 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphARC: A Comprehensive Benchmark for Graph-Based Abstract Reasoning
May 29, 2026Relational reasoning lies at the heart of intelligence, but existing benchmarks are typically confined to formats such as grids or text. We introduce GraphARC, a benchmark for abstract reasoning on graph-structured data. GraphARC generalizes the few-shot transformation learning paradigm of the Abstraction and Reasoning Corpus (ARC). Each task requires inferring a transformation rule from a few input-output pairs and applying it to a new test graph, covering local, global, and hierarchical graph transformations. Unlike grid-based ARC, GraphARC instances can be generated at scale across diverse graph families and sizes, enabling systematic evaluation of generalization abilities. We evaluate state-of-the-art language models on GraphARC and observe clear limitations. Models can answer questions about graph properties but often fail to solve the full graph transformation task, revealing a comprehension-execution gap. Performance further degrades on larger instances, exposing scaling barriers. More broadly, by combining aspects of node classification, link prediction, and graph generation within a single framework, GraphARC provides a promising testbed for future graph foundation models.
An Imperfect Verifier is Good Enough: Learning with Noisy Rewards
Apr 09, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become a prominent method for post-training Large Language Models (LLMs). However, verifiers are rarely error-free; even deterministic checks can be inaccurate, and the growing dependence on model-based judges exacerbates the issue. The extent to which RLVR is robust to such noise and the verifier accuracy required for effective training remain unresolved questions. We investigate these questions in the domains of code generation and scientific reasoning by introducing noise into RL training. Noise rates up to 15% yield peak validation accuracy within 2 percentage points of the clean baseline. These findings are consistent across controlled and model-based noise types, three model families (Qwen3, GLM4, Llama 3.1), and model sizes from 4B to 9B. Overall, the results indicate that imperfect verification does not constitute a fundamental barrier to RLVR. Furthermore, our findings suggest that practitioners should prioritize moderate accuracy with high precision over perfect verification.
BitLogic: Training Framework for Gradient-Based FPGA-Native Neural Networks
Feb 07, 2026The energy and latency costs of deep neural network inference are increasingly driven by deployment rather than training, motivating hardware-specialized alternatives to arithmetic-heavy models. Field-Programmable Gate Arrays (FPGAs) provide an attractive substrate for such specialization, yet existing FPGA-based neural approaches are fragmented and difficult to compare. We present BitLogic, a fully gradient-based, end-to-end trainable framework for FPGA-native neural networks built around Lookup Table (LUT) computation. BitLogic replaces multiply-accumulate operations with differentiable LUT nodes that map directly to FPGA primitives, enabling native binary computation, sparse connectivity, and efficient hardware realization. The framework offers a modular functional API supporting diverse architectures, along with learned encoders, hardware-aware heads, and multiple boundary-consistent LUT relaxations. An automated Register Transfer Level (RTL) export pipeline translates trained PyTorch models into synthesizable HDL, ensuring equivalence between software and hardware inference. Experiments across standard vision benchmarks and heterogeneous hardware platforms demonstrate competitive accuracy and substantial gains in FPGA efficiency, including 72.3% test accuracy on CIFAR-10 achieved with fewer than 0.3M logic gates, while attaining sub-20 ns single-sample inference using only LUT resources.
GIC-DLC: Differentiable Logic Circuits for Hardware-Friendly Grayscale Image Compression
Jan 20, 2026Neural image codecs achieve higher compression ratios than traditional hand-crafted methods such as PNG or JPEG-XL, but often incur substantial computational overhead, limiting their deployment on energy-constrained devices such as smartphones, cameras, and drones. We propose Grayscale Image Compression with Differentiable Logic Circuits (GIC-DLC), a hardware-aware codec where we train lookup tables to combine the flexibility of neural networks with the efficiency of Boolean operations. Experiments on grayscale benchmark datasets show that GIC-DLC outperforms traditional codecs in compression efficiency while allowing substantial reductions in energy consumption and latency. These results demonstrate that learned compression can be hardware-friendly, offering a promising direction for low-power image compression on edge devices.
