 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced 3D Gravity Inversion Using ResU-Net with Density Logging Constraints: A Dual-Phase Training Approach
Jan 06, 2026Gravity exploration has become an important geophysical method due to its low cost and high efficiency. With the rise of artificial intelligence, data-driven gravity inversion methods based on deep learning (DL) possess physical property recovery capabilities that conventional regularization methods lack. However, existing DL methods suffer from insufficient prior information constraints, which leads to inversion models with large data fitting errors and unreliable results. Moreover, the inversion results lack constraints and matching from other exploration methods, leading to results that may contradict known geological conditions. In this study, we propose a novel approach that integrates prior density well logging information to address the above issues. First, we introduce a depth weighting function to the neural network (NN) and train it in the weighted density parameter domain. The NN, under the constraint of the weighted forward operator, demonstrates improved inversion performance, with the resulting inversion model exhibiting smaller data fitting errors. Next, we divide the entire network training into two phases: first training a large pre-trained network Net-I, and then using the density logging information as the constraint to get the optimized fine-tuning network Net-II. Through testing and comparison in synthetic models and Bishop Model, the inversion quality of our method has significantly improved compared to the unconstrained data-driven DL inversion method. Additionally, we also conduct a comparison and discussion between our method and both the conventional focusing inversion (FI) method and its well logging constrained variant. Finally, we apply this method to the measured data from the San Nicolas mining area in Mexico, comparing and analyzing it with two recent gravity inversion methods based on DL.
A Flow-based Truncated Denoising Diffusion Model for Super-resolution Magnetic Resonance Spectroscopic Imaging
Oct 25, 2024Magnetic Resonance Spectroscopic Imaging (MRSI) is a non-invasive imaging technique for studying metabolism and has become a crucial tool for understanding neurological diseases, cancers and diabetes. High spatial resolution MRSI is needed to characterize lesions, but in practice MRSI is acquired at low resolution due to time and sensitivity restrictions caused by the low metabolite concentrations. Therefore, there is an imperative need for a post-processing approach to generate high-resolution MRSI from low-resolution data that can be acquired fast and with high sensitivity. Deep learning-based super-resolution methods provided promising results for improving the spatial resolution of MRSI, but they still have limited capability to generate accurate and high-quality images. Recently, diffusion models have demonstrated superior learning capability than other generative models in various tasks, but sampling from diffusion models requires iterating through a large number of diffusion steps, which is time-consuming. This work introduces a Flow-based Truncated Denoising Diffusion Model (FTDDM) for super-resolution MRSI, which shortens the diffusion process by truncating the diffusion chain, and the truncated steps are estimated using a normalizing flow-based network. The network is conditioned on upscaling factors to enable multi-scale super-resolution. To train and evaluate the deep learning models, we developed a 1H-MRSI dataset acquired from 25 high-grade glioma patients. We demonstrate that FTDDM outperforms existing generative models while speeding up the sampling process by over 9-fold compared to the baseline diffusion model. Neuroradiologists' evaluations confirmed the clinical advantages of our method, which also supports uncertainty estimation and sharpness adjustment, extending its potential clinical applications.
