 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRIGHTER: BRIdging the Gap in Human-Annotated Textual Emotion Recognition Datasets for 28 Languages
Feb 17, 2025



People worldwide use language in subtle and complex ways to express emotions. While emotion recognition -- an umbrella term for several NLP tasks -- significantly impacts different applications in NLP and other fields, most work in the area is focused on high-resource languages. Therefore, this has led to major disparities in research and proposed solutions, especially for low-resource languages that suffer from the lack of high-quality datasets. In this paper, we present BRIGHTER-- a collection of multilabeled emotion-annotated datasets in 28 different languages. BRIGHTER covers predominantly low-resource languages from Africa, Asia, Eastern Europe, and Latin America, with instances from various domains annotated by fluent speakers. We describe the data collection and annotation processes and the challenges of building these datasets. Then, we report different experimental results for monolingual and crosslingual multi-label emotion identification, as well as intensity-level emotion recognition. We investigate results with and without using LLMs and analyse the large variability in performance across languages and text domains. We show that BRIGHTER datasets are a step towards bridging the gap in text-based emotion recognition and discuss their impact and utility.
Learn from the Past: Language-conditioned Object Rearrangement with Large Language Models
Jan 30, 2025



Object rearrangement is a significant task for collaborative robots, where they are directed to manipulate objects into a specified goal state. Determining the placement of objects is a major challenge that influences the efficiency of the rearrangement process. Most current methods heavily rely on pre-collected datasets to train the model for predicting the goal position and are restricted to specific instructions, which limits their broader applicability and effectiveness.In this paper, we propose a framework of language-conditioned object rearrangement based on the Large Language Model (LLM). Particularly, our approach mimics human reasoning by using past successful experiences as a reference to infer the desired goal position. Based on LLM's strong natural language comprehension and inference ability, our method can generalise to handle various everyday objects and free-form language instructions in a zero-shot manner. Experimental results demonstrate that our methods can effectively execute the robotic rearrangement tasks, even those involving long sequential orders.
Learn from Incomplete Tactile Data: Tactile Representation Learning with Masked Autoencoders
Jul 14, 2023



The missing signal caused by the objects being occluded or an unstable sensor is a common challenge during data collection. Such missing signals will adversely affect the results obtained from the data, and this issue is observed more frequently in robotic tactile perception. In tactile perception, due to the limited working space and the dynamic environment, the contact between the tactile sensor and the object is frequently insufficient and unstable, which causes the partial loss of signals, thus leading to incomplete tactile data. The tactile data will therefore contain fewer tactile cues with low information density. In this paper, we propose a tactile representation learning method, named TacMAE, based on Masked Autoencoder to address the problem of incomplete tactile data in tactile perception. In our framework, a portion of the tactile image is masked out to simulate the missing contact region. By reconstructing the missing signals in the tactile image, the trained model can achieve a high-level understanding of surface geometry and tactile properties from limited tactile cues. The experimental results of tactile texture recognition show that our proposed TacMAE can achieve a high recognition accuracy of 71.4% in the zero-shot transfer and 85.8% after fine-tuning, which are 15.2% and 8.2% higher than the results without using masked modeling. The extensive experiments on YCB objects demonstrate the knowledge transferability of our proposed method and the potential to improve efficiency in tactile exploration.
Multimodal Zero-Shot Learning for Tactile Texture Recognition
Jun 22, 2023



Tactile sensing plays an irreplaceable role in robotic material recognition. It enables robots to distinguish material properties such as their local geometry and textures, especially for materials like textiles. However, most tactile recognition methods can only classify known materials that have been touched and trained with tactile data, yet cannot classify unknown materials that are not trained with tactile data. To solve this problem, we propose a tactile zero-shot learning framework to recognise unknown materials when they are touched for the first time without requiring training tactile samples. The visual modality, providing tactile cues from sight, and semantic attributes, giving high-level characteristics, are combined together to bridge the gap between touched classes and untouched classes. A generative model is learnt to synthesise tactile features according to corresponding visual images and semantic embeddings, and then a classifier can be trained using the synthesised tactile features of untouched materials for zero-shot recognition. Extensive experiments demonstrate that our proposed multimodal generative model can achieve a high recognition accuracy of 83.06% in classifying materials that were not touched before. The robotic experiment demo and the dataset are available at https://sites.google.com/view/multimodalzsl.
Multiclass classification for multidimensional functional data through deep neural networks
May 24, 2023