Recurrent Deep Differentiable Logic Gate Networks
Aug 08, 2025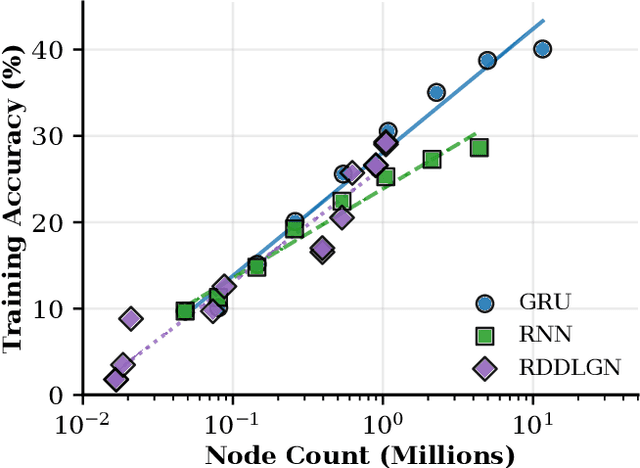
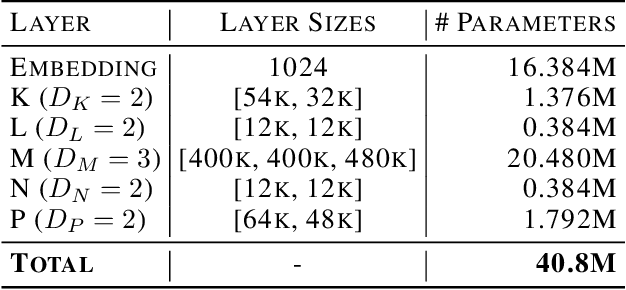
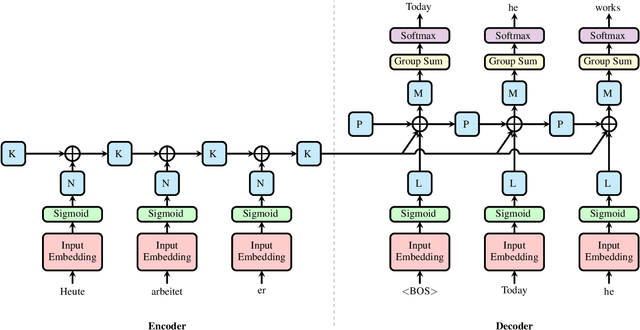
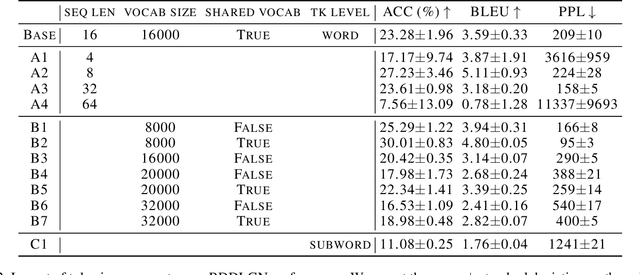
While differentiable logic gates have shown promise in feedforward networks, their application to sequential modeling remains unexplored. This paper presents the first implementation of Recurrent Deep Differentiable Logic Gate Networks (RDDLGN), combining Boolean operations with recurrent architectures for sequence-to-sequence learning. Evaluated on WMT'14 English-German translation, RDDLGN achieves 5.00 BLEU and 30.9\% accuracy during training, approaching GRU performance (5.41 BLEU) and graceful degradation (4.39 BLEU) during inference. This work establishes recurrent logic-based neural computation as viable, opening research directions for FPGA acceleration in sequential modeling and other recursive network architectures.
