 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransFair: Transferring Fairness from Ocular Disease Classification to Progression Prediction
Dec 03, 2024



The use of artificial intelligence (AI) in automated disease classification significantly reduces healthcare costs and improves the accessibility of services. However, this transformation has given rise to concerns about the fairness of AI, which disproportionately affects certain groups, particularly patients from underprivileged populations. Recently, a number of methods and large-scale datasets have been proposed to address group performance disparities. Although these methods have shown effectiveness in disease classification tasks, they may fall short in ensuring fair prediction of disease progression, mainly because of limited longitudinal data with diverse demographics available for training a robust and equitable prediction model. In this paper, we introduce TransFair to enhance demographic fairness in progression prediction for ocular diseases. TransFair aims to transfer a fairness-enhanced disease classification model to the task of progression prediction with fairness preserved. Specifically, we train a fair EfficientNet, termed FairEN, equipped with a fairness-aware attention mechanism using extensive data for ocular disease classification. Subsequently, this fair classification model is adapted to a fair progression prediction model through knowledge distillation, which aims to minimize the latent feature distances between the classification and progression prediction models. We evaluate FairEN and TransFair for fairness-enhanced ocular disease classification and progression prediction using both two-dimensional (2D) and 3D retinal images. Extensive experiments and comparisons with models with and without considering fairness learning show that TransFair effectively enhances demographic equity in predicting ocular disease progression.
From Natural Language to SQL: Review of LLM-based Text-to-SQL Systems
Oct 01, 2024

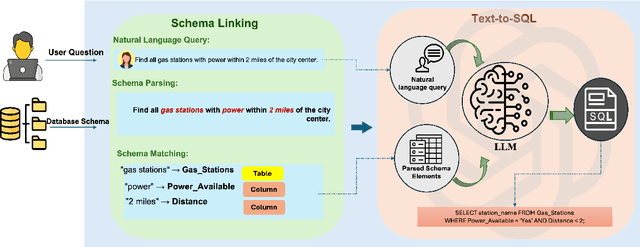

Since the onset of LLMs, translating natural language queries to structured SQL commands is assuming increasing. Unlike the previous reviews, this survey provides a comprehensive study of the evolution of LLM-based text-to-SQL systems, from early rule-based models to advanced LLM approaches, and how LLMs impacted this field. We discuss benchmarks, evaluation methods and evaluation metrics. Also, we uniquely study the role of integration of knowledge graphs for better contextual accuracy and schema linking in these systems. The current techniques fall into two categories: in-context learning of corpus and fine-tuning, which then leads to approaches such as zero-shot, few-shot learning from the end, and data augmentation. Finally, we highlight key challenges such as computational efficiency, model robustness, and data privacy with perspectives toward their development and improvements in potential areas for future of LLM-based text-to-SQL system.
A Multimodal Intermediate Fusion Network with Manifold Learning for Stress Detection
Mar 12, 2024Multimodal deep learning methods capture synergistic features from multiple modalities and have the potential to improve accuracy for stress detection compared to unimodal methods. However, this accuracy gain typically comes from high computational cost due to the high-dimensional feature spaces, especially for intermediate fusion. Dimensionality reduction is one way to optimize multimodal learning by simplifying data and making the features more amenable to processing and analysis, thereby reducing computational complexity. This paper introduces an intermediate multimodal fusion network with manifold learning-based dimensionality reduction. The multimodal network generates independent representations from biometric signals and facial landmarks through 1D-CNN and 2D-CNN. Finally, these features are fused and fed to another 1D-CNN layer, followed by a fully connected dense layer. We compared various dimensionality reduction techniques for different variations of unimodal and multimodal networks. We observe that the intermediate-level fusion with the Multi-Dimensional Scaling (MDS) manifold method showed promising results with an accuracy of 96.00\% in a Leave-One-Subject-Out Cross-Validation (LOSO-CV) paradigm over other dimensional reduction methods. MDS had the highest computational cost among manifold learning methods. However, while outperforming other networks, it managed to reduce the computational cost of the proposed networks by 25\% when compared to six well-known conventional feature selection methods used in the preprocessing step.
Multimodal Stress Detection Using Facial Landmarks and Biometric Signals
Nov 06, 2023

