 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat you need to know about the state-of-the-art computational models of object-vision: A tour through the models
Paper and Code
Jul 10, 2014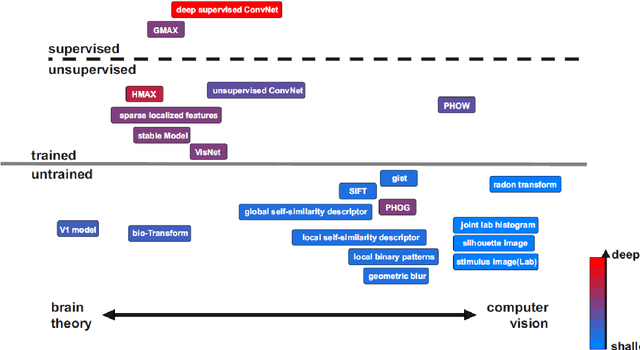



Models of object vision have been of great interest in computer vision and visual neuroscience. During the last decades, several models have been developed to extract visual features from images for object recognition tasks. Some of these were inspired by the hierarchical structure of primate visual system, and some others were engineered models. The models are varied in several aspects: models that are trained by supervision, models trained without supervision, and models (e.g. feature extractors) that are fully hard-wired and do not need training. Some of the models come with a deep hierarchical structure consisting of several layers, and some others are shallow and come with only one or two layers of processing. More recently, new models have been developed that are not hand-tuned but trained using millions of images, through which they learn how to extract informative task-related features. Here I will survey all these different models and provide the reader with an intuitive, as well as a more detailed, understanding of the underlying computations in each of the models.