 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Multi-modal Sensing for Robotic Insertion Tasks in R&D Laboratories
Jul 02, 2023Performing a large volume of experiments in Chemistry labs creates repetitive actions costing researchers time, automating these routines is highly desirable. Previous experiments in robotic chemistry have performed high numbers of experiments autonomously, however, these processes rely on automated machines in all stages from solid or liquid addition to analysis of the final product. In these systems every transition between machine requires the robotic chemist to pick and place glass vials, however, this is currently performed using open loop methods which require all equipment being used by the robot to be in well defined known locations. We seek to begin closing the loop in this vial handling process in a way which also fosters human-robot collaboration in the chemistry lab environment. To do this the robot must be able to detect valid placement positions for the vials it is collecting, and reliably insert them into the detected locations. We create a single modality visual method for estimating placement locations to provide a baseline before introducing two additional methods of feedback (force and tactile feedback). Our visual method uses a combination of classic computer vision methods and a CNN discriminator to detect possible insertion points, then a vial is grasped and positioned above an insertion point and the multi-modal methods guide the final insertion movements using an efficient search pattern. Through our experiments we show the baseline insertion rate of 48.78% improves to 89.55% with the addition of our "force and vision" multi-modal feedback method.
Where Shall I Touch? Vision-Guided Tactile Poking for Transparent Object Grasping
Aug 20, 2022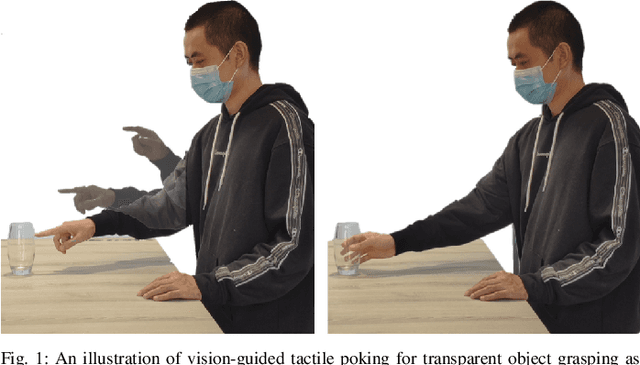

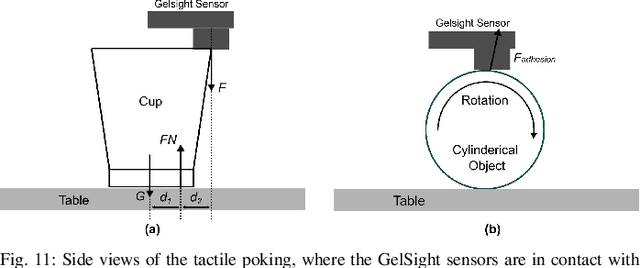

Picking up transparent objects is still a challenging task for robots. The visual properties of transparent objects such as reflection and refraction make the current grasping methods that rely on camera sensing fail to detect and localise them. However, humans can handle the transparent object well by first observing its coarse profile and then poking an area of interest to get a fine profile for grasping. Inspired by this, we propose a novel framework of vision-guided tactile poking for transparent objects grasping. In the proposed framework, a segmentation network is first used to predict the horizontal upper regions named as poking regions, where the robot can poke the object to obtain a good tactile reading while leading to minimal disturbance to the object's state. A poke is then performed with a high-resolution GelSight tactile sensor. Given the local profiles improved with the tactile reading, a heuristic grasp is planned for grasping the transparent object. To mitigate the limitations of real-world data collection and labelling for transparent objects, a large-scale realistic synthetic dataset was constructed. Extensive experiments demonstrate that our proposed segmentation network can predict the potential poking region with a high mean Average Precision (mAP) of 0.360, and the vision-guided tactile poking can enhance the grasping success rate significantly from 38.9% to 85.2%. Thanks to its simplicity, our proposed approach could also be adopted by other force or tactile sensors and could be used for grasping of other challenging objects. All the materials used in this paper are available at https://sites.google.com/view/tactilepoking.