* Accepted by Medical Image Analysis (MedIA)
Preserved Edge Convolutional Neural Network for Sensitivity Enhancement of Deuterium Metabolic Imaging (DMI)
Sep 13, 2023
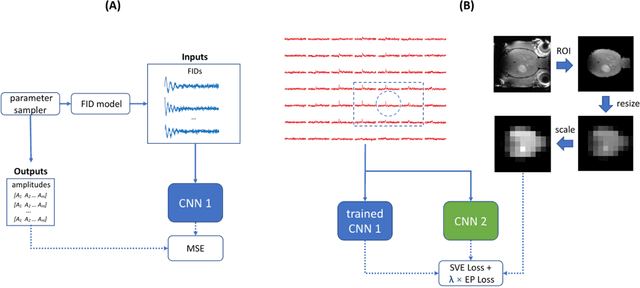
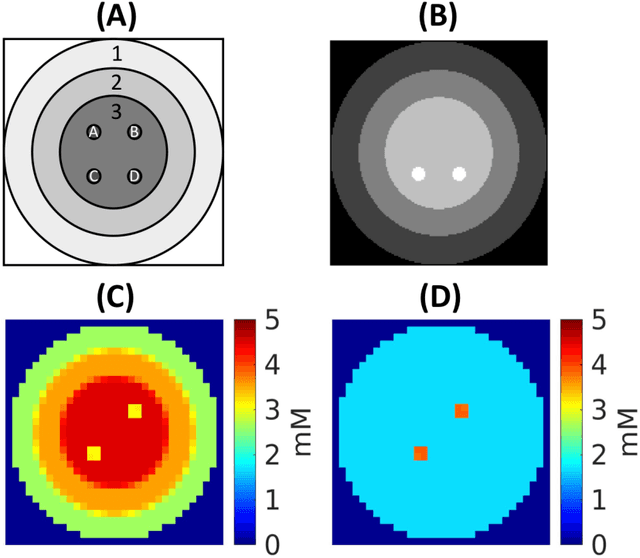
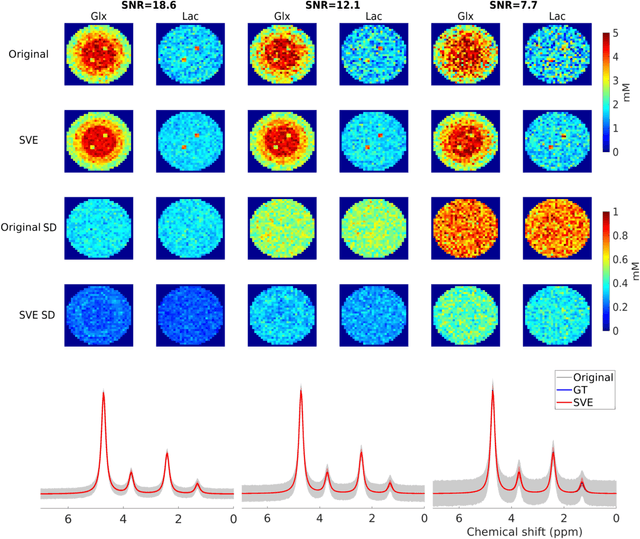
Purpose: Common to most MRSI techniques, the spatial resolution and the minimal scan duration of Deuterium Metabolic Imaging (DMI) are limited by the achievable SNR. This work presents a deep learning method for sensitivity enhancement of DMI. Methods: A convolutional neural network (CNN) was designed to estimate the 2H-labeled metabolite concentrations from low SNR and distorted DMI FIDs. The CNN was trained with synthetic data that represent a range of SNR levels typically encountered in vivo. The estimation precision was further improved by fine-tuning the CNN with MRI-based edge-preserving regularization for each DMI dataset. The proposed processing method, PReserved Edge ConvolutIonal neural network for Sensitivity Enhanced DMI (PRECISE-DMI), was applied to simulation studies and in vivo experiments to evaluate the anticipated improvements in SNR and investigate the potential for inaccuracies. Results: PRECISE-DMI visually improved the metabolic maps of low SNR datasets, and quantitatively provided higher precision than the standard Fourier reconstruction. Processing of DMI data acquired in rat brain tumor models resulted in more precise determination of 2H-labeled lactate and glutamate + glutamine levels, at increased spatial resolution (from >8 to 2 $\mu$L) or shortened scan time (from 32 to 4 min) compared to standard acquisitions. However, rigorous SD-bias analyses showed that overuse of the edge-preserving regularization can compromise the accuracy of the results. Conclusion: PRECISE-DMI allows a flexible trade-off between enhancing the sensitivity of DMI and minimizing the inaccuracies. With typical settings, the DMI sensitivity can be improved by 3-fold while retaining the capability to detect local signal variations.
