 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Tangent Knowledge Distillation for Optical Convolutional Networks
Aug 11, 2025Hybrid Optical Neural Networks (ONNs, typically consisting of an optical frontend and a digital backend) offer an energy-efficient alternative to fully digital deep networks for real-time, power-constrained systems. However, their adoption is limited by two main challenges: the accuracy gap compared to large-scale networks during training, and discrepancies between simulated and fabricated systems that further degrade accuracy. While previous work has proposed end-to-end optimizations for specific datasets (e.g., MNIST) and optical systems, these approaches typically lack generalization across tasks and hardware designs. To address these limitations, we propose a task-agnostic and hardware-agnostic pipeline that supports image classification and segmentation across diverse optical systems. To assist optical system design before training, we estimate achievable model accuracy based on user-specified constraints such as physical size and the dataset. For training, we introduce Neural Tangent Knowledge Distillation (NTKD), which aligns optical models with electronic teacher networks, thereby narrowing the accuracy gap. After fabrication, NTKD also guides fine-tuning of the digital backend to compensate for implementation errors. Experiments on multiple datasets (e.g., MNIST, CIFAR, Carvana Masking) and hardware configurations show that our pipeline consistently improves ONN performance and enables practical deployment in both pre-fabrication simulations and physical implementations.
SAVVY: Spatial Awareness via Audio-Visual LLMs through Seeing and Hearing
Jun 04, 20253D spatial reasoning in dynamic, audio-visual environments is a cornerstone of human cognition yet remains largely unexplored by existing Audio-Visual Large Language Models (AV-LLMs) and benchmarks, which predominantly focus on static or 2D scenes. We introduce SAVVY-Bench, the first benchmark for 3D spatial reasoning in dynamic scenes with synchronized spatial audio. SAVVY-Bench is comprised of thousands of relationships involving static and moving objects, and requires fine-grained temporal grounding, consistent 3D localization, and multi-modal annotation. To tackle this challenge, we propose SAVVY, a novel training-free reasoning pipeline that consists of two stages: (i) Egocentric Spatial Tracks Estimation, which leverages AV-LLMs as well as other audio-visual methods to track the trajectories of key objects related to the query using both visual and spatial audio cues, and (ii) Dynamic Global Map Construction, which aggregates multi-modal queried object trajectories and converts them into a unified global dynamic map. Using the constructed map, a final QA answer is obtained through a coordinate transformation that aligns the global map with the queried viewpoint. Empirical evaluation demonstrates that SAVVY substantially enhances performance of state-of-the-art AV-LLMs, setting a new standard and stage for approaching dynamic 3D spatial reasoning in AV-LLMs.
Transferable polychromatic optical encoder for neural networks
Nov 05, 2024Artificial neural networks (ANNs) have fundamentally transformed the field of computer vision, providing unprecedented performance. However, these ANNs for image processing demand substantial computational resources, often hindering real-time operation. In this paper, we demonstrate an optical encoder that can perform convolution simultaneously in three color channels during the image capture, effectively implementing several initial convolutional layers of a ANN. Such an optical encoding results in ~24,000 times reduction in computational operations, with a state-of-the art classification accuracy (~73.2%) in free-space optical system. In addition, our analog optical encoder, trained for CIFAR-10 data, can be transferred to the ImageNet subset, High-10, without any modifications, and still exhibits moderate accuracy. Our results evidence the potential of hybrid optical/digital computer vision system in which the optical frontend can pre-process an ambient scene to reduce the energy and latency of the whole computer vision system.
TKIL: Tangent Kernel Approach for Class Balanced Incremental Learning
Jun 17, 2022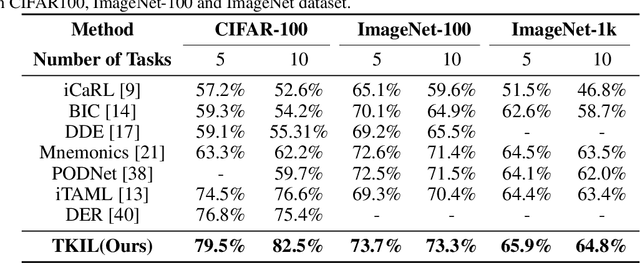
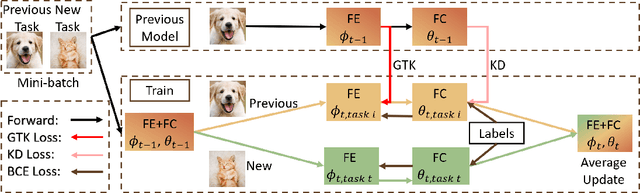


When learning new tasks in a sequential manner, deep neural networks tend to forget tasks that they previously learned, a phenomenon called catastrophic forgetting. Class incremental learning methods aim to address this problem by keeping a memory of a few exemplars from previously learned tasks, and distilling knowledge from them. However, existing methods struggle to balance the performance across classes since they typically overfit the model to the latest task. In our work, we propose to address these challenges with the introduction of a novel methodology of Tangent Kernel for Incremental Learning (TKIL) that achieves class-balanced performance. The approach preserves the representations across classes and balances the accuracy for each class, and as such achieves better overall accuracy and variance. TKIL approach is based on Neural Tangent Kernel (NTK), which describes the convergence behavior of neural networks as a kernel function in the limit of infinite width. In TKIL, the gradients between feature layers are treated as the distance between the representations of these layers and can be defined as Gradients Tangent Kernel loss (GTK loss) such that it is minimized along with averaging weights. This allows TKIL to automatically identify the task and to quickly adapt to it during inference. Experiments on CIFAR-100 and ImageNet datasets with various incremental learning settings show that these strategies allow TKIL to outperform existing state-of-the-art methods.