Keep It Real: Challenges in Attacking Compression-Based Adversarial Purification
Aug 07, 2025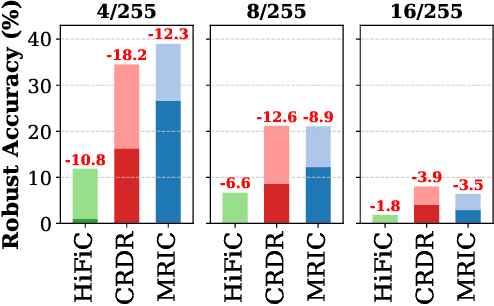
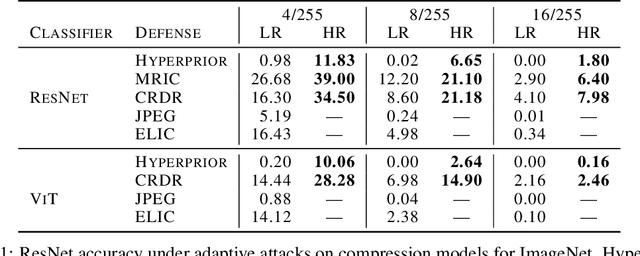
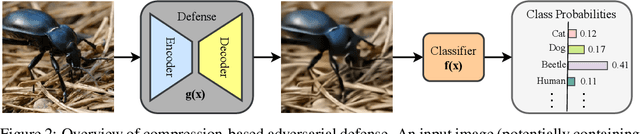
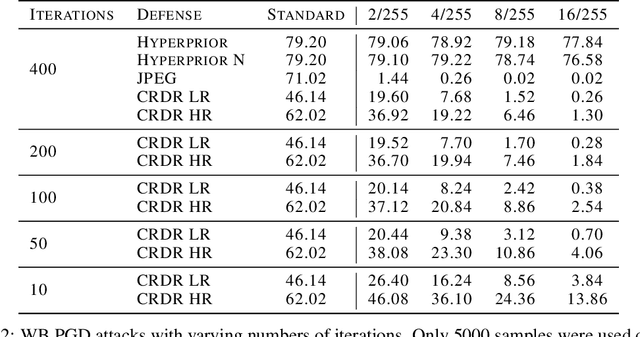
Previous work has suggested that preprocessing images through lossy compression can defend against adversarial perturbations, but comprehensive attack evaluations have been lacking. In this paper, we construct strong white-box and adaptive attacks against various compression models and identify a critical challenge for attackers: high realism in reconstructed images significantly increases attack difficulty. Through rigorous evaluation across multiple attack scenarios, we demonstrate that compression models capable of producing realistic, high-fidelity reconstructions are substantially more resistant to our attacks. In contrast, low-realism compression models can be broken. Our analysis reveals that this is not due to gradient masking. Rather, realistic reconstructions maintaining distributional alignment with natural images seem to offer inherent robustness. This work highlights a significant obstacle for future adversarial attacks and suggests that developing more effective techniques to overcome realism represents an essential challenge for comprehensive security evaluation.
Mind the Gap: Removing the Discretization Gap in Differentiable Logic Gate Networks
Jun 09, 2025Modern neural networks demonstrate state-of-the-art performance on numerous existing benchmarks; however, their high computational requirements and energy consumption prompt researchers to seek more efficient solutions for real-world deployment. Logic gate networks (LGNs) learns a large network of logic gates for efficient image classification. However, learning a network that can solve a simple problem like CIFAR-10 can take days to weeks to train. Even then, almost half of the network remains unused, causing a discretization gap. This discretization gap hinders real-world deployment of LGNs, as the performance drop between training and inference negatively impacts accuracy. We inject Gumbel noise with a straight-through estimator during training to significantly speed up training, improve neuron utilization, and decrease the discretization gap. We theoretically show that this results from implicit Hessian regularization, which improves the convergence properties of LGNs. We train networks $4.5 \times$ faster in wall-clock time, reduce the discretization gap by $98\%$, and reduce the number of unused gates by $100\%$.
Synthetic Data for Blood Vessel Network Extraction
Apr 16, 2025Blood vessel networks in the brain play a crucial role in stroke research, where understanding their topology is essential for analyzing blood flow dynamics. However, extracting detailed topological vessel network information from microscopy data remains a significant challenge, mainly due to the scarcity of labeled training data and the need for high topological accuracy. This work combines synthetic data generation with deep learning to automatically extract vessel networks as graphs from volumetric microscopy data. To combat data scarcity, we introduce a comprehensive pipeline for generating large-scale synthetic datasets that mirror the characteristics of real vessel networks. Our three-stage approach progresses from abstract graph generation through vessel mask creation to realistic medical image synthesis, incorporating biological constraints and imaging artifacts at each stage. Using this synthetic data, we develop a two-stage deep learning pipeline of 3D U-Net-based models for node detection and edge prediction. Fine-tuning on real microscopy data shows promising adaptation, improving edge prediction F1 scores from 0.496 to 0.626 by training on merely 5 manually labeled samples. These results suggest that automated vessel network extraction is becoming practically feasible, opening new possibilities for large-scale vascular analysis in stroke research.