The intrinsically infinite-dimensional features of the functional observations over multidimensional domains render the standard classification methods effectively inapplicable. To address this problem, we introduce a novel multiclass functional deep neural network (mfDNN) classifier as an innovative data mining and classification tool. Specifically, we consider sparse deep neural network architecture with rectifier linear unit (ReLU) activation function and minimize the cross-entropy loss in the multiclass classification setup. This neural network architecture allows us to employ modern computational tools in the implementation. The convergence rates of the misclassification risk functions are also derived for both fully observed and discretely observed multidimensional functional data. We demonstrate the performance of mfDNN on simulated data and several benchmark datasets from different application domains.
Robotic Perception of Transparent Objects: A Review
Mar 31, 2023
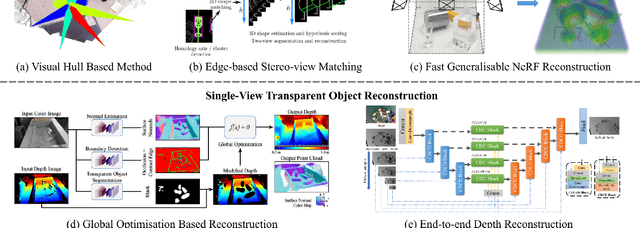

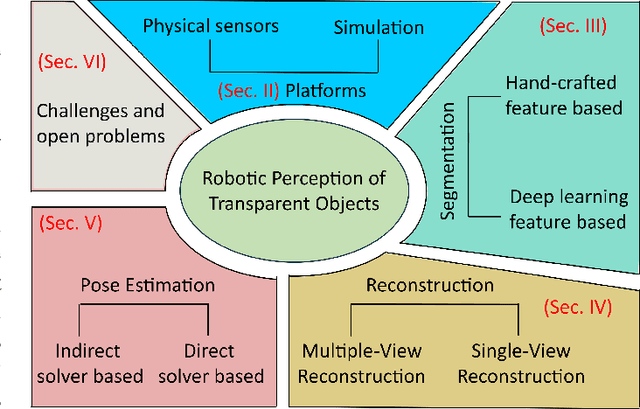
Transparent object perception is a rapidly developing research problem in artificial intelligence. The ability to perceive transparent objects enables robots to achieve higher levels of autonomy, unlocking new applications in various industries such as healthcare, services and manufacturing. Despite numerous datasets and perception methods being proposed in recent years, there is still a lack of in-depth understanding of these methods and the challenges in this field. To address this gap, this article provides a comprehensive survey of the platforms and recent advances for robotic perception of transparent objects. We highlight the main challenges and propose future directions of various transparent object perception tasks, i.e., segmentation, reconstruction, and pose estimation. We also discuss the limitations of existing datasets in diversity and complexity, and the benefits of employing multi-modal sensors, such as RGB-D cameras, thermal cameras, and polarised imaging, for transparent object perception. Furthermore, we identify perception challenges in complex and dynamic environments, as well as for objects with changeable geometries. Finally, we provide an interactive online platform to navigate each reference: \url{https://sites.google.com/view/transperception}.
Vis2Hap: Vision-based Haptic Rendering by Cross-modal Generation
Jan 17, 2023