Neural Contact Fields: Tracking Extrinsic Contact with Tactile Sensing
Oct 17, 2022

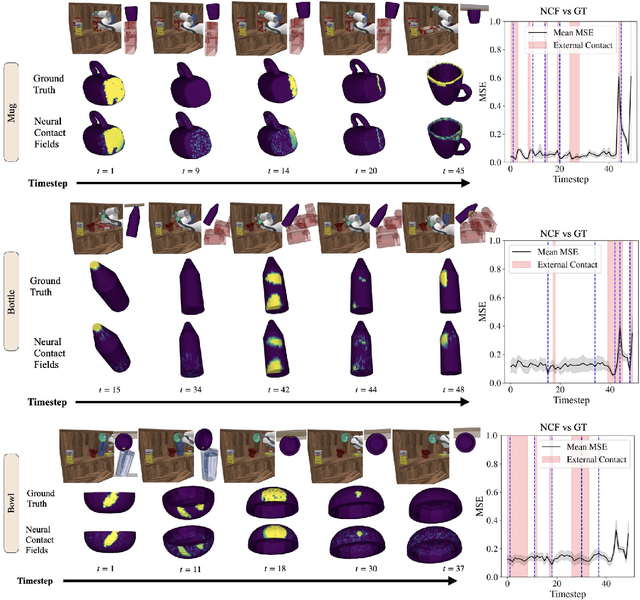
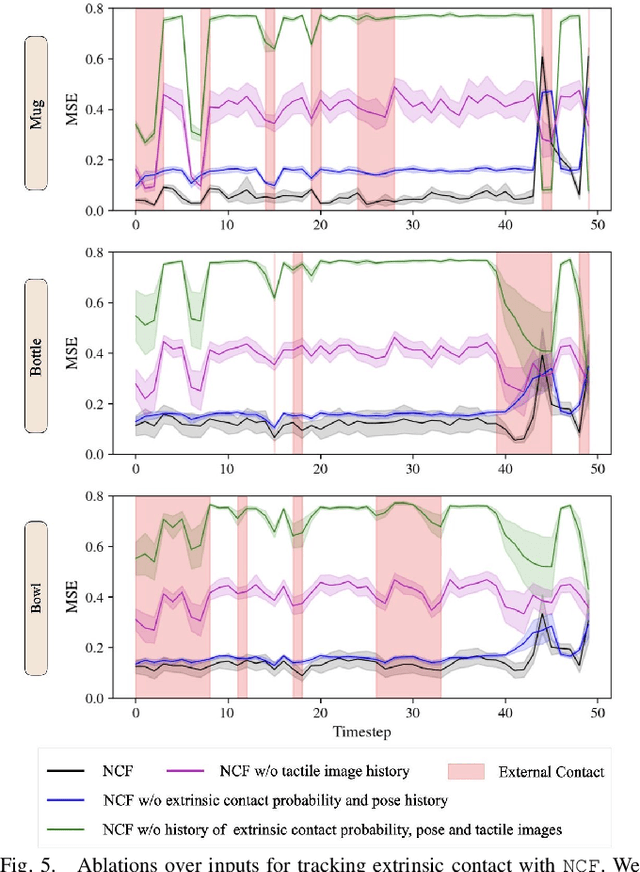
We present Neural Contact Fields, a method that brings together neural fields and tactile sensing to address the problem of tracking extrinsic contact between object and environment. Knowing where the external contact occurs is a first step towards methods that can actively control it in facilitating downstream manipulation tasks. Prior work for localizing environmental contacts typically assume a contact type (e.g. point or line), does not capture contact/no-contact transitions, and only works with basic geometric-shaped objects. Neural Contact Fields are the first method that can track arbitrary multi-modal extrinsic contacts without making any assumptions about the contact type. Our key insight is to estimate the probability of contact for any 3D point in the latent space of object shapes, given vision-based tactile inputs that sense the local motion resulting from the external contact. In experiments, we find that Neural Contact Fields are able to localize multiple contact patches without making any assumptions about the geometry of the contact, and capture contact/no-contact transitions for known categories of objects with unseen shapes in unseen environment configurations. In addition to Neural Contact Fields, we also release our YCB-Extrinsic-Contact dataset of simulated extrinsic contact interactions to enable further research in this area. Project repository: https://github.com/carolinahiguera/NCF
