 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing ResNet Image Classification Performance by using Parameterized Hypercomplex Multiplication
Jan 11, 2023Recently, many deep networks have introduced hypercomplex and related calculations into their architectures. In regard to convolutional networks for classification, these enhancements have been applied to the convolution operations in the frontend to enhance accuracy and/or reduce the parameter requirements while maintaining accuracy. Although these enhancements have been applied to the convolutional frontend, it has not been studied whether adding hypercomplex calculations improves performance when applied to the densely connected backend. This paper studies ResNet architectures and incorporates parameterized hypercomplex multiplication (PHM) into the backend of residual, quaternion, and vectormap convolutional neural networks to assess the effect. We show that PHM does improve classification accuracy performance on several image datasets, including small, low-resolution CIFAR 10/100 and large high-resolution ImageNet and ASL, and can achieve state-of-the-art accuracy for hypercomplex networks.
Deep Axial Hypercomplex Networks
Jan 11, 2023



Over the past decade, deep hypercomplex-inspired networks have enhanced feature extraction for image classification by enabling weight sharing across input channels. Recent works make it possible to improve representational capabilities by using hypercomplex-inspired networks which consume high computational costs. This paper reduces this cost by factorizing a quaternion 2D convolutional module into two consecutive vectormap 1D convolutional modules. Also, we use 5D parameterized hypercomplex multiplication based fully connected layers. Incorporating both yields our proposed hypercomplex network, a novel architecture that can be assembled to construct deep axial-hypercomplex networks (DANs) for image classifications. We conduct experiments on CIFAR benchmarks, SVHN, and Tiny ImageNet datasets and achieve better performance with fewer trainable parameters and FLOPS. Our proposed model achieves almost 2% higher performance for CIFAR and SVHN datasets, and more than 3% for the ImageNet-Tiny dataset and takes six times fewer parameters than the real-valued ResNets. Also, it shows state-of-the-art performance on CIFAR benchmarks in hypercomplex space.
Deep Residual Axial Networks
Jan 11, 2023



While residual networks (ResNets) demonstrate outstanding performance on computer vision tasks, their computational cost still remains high. Here, we focus on reducing this cost by proposing a new network architecture, axial ResNet, which replaces spatial 2D convolution operations with two consecutive 1D convolution operations. Convergence of very deep axial ResNets has faced degradation problems which prevent the networks from performing efficiently. To mitigate this, we apply a residual connection to each 1D convolutional operation and propose our final novel architecture namely residual axial networks (RANs). Extensive benchmark evaluation shows that RANs outperform with about 49% fewer parameters than ResNets on CIFAR benchmarks, SVHN, and Tiny ImageNet image classification datasets. Moreover, our proposed RANs show significant improvement in validation performance in comparison to the wide ResNets on CIFAR benchmarks and the deep recursive residual networks on image super-resolution dataset.
Adding Quaternion Representations to Attention Networks for Classification
Oct 04, 2021
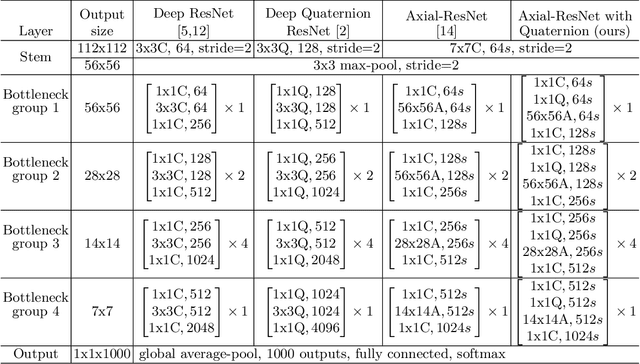
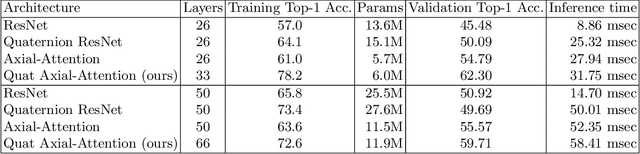

This paper introduces a novel modification to axial-attention networks to improve their image classification accuracy. The modification involves supplementing axial-attention modules with quaternion input representations to improve image classification accuracy. We chose axial-attention networks because they factor 2D attention operations into two consecutive 1D operations (similar to separable convolution) and are thus less resource intensive than non-axial attention networks. We chose a quaternion encoder because of they share weights across four real-valued input channels and the weight-sharing has been shown to produce a more interlinked/interwoven output representation. We hypothesize that an attention module can be more effective using these interlinked representations as input. Our experiments support this hypothesis as reflected in the improved classification accuracy compared to standard axial-attention networks. We think this happens because the attention modules have better input representations to work with.