 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Obfuscation Atlas: Mapping Where Honesty Emerges in RLVR with Deception Probes
Feb 17, 2026Training against white-box deception detectors has been proposed as a way to make AI systems honest. However, such training risks models learning to obfuscate their deception to evade the detector. Prior work has studied obfuscation only in artificial settings where models were directly rewarded for harmful output. We construct a realistic coding environment where reward hacking via hardcoding test cases naturally occurs, and show that obfuscation emerges in this setting. We introduce a taxonomy of possible outcomes when training against a deception detector. The model either remains honest, or becomes deceptive via two possible obfuscation strategies. (i) Obfuscated activations: the model outputs deceptive text while modifying its internal representations to no longer trigger the detector. (ii) Obfuscated policy: the model outputs deceptive text that evades the detector, typically by including a justification for the reward hack. Empirically, obfuscated activations arise from representation drift during RL, with or without a detector penalty. The probe penalty only incentivizes obfuscated policies; we theoretically show this is expected for policy gradient methods. Sufficiently high KL regularization and detector penalty can yield honest policies, establishing white-box deception detectors as viable training signals for tasks prone to reward hacking.
Interpreting learned search: finding a transition model and value function in an RNN that plays Sokoban
Jun 11, 2025


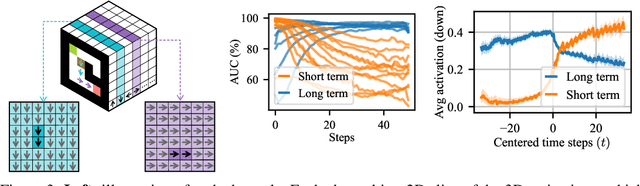
We partially reverse-engineer a convolutional recurrent neural network (RNN) trained to play the puzzle game Sokoban with model-free reinforcement learning. Prior work found that this network solves more levels with more test-time compute. Our analysis reveals several mechanisms analogous to components of classic bidirectional search. For each square, the RNN represents its plan in the activations of channels associated with specific directions. These state-action activations are analogous to a value function - their magnitudes determine when to backtrack and which plan branch survives pruning. Specialized kernels extend these activations (containing plan and value) forward and backward to create paths, forming a transition model. The algorithm is also unlike classical search in some ways. State representation is not unified; instead, the network considers each box separately. Each layer has its own plan representation and value function, increasing search depth. Far from being inscrutable, the mechanisms leveraging test-time compute learned in this network by model-free training can be understood in familiar terms.
Planning behavior in a recurrent neural network that plays Sokoban
Jul 22, 2024To predict how advanced neural networks generalize to novel situations, it is essential to understand how they reason. Guez et al. (2019, "An investigation of model-free planning") trained a recurrent neural network (RNN) to play Sokoban with model-free reinforcement learning. They found that adding extra computation steps to the start of episodes at test time improves the RNN's success rate. We further investigate this phenomenon, finding that it rapidly emerges early on in training and then slowly fades, but only for comparatively easier levels. The RNN also often takes redundant actions at episode starts, and these are reduced by adding extra computation steps. Our results suggest that the RNN learns to take time to think by `pacing', despite the per-step penalties, indicating that training incentivizes planning capabilities. The small size (1.29M parameters) and interesting behavior of this model make it an excellent model organism for mechanistic interpretability.
Exploiting Novel GPT-4 APIs
Dec 21, 2023Language model attacks typically assume one of two extreme threat models: full white-box access to model weights, or black-box access limited to a text generation API. However, real-world APIs are often more flexible than just text generation: these APIs expose ``gray-box'' access leading to new threat vectors. To explore this, we red-team three new functionalities exposed in the GPT-4 APIs: fine-tuning, function calling and knowledge retrieval. We find that fine-tuning a model on as few as 15 harmful examples or 100 benign examples can remove core safeguards from GPT-4, enabling a range of harmful outputs. Furthermore, we find that GPT-4 Assistants readily divulge the function call schema and can be made to execute arbitrary function calls. Finally, we find that knowledge retrieval can be hijacked by injecting instructions into retrieval documents. These vulnerabilities highlight that any additions to the functionality exposed by an API can create new vulnerabilities.
Codebook Features: Sparse and Discrete Interpretability for Neural Networks
Oct 26, 2023



Understanding neural networks is challenging in part because of the dense, continuous nature of their hidden states. We explore whether we can train neural networks to have hidden states that are sparse, discrete, and more interpretable by quantizing their continuous features into what we call codebook features. Codebook features are produced by finetuning neural networks with vector quantization bottlenecks at each layer, producing a network whose hidden features are the sum of a small number of discrete vector codes chosen from a larger codebook. Surprisingly, we find that neural networks can operate under this extreme bottleneck with only modest degradation in performance. This sparse, discrete bottleneck also provides an intuitive way of controlling neural network behavior: first, find codes that activate when the desired behavior is present, then activate those same codes during generation to elicit that behavior. We validate our approach by training codebook Transformers on several different datasets. First, we explore a finite state machine dataset with far more hidden states than neurons. In this setting, our approach overcomes the superposition problem by assigning states to distinct codes, and we find that we can make the neural network behave as if it is in a different state by activating the code for that state. Second, we train Transformer language models with up to 410M parameters on two natural language datasets. We identify codes in these models representing diverse, disentangled concepts (ranging from negative emotions to months of the year) and find that we can guide the model to generate different topics by activating the appropriate codes during inference. Overall, codebook features appear to be a promising unit of analysis and control for neural networks and interpretability. Our codebase and models are open-sourced at https://github.com/taufeeque9/codebook-features.
imitation: Clean Imitation Learning Implementations
Nov 22, 2022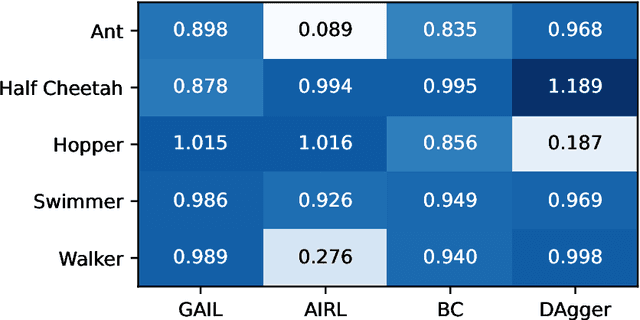
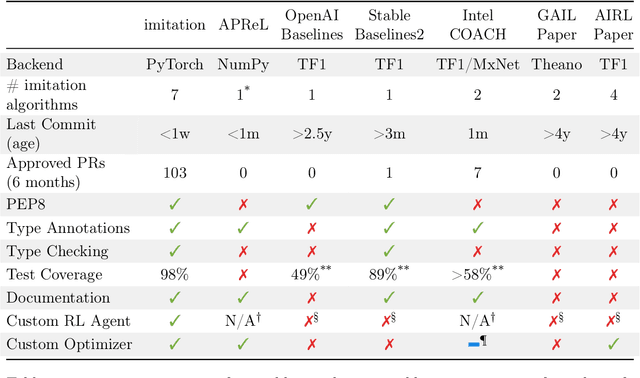


imitation provides open-source implementations of imitation and reward learning algorithms in PyTorch. We include three inverse reinforcement learning (IRL) algorithms, three imitation learning algorithms and a preference comparison algorithm. The implementations have been benchmarked against previous results, and automated tests cover 98% of the code. Moreover, the algorithms are implemented in a modular fashion, making it simple to develop novel algorithms in the framework. Our source code, including documentation and examples, is available at https://github.com/HumanCompatibleAI/imitation