 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA specialized face-processing network consistent with the representational geometry of monkey face patches
Oct 30, 2016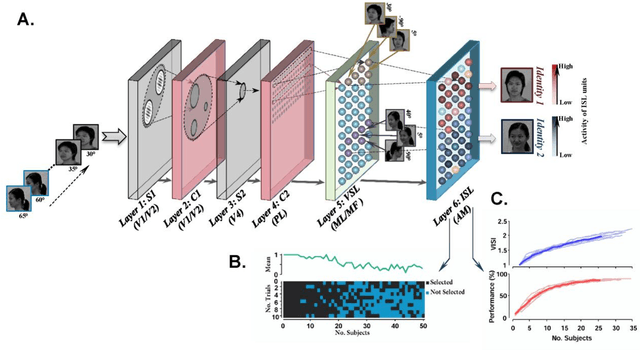
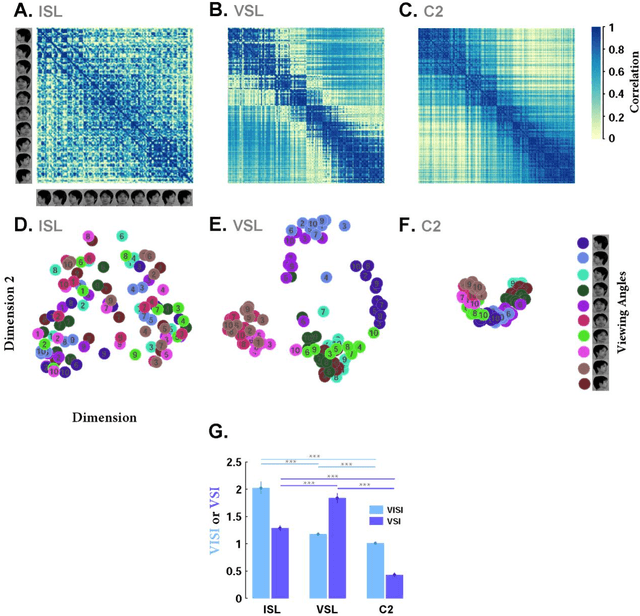
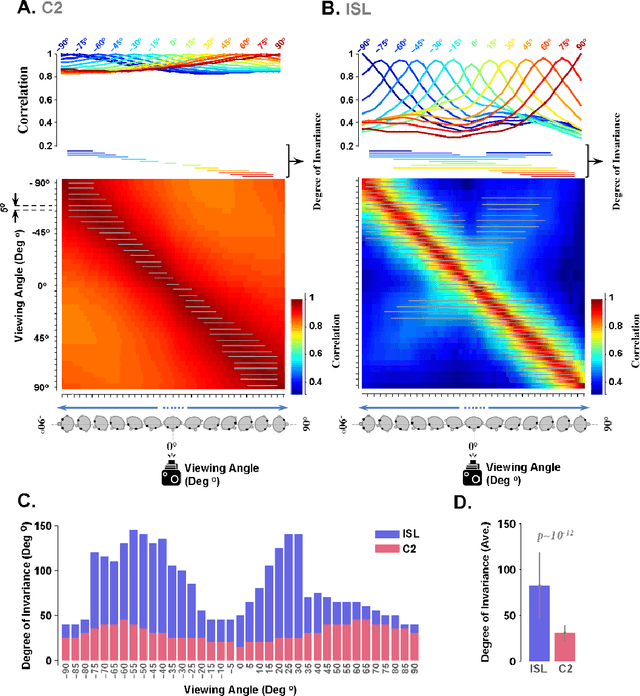
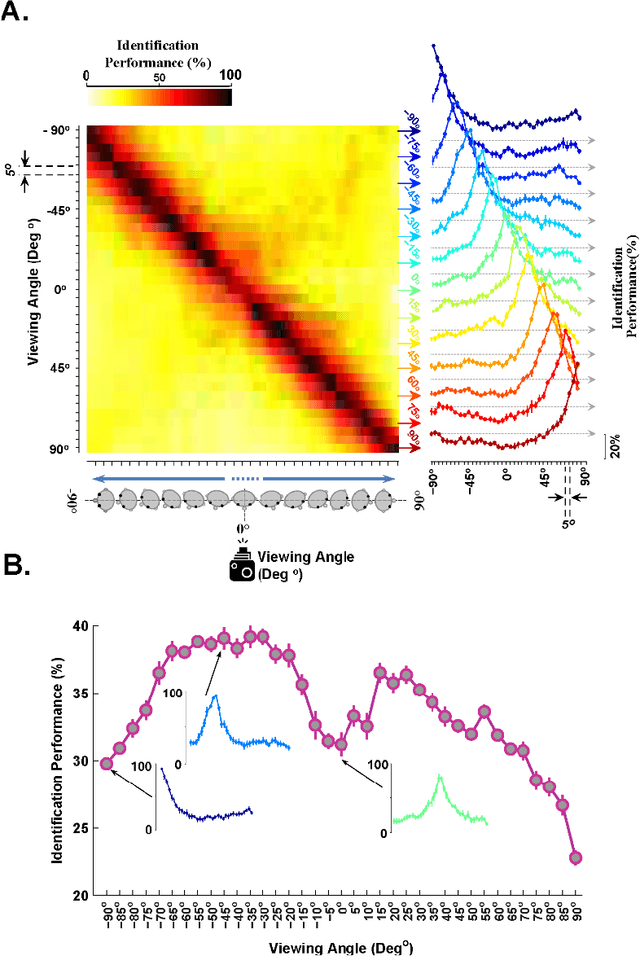
Ample evidence suggests that face processing in human and non-human primates is performed differently compared with other objects. Converging reports, both physiologically and psychophysically, indicate that faces are processed in specialized neural networks in the brain -i.e. face patches in monkeys and the fusiform face area (FFA) in humans. We are all expert face-processing agents, and able to identify very subtle differences within the category of faces, despite substantial visual and featural similarities. Identification is performed rapidly and accurately after viewing a whole face, while significantly drops if some of the face configurations (e.g. inversion, misalignment) are manipulated or if partial views of faces are shown due to occlusion. This refers to a hotly-debated, yet highly-supported concept, known as holistic face processing. We built a hierarchical computational model of face-processing based on evidence from recent neuronal and behavioural studies on faces processing in primates. Representational geometries of the last three layers of the model have characteristics similar to those observed in monkey face patches (posterior, middle and anterior patches). Furthermore, several face-processing-related phenomena reported in the literature automatically emerge as properties