 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Stress Detection Using Facial Landmarks and Biometric Signals
Paper and Code
Nov 06, 2023

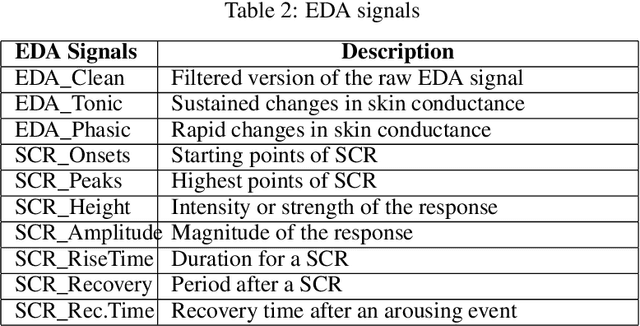

The development of various sensing technologies is improving measurements of stress and the well-being of individuals. Although progress has been made with single signal modalities like wearables and facial emotion recognition, integrating multiple modalities provides a more comprehensive understanding of stress, given that stress manifests differently across different people. Multi-modal learning aims to capitalize on the strength of each modality rather than relying on a single signal. Given the complexity of processing and integrating high-dimensional data from limited subjects, more research is needed. Numerous research efforts have been focused on fusing stress and emotion signals at an early stage, e.g., feature-level fusion using basic machine learning methods and 1D-CNN Methods. This paper proposes a multi-modal learning approach for stress detection that integrates facial landmarks and biometric signals. We test this multi-modal integration with various early-fusion and late-fusion techniques to integrate the 1D-CNN model from biometric signals and 2-D CNN using facial landmarks. We evaluate these architectures using a rigorous test of models' generalizability using the leave-one-subject-out mechanism, i.e., all samples related to a single subject are left out to train the model. Our findings show that late-fusion achieved 94.39\% accuracy, and early-fusion surpassed it with a 98.38\% accuracy rate. This research contributes valuable insights into enhancing stress detection through a multi-modal approach. The proposed research offers important knowledge in improving stress detection using a multi-modal approach.