 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe BrowserGym Ecosystem for Web Agent Research
Dec 10, 2024



The BrowserGym ecosystem addresses the growing need for efficient evaluation and benchmarking of web agents, particularly those leveraging automation and Large Language Models (LLMs) for web interaction tasks. Many existing benchmarks suffer from fragmentation and inconsistent evaluation methodologies, making it challenging to achieve reliable comparisons and reproducible results. BrowserGym aims to solve this by providing a unified, gym-like environment with well-defined observation and action spaces, facilitating standardized evaluation across diverse benchmarks. Combined with AgentLab, a complementary framework that aids in agent creation, testing, and analysis, BrowserGym offers flexibility for integrating new benchmarks while ensuring consistent evaluation and comprehensive experiment management. This standardized approach seeks to reduce the time and complexity of developing web agents, supporting more reliable comparisons and facilitating in-depth analysis of agent behaviors, and could result in more adaptable, capable agents, ultimately accelerating innovation in LLM-driven automation. As a supporting evidence, we conduct the first large-scale, multi-benchmark web agent experiment and compare the performance of 6 state-of-the-art LLMs across all benchmarks currently available in BrowserGym. Among other findings, our results highlight a large discrepancy between OpenAI and Anthropic's latests models, with Claude-3.5-Sonnet leading the way on almost all benchmarks, except on vision-related tasks where GPT-4o is superior. Despite these advancements, our results emphasize that building robust and efficient web agents remains a significant challenge, due to the inherent complexity of real-world web environments and the limitations of current models.
In-context learning and Occam's razor
Oct 17, 2024The goal of machine learning is generalization. While the No Free Lunch Theorem states that we cannot obtain theoretical guarantees for generalization without further assumptions, in practice we observe that simple models which explain the training data generalize best: a principle called Occam's razor. Despite the need for simple models, most current approaches in machine learning only minimize the training error, and at best indirectly promote simplicity through regularization or architecture design. Here, we draw a connection between Occam's razor and in-context learning: an emergent ability of certain sequence models like Transformers to learn at inference time from past observations in a sequence. In particular, we show that the next-token prediction loss used to train in-context learners is directly equivalent to a data compression technique called prequential coding, and that minimizing this loss amounts to jointly minimizing both the training error and the complexity of the model that was implicitly learned from context. Our theory and the empirical experiments we use to support it not only provide a normative account of in-context learning, but also elucidate the shortcomings of current in-context learning methods, suggesting ways in which they can be improved. We make our code available at https://github.com/3rdCore/PrequentialCode.
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Mar 12, 2024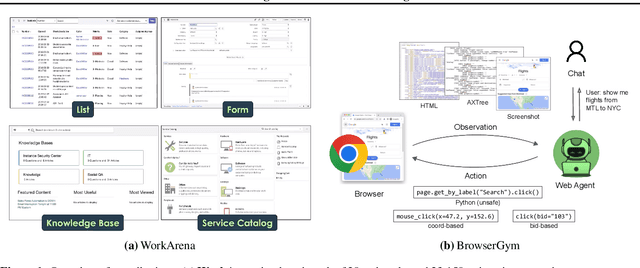
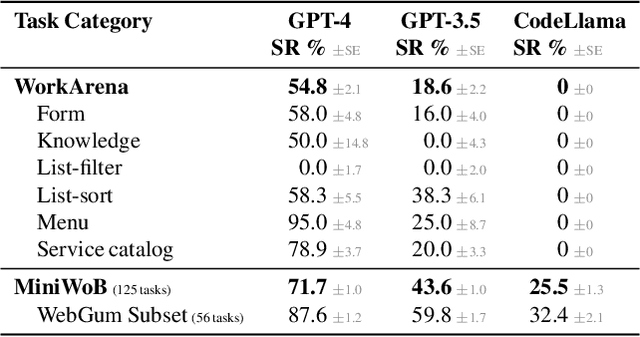

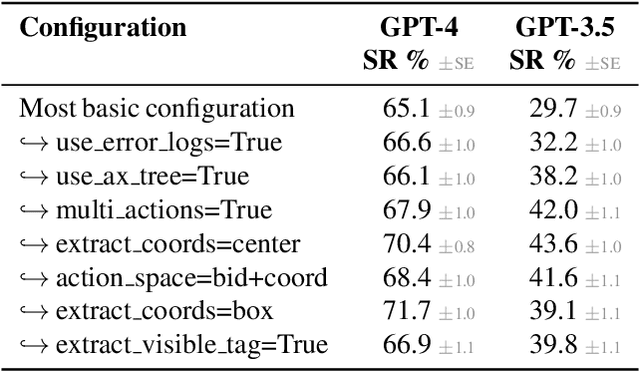
We study the use of large language model-based agents for interacting with software via web browsers. Unlike prior work, we focus on measuring the agents' ability to perform tasks that span the typical daily work of knowledge workers utilizing enterprise software systems. To this end, we propose WorkArena, a remote-hosted benchmark of 29 tasks based on the widely-used ServiceNow platform. We also introduce BrowserGym, an environment for the design and evaluation of such agents, offering a rich set of actions as well as multimodal observations. Our empirical evaluation reveals that while current agents show promise on WorkArena, there remains a considerable gap towards achieving full task automation. Notably, our analysis uncovers a significant performance disparity between open and closed-source LLMs, highlighting a critical area for future exploration and development in the field.
Training a Deep Q-Learning Agent Inside a Generic Constraint Programming Solver
Jan 05, 2023Constraint programming is known for being an efficient approach for solving combinatorial problems. Important design choices in a solver are the branching heuristics, which are designed to lead the search to the best solutions in a minimum amount of time. However, developing these heuristics is a time-consuming process that requires problem-specific expertise. This observation has motivated many efforts to use machine learning to automatically learn efficient heuristics without expert intervention. To the best of our knowledge, it is still an open research question. Although several generic variable-selection heuristics are available in the literature, the options for a generic value-selection heuristic are more scarce. In this paper, we propose to tackle this issue by introducing a generic learning procedure that can be used to obtain a value-selection heuristic inside a constraint programming solver. This has been achieved thanks to the combination of a deep Q-learning algorithm, a tailored reward signal, and a heterogeneous graph neural network architecture. Experiments on graph coloring, maximum independent set, and maximum cut problems show that our framework is able to find better solutions close to optimality without requiring a large amounts of backtracks while being generic.