To assist robots in teleoperation tasks, haptic rendering which allows human operators access a virtual touch feeling has been developed in recent years. Most previous haptic rendering methods strongly rely on data collected by tactile sensors. However, tactile data is not widely available for robots due to their limited reachable space and the restrictions of tactile sensors. To eliminate the need for tactile data, in this paper we propose a novel method named as Vis2Hap to generate haptic rendering from visual inputs that can be obtained from a distance without physical interaction. We take the surface texture of objects as key cues to be conveyed to the human operator. To this end, a generative model is designed to simulate the roughness and slipperiness of the object's surface. To embed haptic cues in Vis2Hap, we use height maps from tactile sensors and spectrograms from friction coefficients as the intermediate outputs of the generative model. Once Vis2Hap is trained, it can be used to generate height maps and spectrograms of new surface textures, from which a friction image can be obtained and displayed on a haptic display. The user study demonstrates that our proposed Vis2Hap method enables users to access a realistic haptic feeling similar to that of physical objects. The proposed vision-based haptic rendering has the potential to enhance human operators' perception of the remote environment and facilitate robotic manipulation.
Where Shall I Touch? Vision-Guided Tactile Poking for Transparent Object Grasping
Aug 20, 2022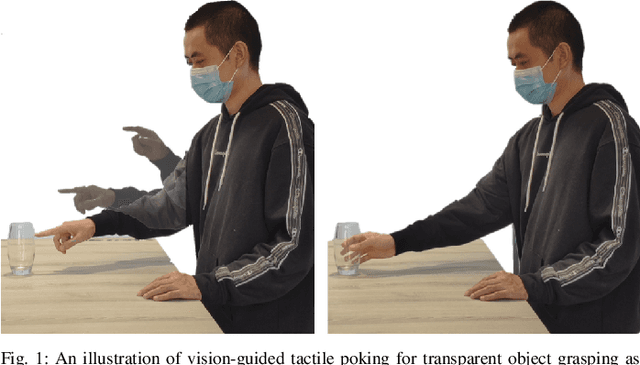

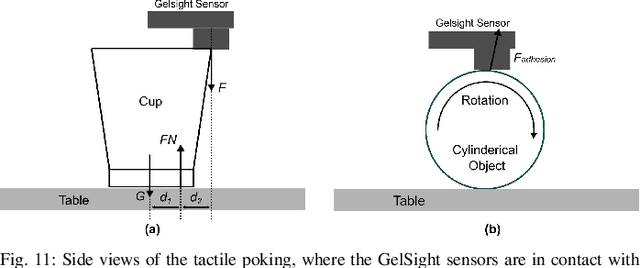

Picking up transparent objects is still a challenging task for robots. The visual properties of transparent objects such as reflection and refraction make the current grasping methods that rely on camera sensing fail to detect and localise them. However, humans can handle the transparent object well by first observing its coarse profile and then poking an area of interest to get a fine profile for grasping. Inspired by this, we propose a novel framework of vision-guided tactile poking for transparent objects grasping. In the proposed framework, a segmentation network is first used to predict the horizontal upper regions named as poking regions, where the robot can poke the object to obtain a good tactile reading while leading to minimal disturbance to the object's state. A poke is then performed with a high-resolution GelSight tactile sensor. Given the local profiles improved with the tactile reading, a heuristic grasp is planned for grasping the transparent object. To mitigate the limitations of real-world data collection and labelling for transparent objects, a large-scale realistic synthetic dataset was constructed. Extensive experiments demonstrate that our proposed segmentation network can predict the potential poking region with a high mean Average Precision (mAP) of 0.360, and the vision-guided tactile poking can enhance the grasping success rate significantly from 38.9% to 85.2%. Thanks to its simplicity, our proposed approach could also be adopted by other force or tactile sensors and could be used for grasping of other challenging objects. All the materials used in this paper are available at https://sites.google.com/view/tactilepoking.
A4T: Hierarchical Affordance Detection for Transparent Objects Depth Reconstruction and Manipulation
Jul 11, 2022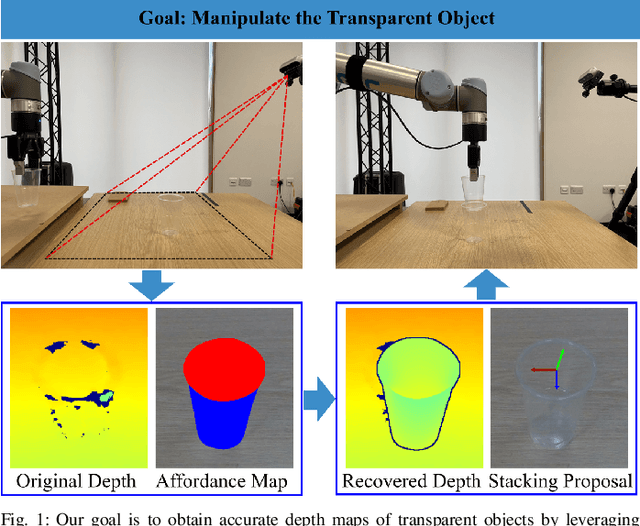



