 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACORD: An Expert-Annotated Retrieval Dataset for Legal Contract Drafting
Jan 11, 2025Information retrieval, specifically contract clause retrieval, is foundational to contract drafting because lawyers rarely draft contracts from scratch; instead, they locate and revise the most relevant precedent. We introduce the Atticus Clause Retrieval Dataset (ACORD), the first retrieval benchmark for contract drafting fully annotated by experts. ACORD focuses on complex contract clauses such as Limitation of Liability, Indemnification, Change of Control, and Most Favored Nation. It includes 114 queries and over 126,000 query-clause pairs, each ranked on a scale from 1 to 5 stars. The task is to find the most relevant precedent clauses to a query. The bi-encoder retriever paired with pointwise LLMs re-rankers shows promising results. However, substantial improvements are still needed to effectively manage the complex legal work typically undertaken by lawyers. As the first retrieval benchmark for contract drafting annotated by experts, ACORD can serve as a valuable IR benchmark for the NLP community.
MAUD: An Expert-Annotated Legal NLP Dataset for Merger Agreement Understanding
Jan 06, 2023Reading comprehension of legal text can be a particularly challenging task due to the length and complexity of legal clauses and a shortage of expert-annotated datasets. To address this challenge, we introduce the Merger Agreement Understanding Dataset (MAUD), an expert-annotated reading comprehension dataset based on the American Bar Association's 2021 Public Target Deal Points Study, with over 39,000 examples and over 47,000 total annotations. Our fine-tuned Transformer baselines show promising results, with models performing well above random on most questions. However, on a large subset of questions, there is still room for significant improvement. As the only expert-annotated merger agreement dataset, MAUD is valuable as a benchmark for both the legal profession and the NLP community.
imitation: Clean Imitation Learning Implementations
Nov 22, 2022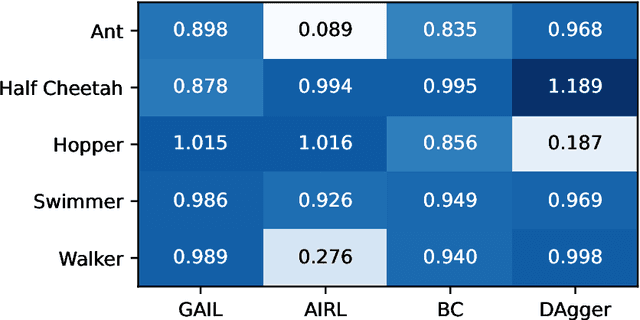
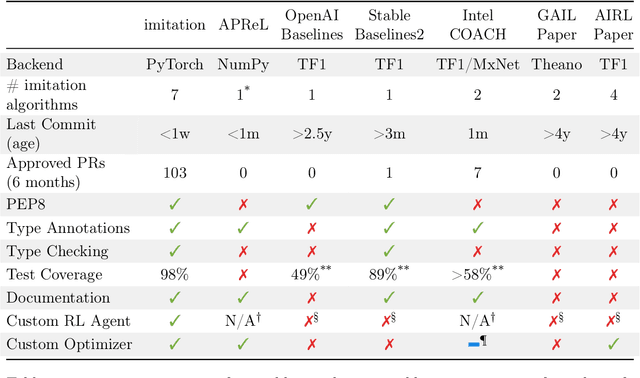


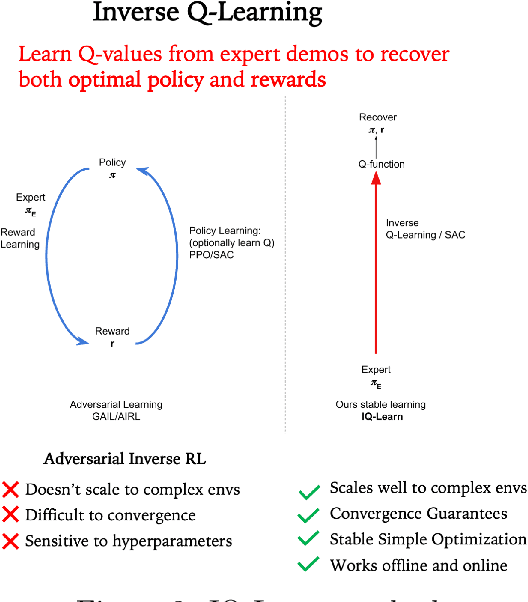
imitation provides open-source implementations of imitation and reward learning algorithms in PyTorch. We include three inverse reinforcement learning (IRL) algorithms, three imitation learning algorithms and a preference comparison algorithm. The implementations have been benchmarked against previous results, and automated tests cover 98% of the code. Moreover, the algorithms are implemented in a modular fashion, making it simple to develop novel algorithms in the framework. Our source code, including documentation and examples, is available at https://github.com/HumanCompatibleAI/imitation
Retrospective on the 2021 BASALT Competition on Learning from Human Feedback
Apr 14, 2022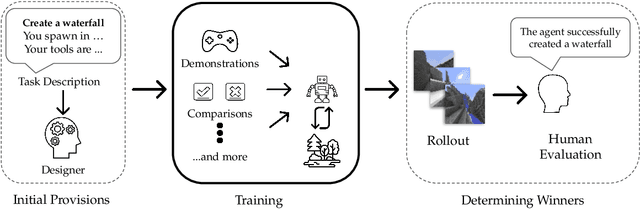
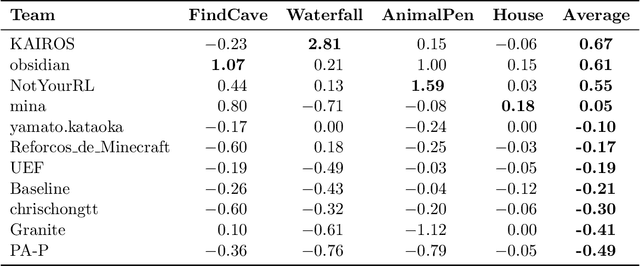
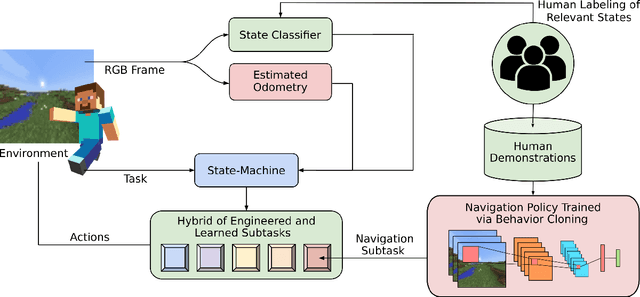