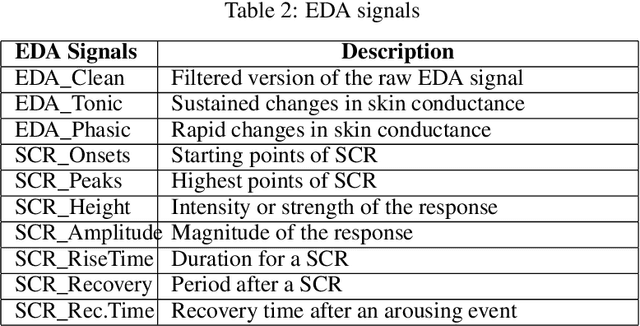

The development of various sensing technologies is improving measurements of stress and the well-being of individuals. Although progress has been made with single signal modalities like wearables and facial emotion recognition, integrating multiple modalities provides a more comprehensive understanding of stress, given that stress manifests differently across different people. Multi-modal learning aims to capitalize on the strength of each modality rather than relying on a single signal. Given the complexity of processing and integrating high-dimensional data from limited subjects, more research is needed. Numerous research efforts have been focused on fusing stress and emotion signals at an early stage, e.g., feature-level fusion using basic machine learning methods and 1D-CNN Methods. This paper proposes a multi-modal learning approach for stress detection that integrates facial landmarks and biometric signals. We test this multi-modal integration with various early-fusion and late-fusion techniques to integrate the 1D-CNN model from biometric signals and 2-D CNN using facial landmarks. We evaluate these architectures using a rigorous test of models' generalizability using the leave-one-subject-out mechanism, i.e., all samples related to a single subject are left out to train the model. Our findings show that late-fusion achieved 94.39\% accuracy, and early-fusion surpassed it with a 98.38\% accuracy rate. This research contributes valuable insights into enhancing stress detection through a multi-modal approach. The proposed research offers important knowledge in improving stress detection using a multi-modal approach.
One-Class Classification for Intrusion Detection on Vehicular Networks
Sep 25, 2023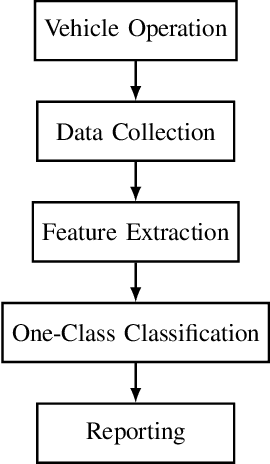

