 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInception-inspired LSTM for Next-frame Video Prediction
Paper and Code
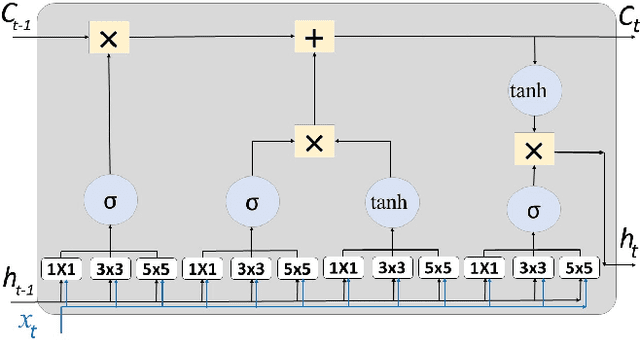
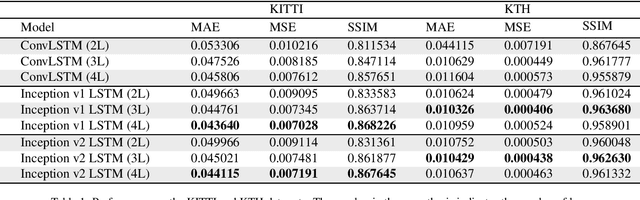
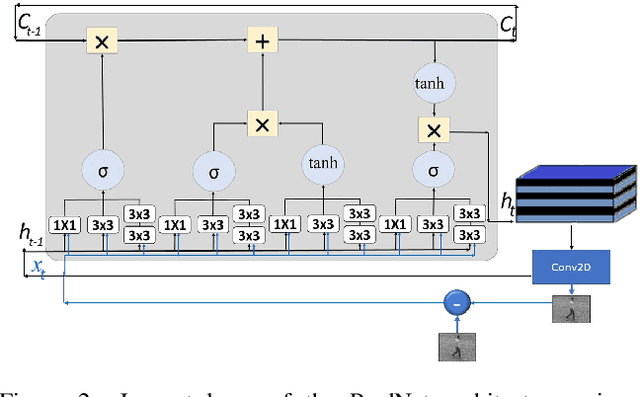

The problem of video frame prediction has received much interest due to its relevance to many computer vision applications such as autonomous vehicles or robotics. Supervised methods for video frame prediction rely on labeled data, which may not always be available. In this paper, we provide a novel unsupervised deep-learning method called Inception-based LSTM for video frame prediction. The general idea of inception networks is to implement wider networks instead of deeper networks. This network design was shown to improve the performance of image classification. The proposed method is evaluated on both Inception-v1 and Inception-v2 structures. The proposed Inception LSTM methods are compared with convolutional LSTM when applied using PredNet predictive coding framework for both the KITTI and KTH data sets. We observed that the Inception based LSTM outperforms the convolutional LSTM. Also, Inception LSTM has better prediction performance compared to Inception v2 LSTM. However, Inception v2 LSTM has a lower computational cost compared to Inception LSTM.