Incremental Learning Meets Transfer Learning: Application to Multi-site Prostate MRI Segmentation
Jun 03, 2022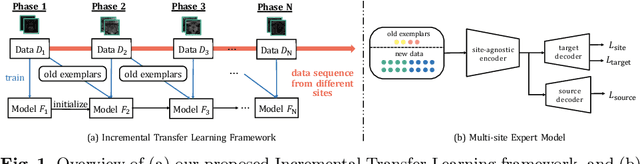

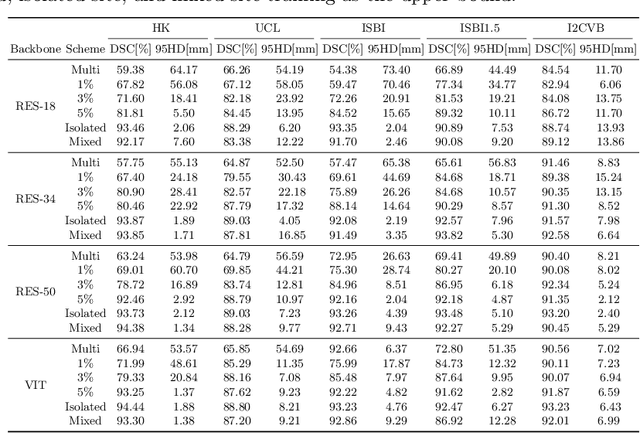
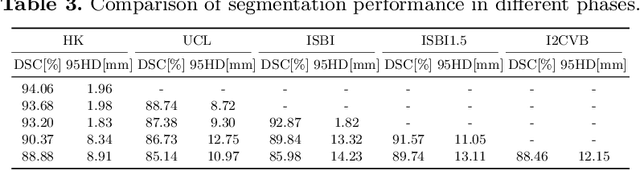
Many medical datasets have recently been created for medical image segmentation tasks, and it is natural to question whether we can use them to sequentially train a single model that (1) performs better on all these datasets, and (2) generalizes well and transfers better to the unknown target site domain. Prior works have achieved this goal by jointly training one model on multi-site datasets, which achieve competitive performance on average but such methods rely on the assumption about the availability of all training data, thus limiting its effectiveness in practical deployment. In this paper, we propose a novel multi-site segmentation framework called incremental-transfer learning (ITL), which learns a model from multi-site datasets in an end-to-end sequential fashion. Specifically, "incremental" refers to training sequentially constructed datasets, and "transfer" is achieved by leveraging useful information from the linear combination of embedding features on each dataset. In addition, we introduce our ITL framework, where we train the network including a site-agnostic encoder with pre-trained weights and at most two segmentation decoder heads. We also design a novel site-level incremental loss in order to generalize well on the target domain. Second, we show for the first time that leveraging our ITL training scheme is able to alleviate challenging catastrophic forgetting problems in incremental learning. We conduct experiments using five challenging benchmark datasets to validate the effectiveness of our incremental-transfer learning approach. Our approach makes minimal assumptions on computation resources and domain-specific expertise, and hence constitutes a strong starting point in multi-site medical image segmentation.