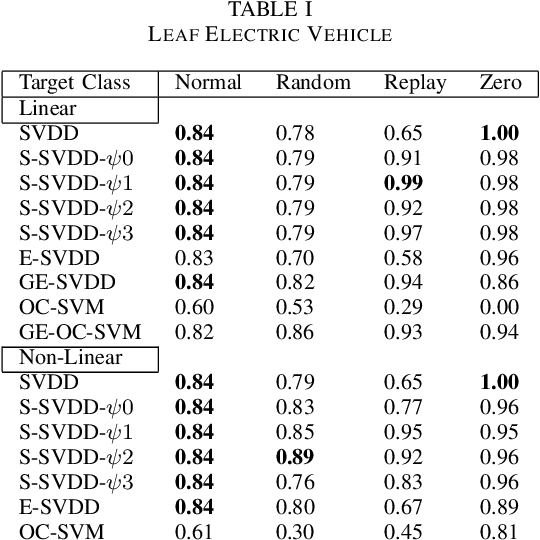
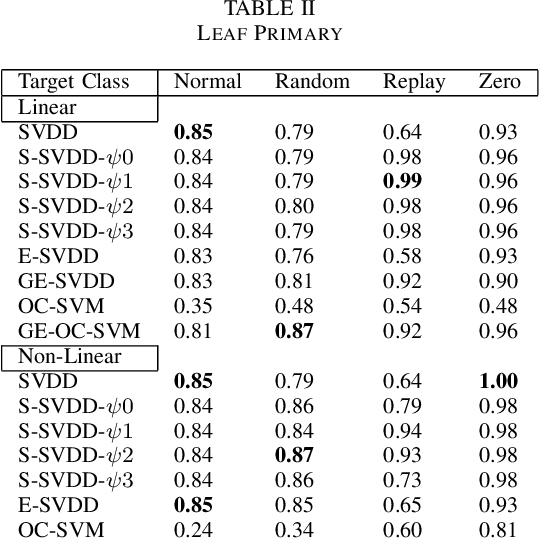
Controller Area Network bus systems within vehicular networks are not equipped with the tools necessary to ward off and protect themselves from modern cyber-security threats. Work has been done on using machine learning methods to detect and report these attacks, but common methods are not robust towards unknown attacks. These methods usually rely on there being a sufficient representation of attack data, which may not be available due to there either not being enough data present to adequately represent its distribution or the distribution itself is too diverse in nature for there to be a sufficient representation of it. With the use of one-class classification methods, this issue can be mitigated as only normal data is required to train a model for the detection of anomalous instances. Research has been done on the efficacy of these methods, most notably One-Class Support Vector Machine and Support Vector Data Description, but many new extensions of these works have been proposed and have yet to be tested for injection attacks in vehicular networks. In this paper, we investigate the performance of various state-of-the-art one-class classification methods for detecting injection attacks on Controller Area Network bus traffic. We investigate the effectiveness of these techniques on attacks launched on Controller Area Network buses from two different vehicles during normal operation and while being attacked. We observe that the Subspace Support Vector Data Description method outperformed all other tested methods with a Gmean of about 85%.
Deep Multi-view Learning to Rank
Jan 31, 2018

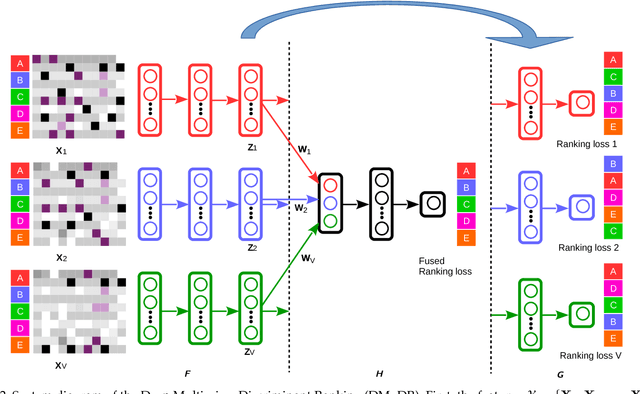
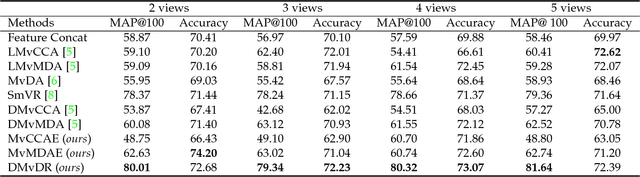
We study the problem of learning to rank from multiple sources. Though multi-view learning and learning to rank have been studied extensively leading to a wide range of applications, multi-view learning to rank as a synergy of both topics has received little attention. The aim of the paper is to propose a composite ranking method while keeping a close correlation with the individual rankings simultaneously. We propose a multi-objective solution to ranking by capturing the information of the feature mapping from both within each view as well as across views using autoencoder-like networks. Moreover, a novel end-to-end solution is introduced to enhance the joint ranking with minimum view-specific ranking loss, so that we can achieve the maximum global view agreements within a single optimization process. The proposed method is validated on a wide variety of ranking problems, including university ranking, multi-view lingual text ranking and image data ranking, providing superior results.