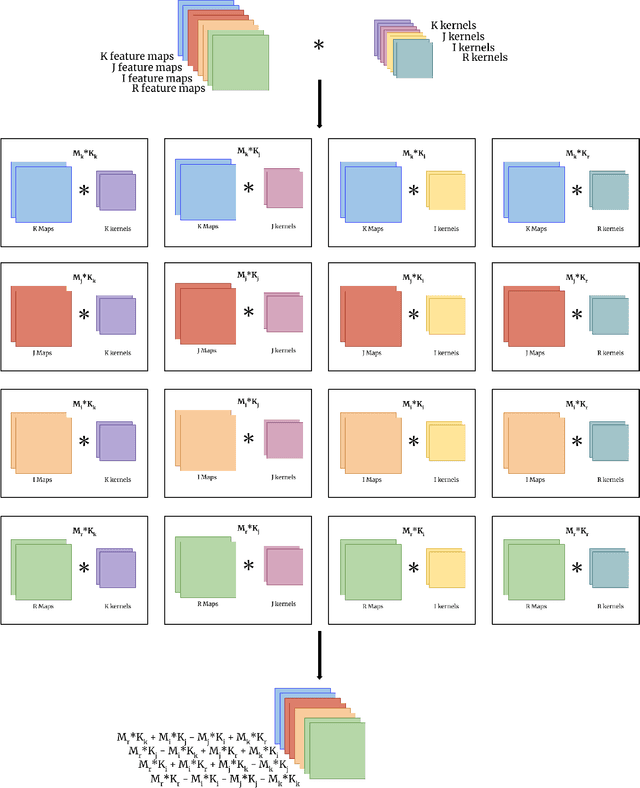

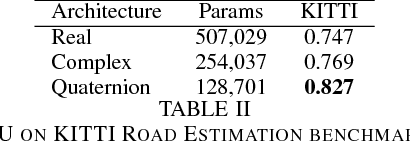
The field of deep learning has seen significant advancement in recent years. However, much of the existing work has been focused on real-valued numbers. Recent work has shown that a deep learning system using the complex numbers can be deeper for a fixed parameter budget compared to its real-valued counterpart. In this work, we explore the benefits of generalizing one step further into the hyper-complex numbers, quaternions specifically, and provide the architecture components needed to build deep quaternion networks. We develop the theoretical basis by reviewing quaternion convolutions, developing a novel quaternion weight initialization scheme, and developing novel algorithms for quaternion batch-normalization. These pieces are tested in a classification model by end-to-end training on the CIFAR-10 and CIFAR-100 data sets and a segmentation model by end-to-end training on the KITTI Road Segmentation data set. These quaternion networks show improved convergence compared to real-valued and complex-valued networks, especially on the segmentation task, while having fewer parameters
Representation Learning using Event-based STDP
Mar 09, 2018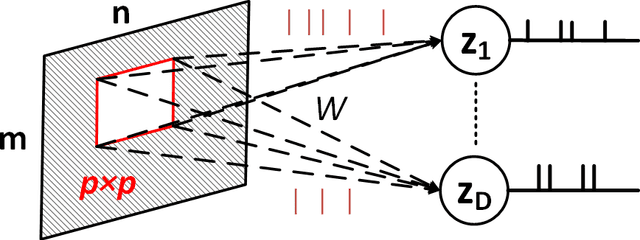


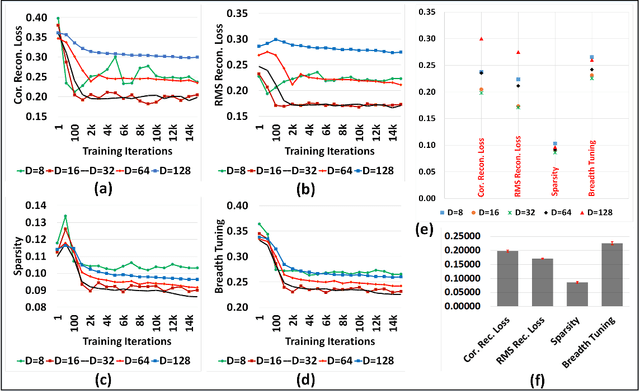
Although representation learning methods developed within the framework of traditional neural networks are relatively mature, developing a spiking representation model remains a challenging problem. This paper proposes an event-based method to train a feedforward spiking neural network (SNN) layer for extracting visual features. The method introduces a novel spike-timing-dependent plasticity (STDP) learning rule and a threshold adjustment rule both derived from a vector quantization-like objective function subject to a sparsity constraint. The STDP rule is obtained by the gradient of a vector quantization criterion that is converted to spike-based, spatio-temporally local update rules in a spiking network of leaky, integrate-and-fire (LIF) neurons. Independence and sparsity of the model are achieved by the threshold adjustment rule and by a softmax function implementing inhibition in the representation layer consisting of WTA-thresholded spiking neurons. Together, these mechanisms implement a form of spike-based, competitive learning. Two sets of experiments are performed on the MNIST and natural image datasets. The results demonstrate a sparse spiking visual representation model with low reconstruction loss comparable with state-of-the-art visual coding approaches, yet our rule is local in both time and space, thus biologically plausible and hardware friendly.
Bio-Inspired Multi-Layer Spiking Neural Network Extracts Discriminative Features from Speech Signals
Jun 10, 2017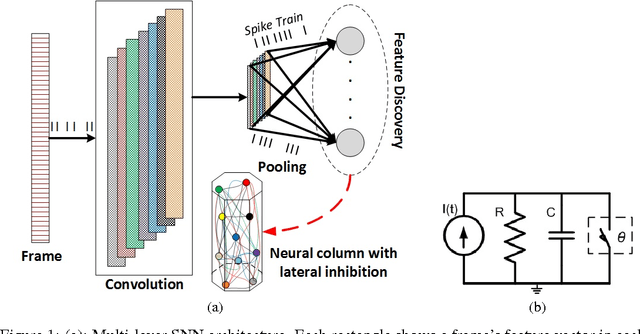

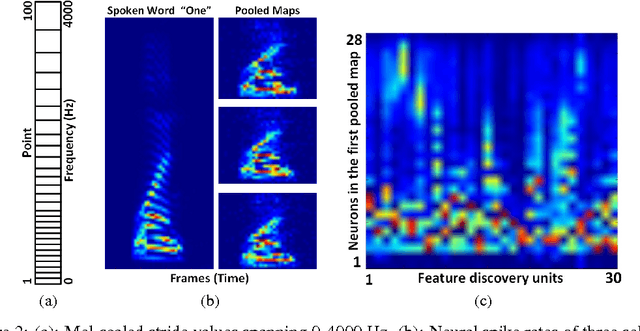

Spiking neural networks (SNNs) enable power-efficient implementations due to their sparse, spike-based coding scheme. This paper develops a bio-inspired SNN that uses unsupervised learning to extract discriminative features from speech signals, which can subsequently be used in a classifier. The architecture consists of a spiking convolutional/pooling layer followed by a fully connected spiking layer for feature discovery. The convolutional layer of leaky, integrate-and-fire (LIF) neurons represents primary acoustic features. The fully connected layer is equipped with a probabilistic spike-timing-dependent plasticity learning rule. This layer represents the discriminative features through probabilistic, LIF neurons. To assess the discriminative power of the learned features, they are used in a hidden Markov model (HMM) for spoken digit recognition. The experimental results show performance above 96% that compares favorably with popular statistical feature extraction methods. Our results provide a novel demonstration of unsupervised feature acquisition in an SNN.