We held the first-ever MineRL Benchmark for Agents that Solve Almost-Lifelike Tasks (MineRL BASALT) Competition at the Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2021). The goal of the competition was to promote research towards agents that use learning from human feedback (LfHF) techniques to solve open-world tasks. Rather than mandating the use of LfHF techniques, we described four tasks in natural language to be accomplished in the video game Minecraft, and allowed participants to use any approach they wanted to build agents that could accomplish the tasks. Teams developed a diverse range of LfHF algorithms across a variety of possible human feedback types. The three winning teams implemented significantly different approaches while achieving similar performance. Interestingly, their approaches performed well on different tasks, validating our choice of tasks to include in the competition. While the outcomes validated the design of our competition, we did not get as many participants and submissions as our sister competition, MineRL Diamond. We speculate about the causes of this problem and suggest improvements for future iterations of the competition.
The MineRL BASALT Competition on Learning from Human Feedback
Jul 05, 2021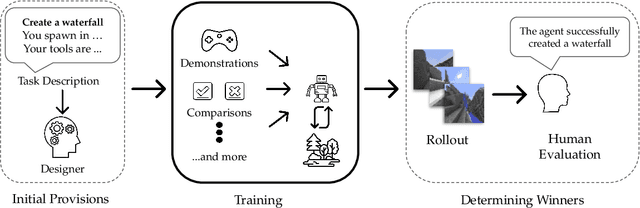

The last decade has seen a significant increase of interest in deep learning research, with many public successes that have demonstrated its potential. As such, these systems are now being incorporated into commercial products. With this comes an additional challenge: how can we build AI systems that solve tasks where there is not a crisp, well-defined specification? While multiple solutions have been proposed, in this competition we focus on one in particular: learning from human feedback. Rather than training AI systems using a predefined reward function or using a labeled dataset with a predefined set of categories, we instead train the AI system using a learning signal derived from some form of human feedback, which can evolve over time as the understanding of the task changes, or as the capabilities of the AI system improve. The MineRL BASALT competition aims to spur forward research on this important class of techniques. We design a suite of four tasks in Minecraft for which we expect it will be hard to write down hardcoded reward functions. These tasks are defined by a paragraph of natural language: for example, "create a waterfall and take a scenic picture of it", with additional clarifying details. Participants must train a separate agent for each task, using any method they want. Agents are then evaluated by humans who have read the task description. To help participants get started, we provide a dataset of human demonstrations on each of the four tasks, as well as an imitation learning baseline that leverages these demonstrations. Our hope is that this competition will improve our ability to build AI systems that do what their designers intend them to do, even when the intent cannot be easily formalized. Besides allowing AI to solve more tasks, this can also enable more effective regulation of AI systems, as well as making progress on the value alignment problem.