 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Multi-modal Sensing for Robotic Insertion Tasks in R&D Laboratories
Jul 02, 2023Performing a large volume of experiments in Chemistry labs creates repetitive actions costing researchers time, automating these routines is highly desirable. Previous experiments in robotic chemistry have performed high numbers of experiments autonomously, however, these processes rely on automated machines in all stages from solid or liquid addition to analysis of the final product. In these systems every transition between machine requires the robotic chemist to pick and place glass vials, however, this is currently performed using open loop methods which require all equipment being used by the robot to be in well defined known locations. We seek to begin closing the loop in this vial handling process in a way which also fosters human-robot collaboration in the chemistry lab environment. To do this the robot must be able to detect valid placement positions for the vials it is collecting, and reliably insert them into the detected locations. We create a single modality visual method for estimating placement locations to provide a baseline before introducing two additional methods of feedback (force and tactile feedback). Our visual method uses a combination of classic computer vision methods and a CNN discriminator to detect possible insertion points, then a vial is grasped and positioned above an insertion point and the multi-modal methods guide the final insertion movements using an efficient search pattern. Through our experiments we show the baseline insertion rate of 48.78% improves to 89.55% with the addition of our "force and vision" multi-modal feedback method.
Visual-Tactile Multimodality for Following Deformable Linear Objects Using Reinforcement Learning
Mar 31, 2022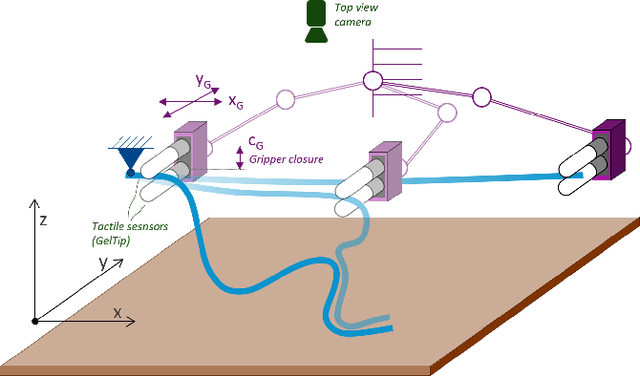
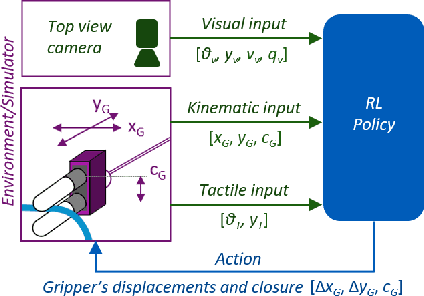
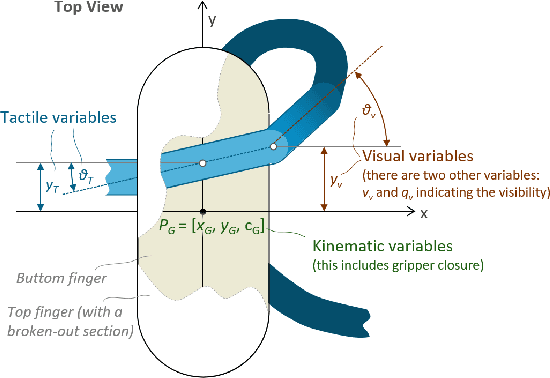

Manipulation of deformable objects is a challenging task for a robot. It will be problematic to use a single sensory input to track the behaviour of such objects: vision can be subjected to occlusions, whereas tactile inputs cannot capture the global information that is useful for the task. In this paper, we study the problem of using vision and tactile inputs together to complete the task of following deformable linear objects, for the first time. We create a Reinforcement Learning agent using different sensing modalities and investigate how its behaviour can be boosted using visual-tactile fusion, compared to using a single sensing modality. To this end, we developed a benchmark in simulation for manipulating the deformable linear objects using multimodal sensing inputs. The policy of the agent uses distilled information, e.g., the pose of the object in both visual and tactile perspectives, instead of the raw sensing signals, so that it can be directly transferred to real environments. In this way, we disentangle the perception system and the learned control policy. Our extensive experiments show that the use of both vision and tactile inputs, together with proprioception, allows the agent to complete the task in up to 92% of cases, compared to 77% when only one of the signals is given. Our results can provide valuable insights for the future design of tactile sensors and for deformable objects manipulation.
A Robot that Counts Like a Child -- a Developmental Model of Counting and Pointing
Aug 05, 2020
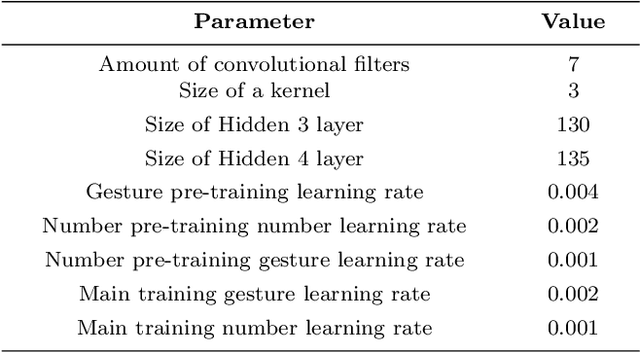