Flow-based Visual Quality Enhancer for Super-resolution Magnetic Resonance Spectroscopic Imaging
Jul 20, 2022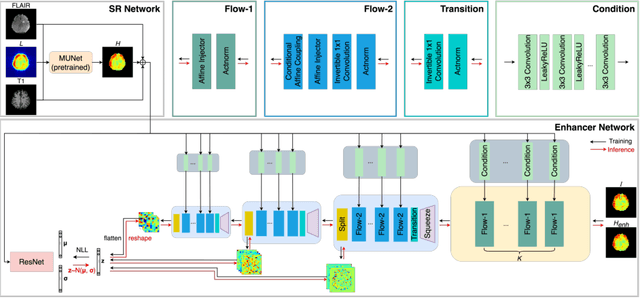
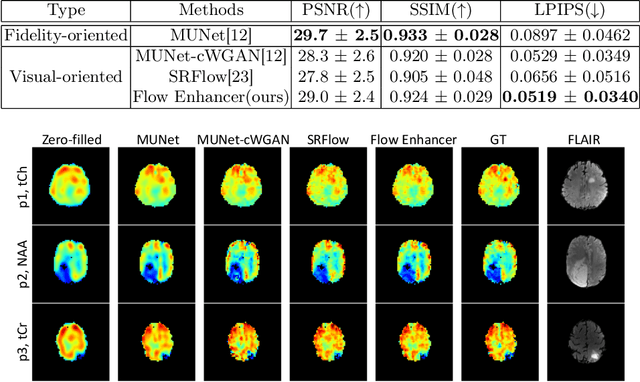
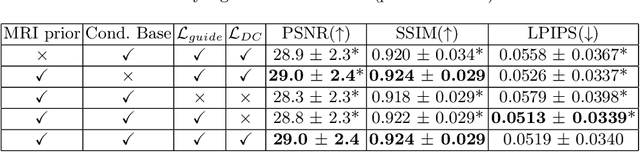
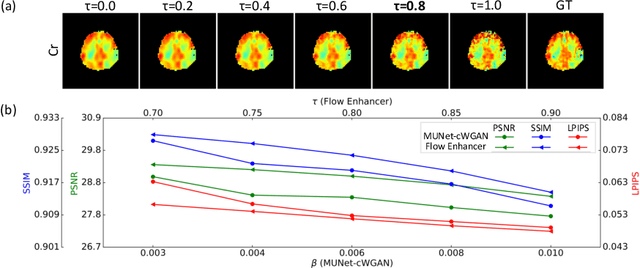
Magnetic Resonance Spectroscopic Imaging (MRSI) is an essential tool for quantifying metabolites in the body, but the low spatial resolution limits its clinical applications. Deep learning-based super-resolution methods provided promising results for improving the spatial resolution of MRSI, but the super-resolved images are often blurry compared to the experimentally-acquired high-resolution images. Attempts have been made with the generative adversarial networks to improve the image visual quality. In this work, we consider another type of generative model, the flow-based model, of which the training is more stable and interpretable compared to the adversarial networks. Specifically, we propose a flow-based enhancer network to improve the visual quality of super-resolution MRSI. Different from previous flow-based models, our enhancer network incorporates anatomical information from additional image modalities (MRI) and uses a learnable base distribution. In addition, we impose a guide loss and a data-consistency loss to encourage the network to generate images with high visual quality while maintaining high fidelity. Experiments on a 1H-MRSI dataset acquired from 25 high-grade glioma patients indicate that our enhancer network outperforms the adversarial networks and the baseline flow-based methods. Our method also allows visual quality adjustment and uncertainty estimation.
