 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdding Quaternion Representations to Attention Networks for Classification
Paper and Code

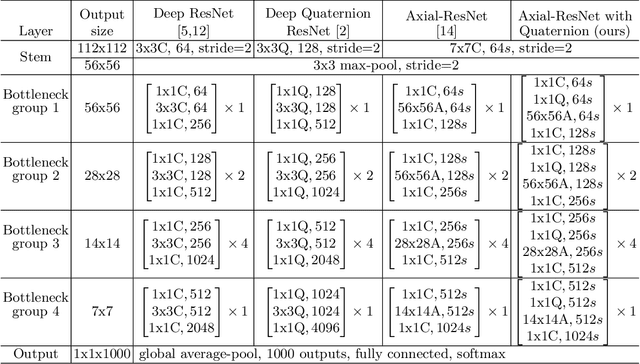
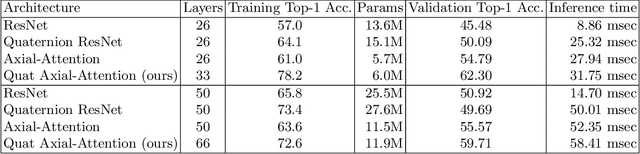

This paper introduces a novel modification to axial-attention networks to improve their image classification accuracy. The modification involves supplementing axial-attention modules with quaternion input representations to improve image classification accuracy. We chose axial-attention networks because they factor 2D attention operations into two consecutive 1D operations (similar to separable convolution) and are thus less resource intensive than non-axial attention networks. We chose a quaternion encoder because of they share weights across four real-valued input channels and the weight-sharing has been shown to produce a more interlinked/interwoven output representation. We hypothesize that an attention module can be more effective using these interlinked representations as input. Our experiments support this hypothesis as reflected in the improved classification accuracy compared to standard axial-attention networks. We think this happens because the attention modules have better input representations to work with.