Transparent objects are widely used in our daily lives and therefore robots need to be able to handle them. However, transparent objects suffer from light reflection and refraction, which makes it challenging to obtain the accurate depth maps required to perform handling tasks. In this paper, we propose a novel affordance-based framework for depth reconstruction and manipulation of transparent objects, named A4T. A hierarchical AffordanceNet is first used to detect the transparent objects and their associated affordances that encode the relative positions of an object's different parts. Then, given the predicted affordance map, a multi-step depth reconstruction method is used to progressively reconstruct the depth maps of transparent objects. Finally, the reconstructed depth maps are employed for the affordance-based manipulation of transparent objects. To evaluate our proposed method, we construct a real-world dataset TRANS-AFF with affordances and depth maps of transparent objects, which is the first of its kind. Extensive experiments show that our proposed methods can predict accurate affordance maps, and significantly improve the depth reconstruction of transparent objects compared to the state-of-the-art method, with the Root Mean Squared Error in meters significantly decreased from 0.097 to 0.042. Furthermore, we demonstrate the effectiveness of our proposed method with a series of robotic manipulation experiments on transparent objects. See supplementary video and results at https://sites.google.com/view/affordance4trans.
Robust Deep Neural Network Estimation for Multi-dimensional Functional Data
May 19, 2022

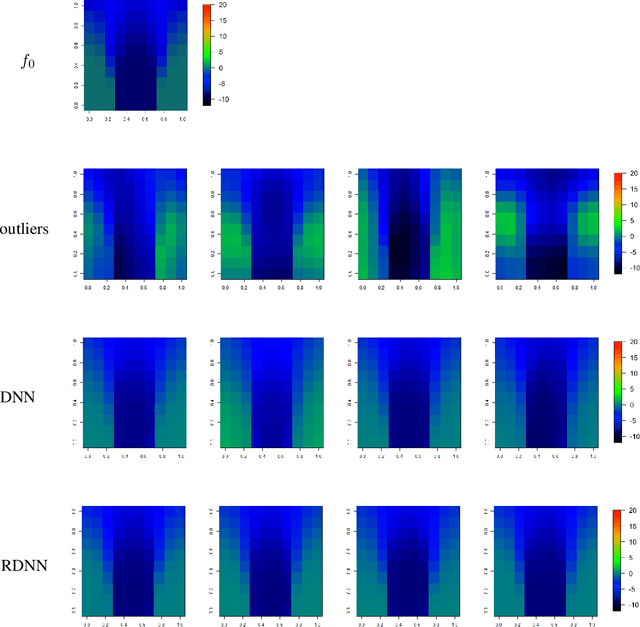

In this paper, we propose a robust estimator for the location function from multi-dimensional functional data. The proposed estimators are based on the deep neural networks with ReLU activation function. At the meanwhile, the estimators are less susceptible to outlying observations and model-misspecification. For any multi-dimensional functional data, we provide the uniform convergence rates for the proposed robust deep neural networks estimators. Simulation studies illustrate the competitive performance of the robust deep neural network estimators on regular data and their superior performance on data that contain anomalies. The proposed method is also applied to analyze 2D and 3D images of patients with Alzheimer's disease obtained from the Alzheimer Disease Neuroimaging Initiative database.