Multi-scale Super-resolution Magnetic Resonance Spectroscopic Imaging with Adjustable Sharpness
Jun 17, 2022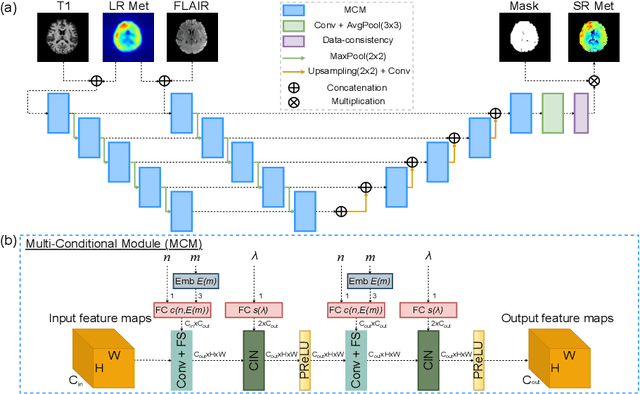
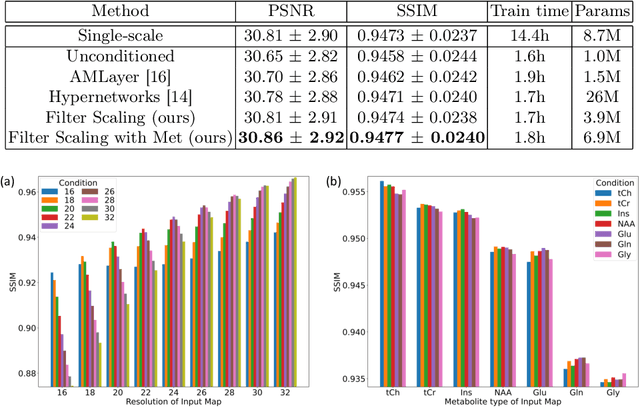
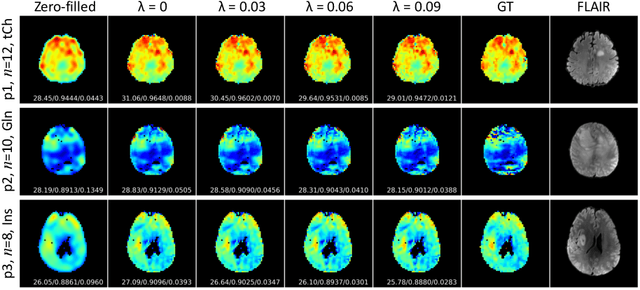
Magnetic Resonance Spectroscopic Imaging (MRSI) is a valuable tool for studying metabolic activities in the human body, but the current applications are limited to low spatial resolutions. The existing deep learning-based MRSI super-resolution methods require training a separate network for each upscaling factor, which is time-consuming and memory inefficient. We tackle this multi-scale super-resolution problem using a Filter Scaling strategy that modulates the convolution filters based on the upscaling factor, such that a single network can be used for various upscaling factors. Observing that each metabolite has distinct spatial characteristics, we also modulate the network based on the specific metabolite. Furthermore, our network is conditioned on the weight of adversarial loss so that the perceptual sharpness of the super-resolved metabolic maps can be adjusted within a single network. We incorporate these network conditionings using a novel Multi-Conditional Module. The experiments were carried out on a 1H-MRSI dataset from 15 high-grade glioma patients. Results indicate that the proposed network achieves the best performance among several multi-scale super-resolution methods and can provide super-resolved metabolic maps with adjustable sharpness.