Knowledge Distillation Circumvents Nonlinearity for Optical Convolutional Neural Networks
Feb 26, 2021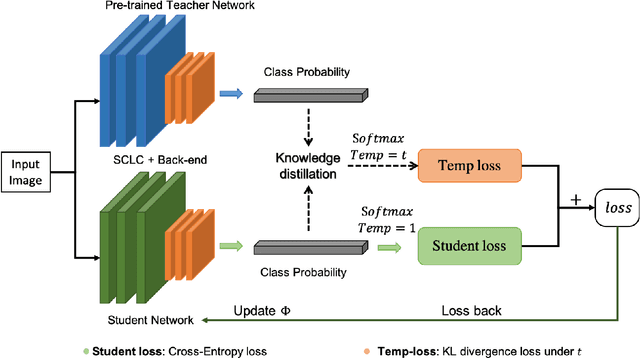
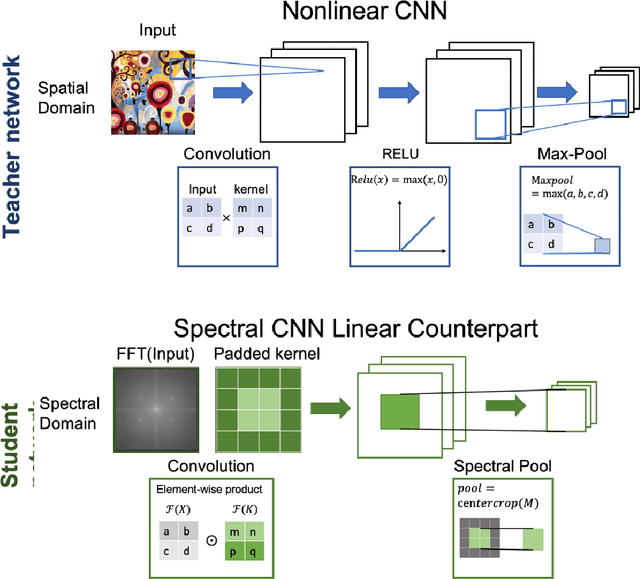
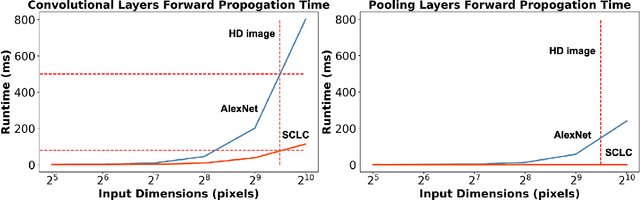
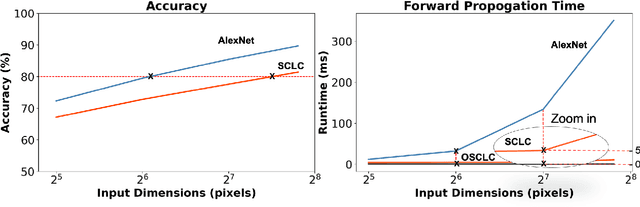
In recent years, Convolutional Neural Networks (CNNs) have enabled ubiquitous image processing applications. As such, CNNs require fast runtime (forward propagation) to process high-resolution visual streams in real time. This is still a challenging task even with state-of-the-art graphics and tensor processing units. The bottleneck in computational efficiency primarily occurs in the convolutional layers. Performing operations in the Fourier domain is a promising way to accelerate forward propagation since it transforms convolutions into elementwise multiplications, which are considerably faster to compute for large kernels. Furthermore, such computation could be implemented using an optical 4f system with orders of magnitude faster operation. However, a major challenge in using this spectral approach, as well as in an optical implementation of CNNs, is the inclusion of a nonlinearity between each convolutional layer, without which CNN performance drops dramatically. Here, we propose a Spectral CNN Linear Counterpart (SCLC) network architecture and develop a Knowledge Distillation (KD) approach to circumvent the need for a nonlinearity and successfully train such networks. While the KD approach is known in machine learning as an effective process for network pruning, we adapt the approach to transfer the knowledge from a nonlinear network (teacher) to a linear counterpart (student). We show that the KD approach can achieve performance that easily surpasses the standard linear version of a CNN and could approach the performance of the nonlinear network. Our simulations show that the possibility of increasing the resolution of the input image allows our proposed 4f optical linear network to perform more efficiently than a nonlinear network with the same accuracy on two fundamental image processing tasks: (i) object classification and (ii) semantic segmentation.
BI-MAML: Balanced Incremental Approach for Meta Learning
Jun 12, 2020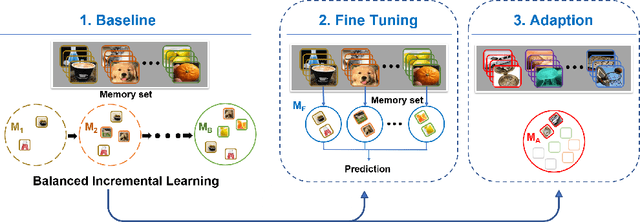



We present a novel Balanced Incremental Model Agnostic Meta Learning system (BI-MAML) for learning multiple tasks. Our method implements a meta-update rule to incrementally adapt its model to new tasks without forgetting old tasks. Such a capability is not possible in current state-of-the-art MAML approaches. These methods effectively adapt to new tasks, however, suffer from 'catastrophic forgetting' phenomena, in which new tasks that are streamed into the model degrade the performance of the model on previously learned tasks. Our system performs the meta-updates with only a few-shots and can successfully accomplish them. Our key idea for achieving this is the design of balanced learning strategy for the baseline model. The strategy sets the baseline model to perform equally well on various tasks and incorporates time efficiency. The balanced learning strategy enables BI-MAML to both outperform other state-of-the-art models in terms of classification accuracy for existing tasks and also accomplish efficient adaption to similar new tasks with less required shots. We evaluate BI-MAML by conducting comparisons on two common benchmark datasets with multiple number of image classification tasks. BI-MAML performance demonstrates advantages in both accuracy and efficiency.