of this model. The representations are evolved through several computational layers, using biologically plausible learning rules. The model satisfies face inversion effect, composite face effect, other race effect, view and identity selectivity, and canonical face views. To our knowledge, no models have so far been proposed with this performance and agreement with biological data.
What you need to know about the state-of-the-art computational models of object-vision: A tour through the models
Jul 10, 2014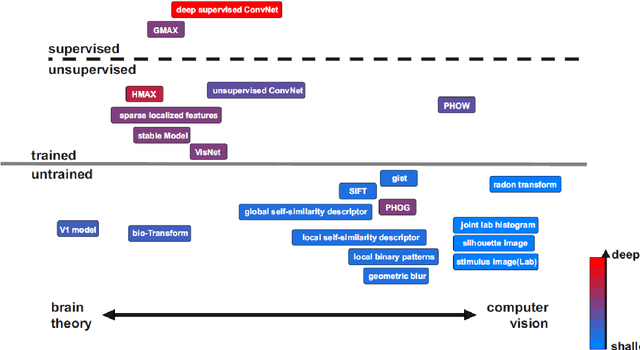



Models of object vision have been of great interest in computer vision and visual neuroscience. During the last decades, several models have been developed to extract visual features from images for object recognition tasks. Some of these were inspired by the hierarchical structure of primate visual system, and some others were engineered models. The models are varied in several aspects: models that are trained by supervision, models trained without supervision, and models (e.g. feature extractors) that are fully hard-wired and do not need training. Some of the models come with a deep hierarchical structure consisting of several layers, and some others are shallow and come with only one or two layers of processing. More recently, new models have been developed that are not hand-tuned but trained using millions of images, through which they learn how to extract informative task-related features. Here I will survey all these different models and provide the reader with an intuitive, as well as a more detailed, understanding of the underlying computations in each of the models.