Invertible Sharpening Network for MRI Reconstruction Enhancement
Jun 06, 2022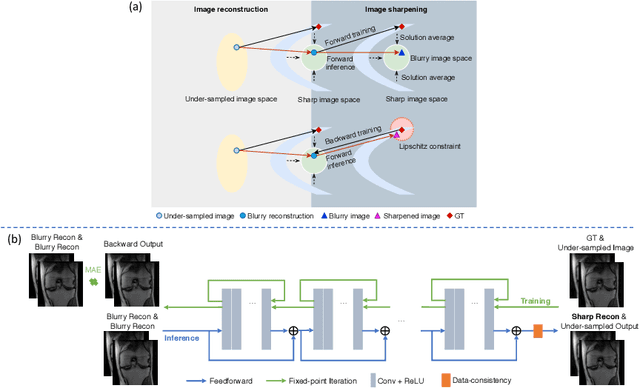

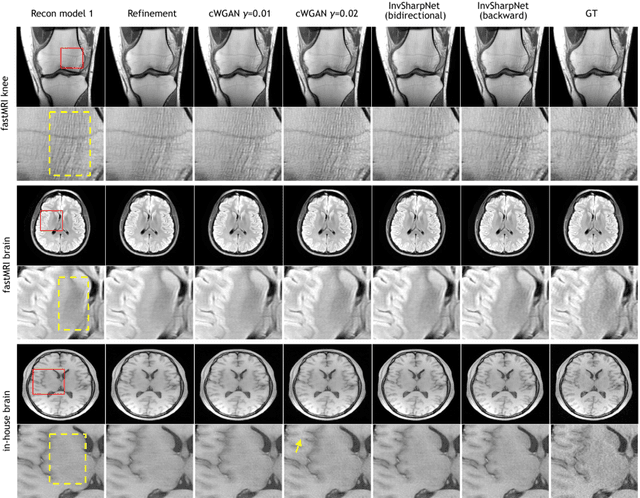

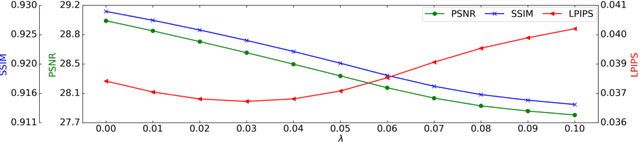
High-quality MRI reconstruction plays a critical role in clinical applications. Deep learning-based methods have achieved promising results on MRI reconstruction. However, most state-of-the-art methods were designed to optimize the evaluation metrics commonly used for natural images, such as PSNR and SSIM, whereas the visual quality is not primarily pursued. Compared to the fully-sampled images, the reconstructed images are often blurry, where high-frequency features might not be sharp enough for confident clinical diagnosis. To this end, we propose an invertible sharpening network (InvSharpNet) to improve the visual quality of MRI reconstructions. During training, unlike the traditional methods that learn to map the input data to the ground truth, InvSharpNet adapts a backward training strategy that learns a blurring transform from the ground truth (fully-sampled image) to the input data (blurry reconstruction). During inference, the learned blurring transform can be inverted to a sharpening transform leveraging the network's invertibility. The experiments on various MRI datasets demonstrate that InvSharpNet can improve reconstruction sharpness with few artifacts. The results were also evaluated by radiologists, indicating better visual quality and diagnostic confidence of our proposed method.
Incremental Learning Meets Transfer Learning: Application to Multi-site Prostate MRI Segmentation
Jun 03, 2022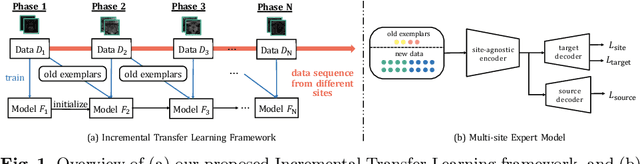

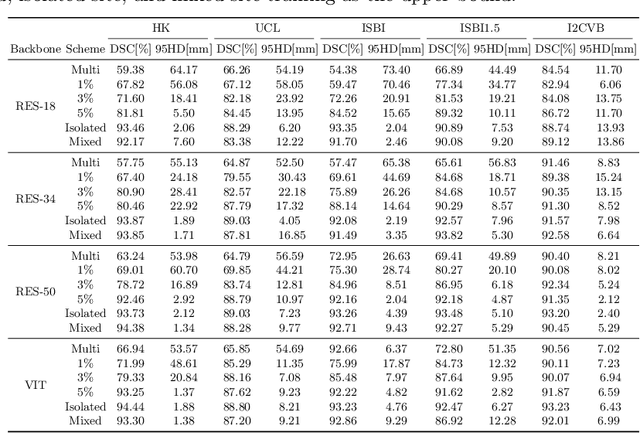
Many medical datasets have recently been created for medical image segmentation tasks, and it is natural to question whether we can use them to sequentially train a single model that (1) performs better on all these datasets, and (2) generalizes well and transfers better to the unknown target site domain. Prior works have achieved this goal by jointly training one model on multi-site datasets, which achieve competitive performance on average but such methods rely on the assumption about the availability of all training data, thus limiting its effectiveness in practical deployment. In this paper, we propose a novel multi-site segmentation framework called incremental-transfer learning (ITL), which learns a model from multi-site datasets in an end-to-end sequential fashion. Specifically, "incremental" refers to training sequentially constructed