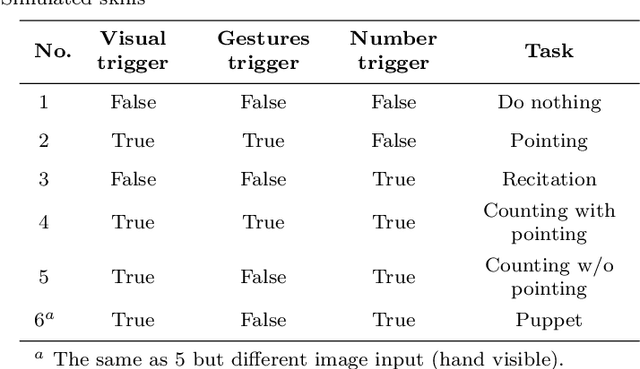
In this paper, a novel neuro-robotics model capable of counting real items is introduced. The model allows us to investigate the interaction between embodiment and numerical cognition. This is composed of a deep neural network capable of image processing and sequential tasks performance, and a robotic platform providing the embodiment - the iCub humanoid robot. The network is trained using images from the robot's cameras and proprioceptive signals from its joints. The trained model is able to count a set of items and at the same time points to them. We investigate the influence of pointing on the counting process and compare our results with those from studies with children. Several training approaches are presented in this paper all of them uses pre-training routine allowing the network to gain the ability of pointing and number recitation (from 1 to 10) prior to counting training. The impact of the counted set size and distance to the objects are investigated. The obtained results on counting performance show similarities with those from human studies.
Influence of Pointing on Learning to Count: A Neuro-Robotics Model
Jul 09, 2019

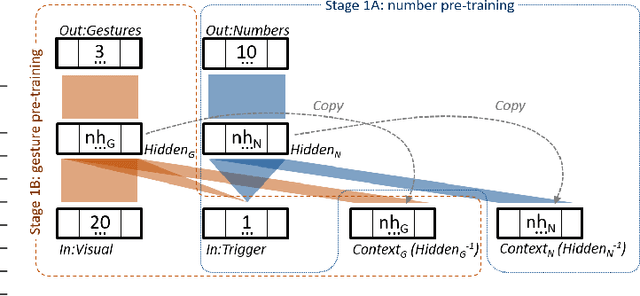

In this paper a neuro-robotics model capable of counting using gestures is introduced. The contribution of gestures to learning to count is tested with various model and training conditions. Two studies were presented in this article. In the first, we combine different modalities of the robot's neural network, in the second, a novel training procedure for it is proposed. The model is trained with pointing data from an iCub robot simulator. The behaviour of the model is in line with that of human children in terms of performance change depending on gesture production.
A Deep Neural Network for Finger Counting and Numerosity Estimation
Jul 09, 2019
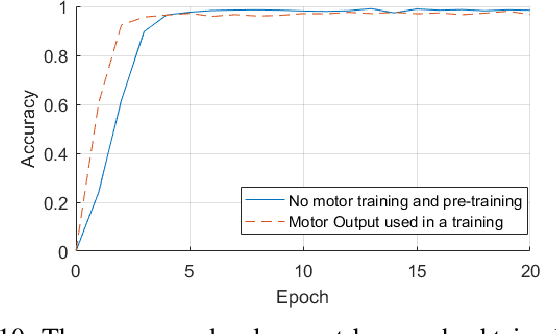
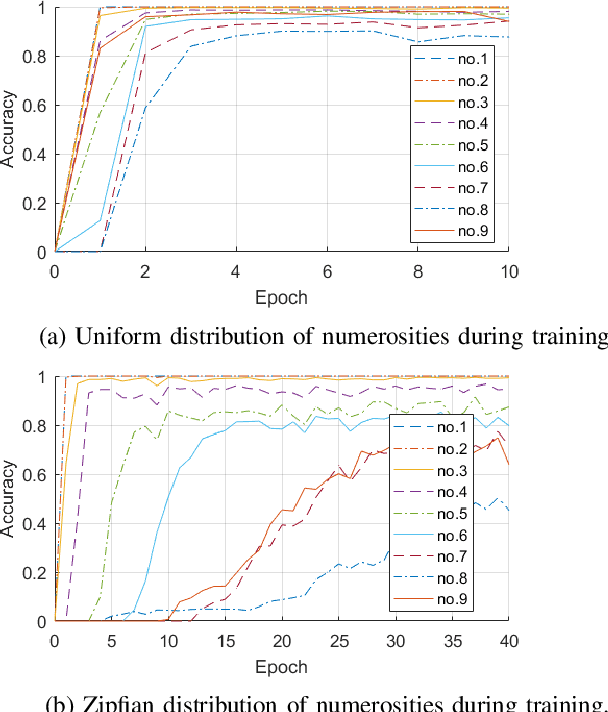
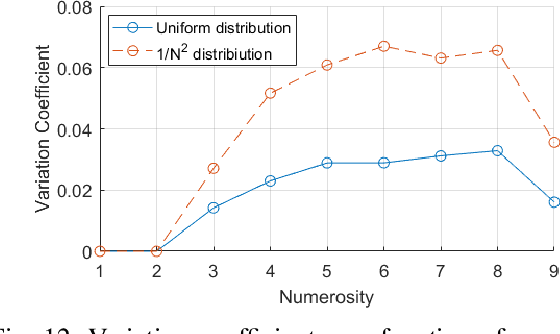
In this paper, we present neuro-robotics models with a deep artificial neural network capable of generating finger counting positions and number estimation. We first train the model in an unsupervised manner where each layer is treated as a Restricted Boltzmann Machine or an autoencoder. Such a model is further trained in a supervised way. This type of pre-training is tested on our baseline model and two methods of pre-training are compared. The network is extended to produce finger counting positions. The performance in number estimation of such an extended model is evaluated. We test the hypothesis if the subitizing process can be obtained by one single model used also for estimation of higher numerosities. The results confirm the importance of unsupervised training in our enumeration task and show some similarities to human behaviour in the case of subitizing.