datasets, and "transfer" is achieved by leveraging useful information from the linear combination of embedding features on each dataset. In addition, we introduce our ITL framework, where we train the network including a site-agnostic encoder with pre-trained weights and at most two segmentation decoder heads. We also design a novel site-level incremental loss in order to generalize well on the target domain. Second, we show for the first time that leveraging our ITL training scheme is able to alleviate challenging catastrophic forgetting problems in incremental learning. We conduct experiments using five challenging benchmark datasets to validate the effectiveness of our incremental-transfer learning approach. Our approach makes minimal assumptions on computation resources and domain-specific expertise, and hence constitutes a strong starting point in multi-site medical image segmentation.
Visual-Tactile Multimodality for Following Deformable Linear Objects Using Reinforcement Learning
Mar 31, 2022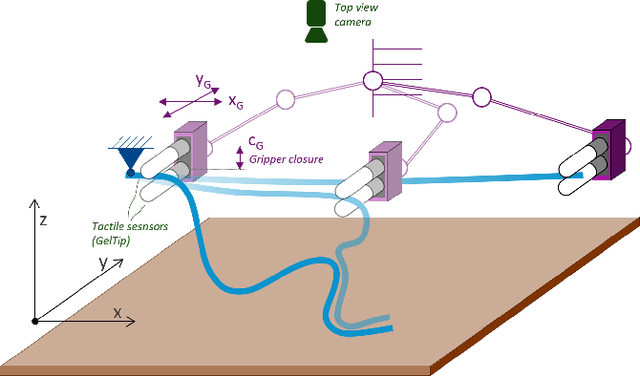
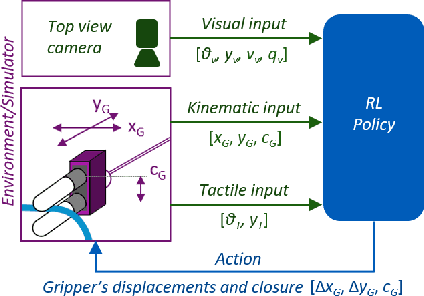
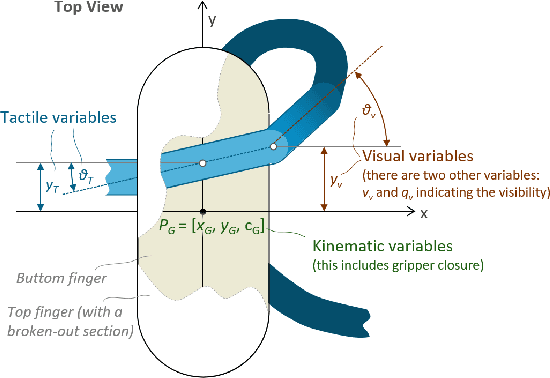

Manipulation of deformable objects is a challenging task for a robot. It will be problematic to use a single sensory input to track the behaviour of such objects: vision can be subjected to occlusions, whereas tactile inputs cannot capture the global information that is useful for the task. In this paper, we study the problem of using vision and tactile inputs together to complete the task of following deformable linear objects, for the first time. We create a Reinforcement Learning agent using different sensing modalities and investigate how its behaviour can be boosted using visual-tactile fusion, compared to using a single sensing modality. To this end, we developed a benchmark in simulation for manipulating the deformable linear objects using multimodal sensing inputs. The policy of the agent uses distilled information, e.g., the pose of the object in both visual and tactile perspectives, instead of the raw sensing signals, so that it can be directly transferred to real environments. In this way, we disentangle the perception system and the learned control policy. Our extensive experiments show that the use of both vision and tactile inputs, together with proprioception, allows the agent to complete the task in up to 92% of cases, compared to 77% when only one of the signals is given. Our results can provide valuable insights for the future design of tactile sensors and for deformable objects manipulation.
Tactile-RL for Insertion: Generalization to Objects of Unknown Geometry
Apr 02, 2021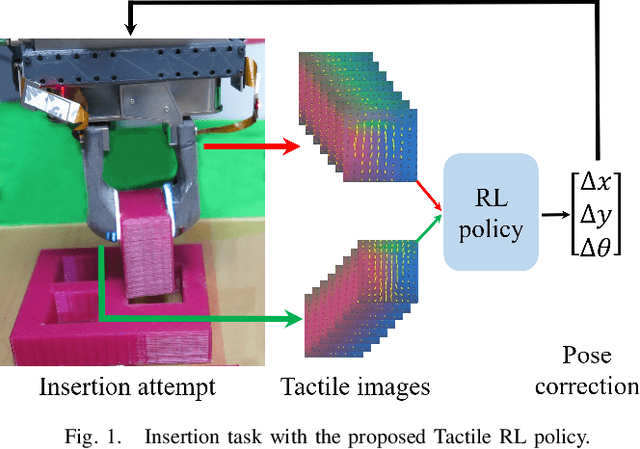
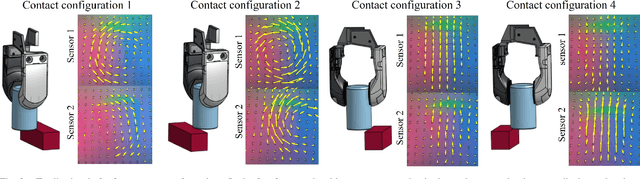
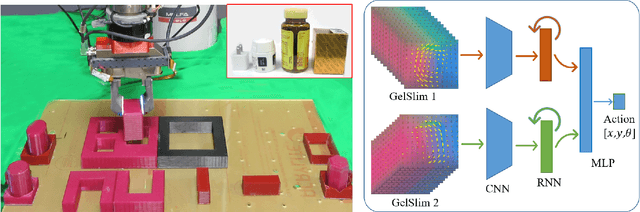
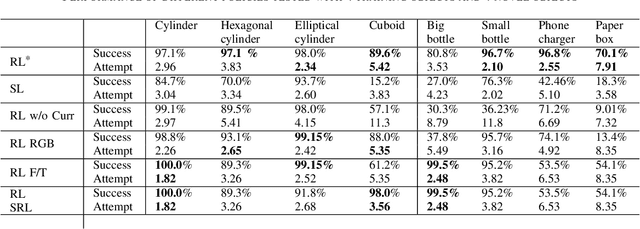
Object insertion is a classic contact-rich manipulation task. The task remains challenging, especially when considering general objects of unknown geometry, which significantly limits the ability to understand the contact configuration between the object and the environment. We study the problem of aligning the object and environment with a tactile-based feedback insertion policy. The insertion process is modeled as an episodic policy that iterates between insertion attempts followed by pose corrections. We explore different mechanisms to learn such a policy based on Reinforcement Learning. The key contribution of this paper is to demonstrate that it is possible to learn a tactile insertion policy that generalizes across different object geometries, and an ablation study of the key design choices for the learning agent: 1) the type of learning scheme: supervised vs. reinforcement learning; 2) the type of learning schedule: unguided vs. curriculum learning; 3) the type of sensing modality: force/torque (F/T) vs. tactile; and 4) the type of tactile representation: tactile RGB vs. tactile flow. We show that the optimal configuration of the learning agent (RL + curriculum + tactile flow) exposed to 4 training objects yields an insertion policy that inserts 4 novel objects with over 85.0% success rate and within 3~4 attempts. Comparisons between F/T and tactile sensing, shows that while an F/T-based policy learns more efficiently, a tactile-based policy provides better generalization.