Human Aligned Compression for Robust Models
Apr 16, 2025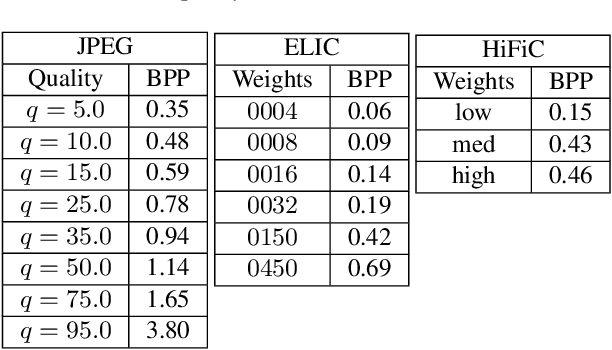

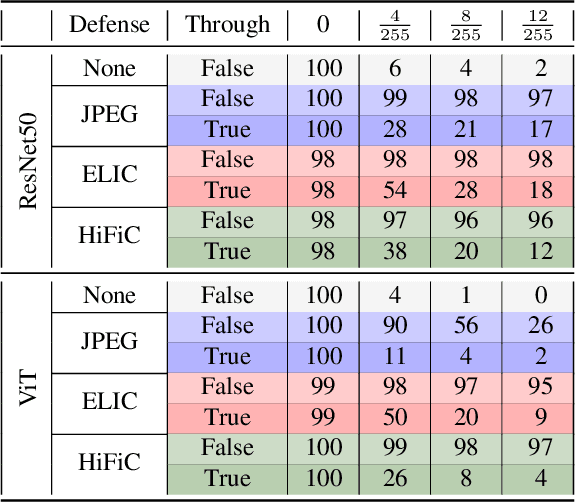
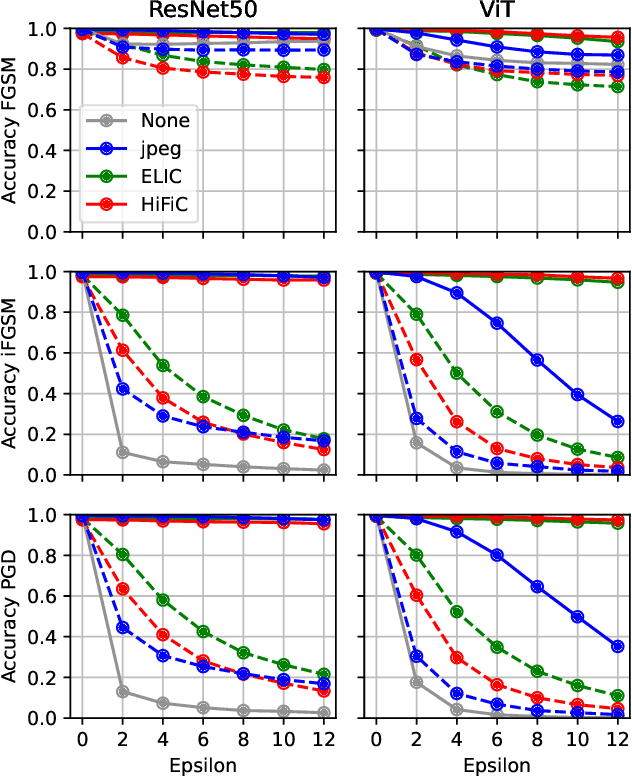
Adversarial attacks on image models threaten system robustness by introducing imperceptible perturbations that cause incorrect predictions. We investigate human-aligned learned lossy compression as a defense mechanism, comparing two learned models (HiFiC and ELIC) against traditional JPEG across various quality levels. Our experiments on ImageNet subsets demonstrate that learned compression methods outperform JPEG, particularly for Vision Transformer architectures, by preserving semantically meaningful content while removing adversarial noise. Even in white-box settings where attackers can access the defense, these methods maintain substantial effectiveness. We also show that sequential compression--applying rounds of compression/decompression--significantly enhances defense efficacy while maintaining classification performance. Our findings reveal that human-aligned compression provides an effective, computationally efficient defense that protects the image features most relevant to human and machine understanding. It offers a practical approach to improving model robustness against adversarial threats.
FLIP Reasoning Challenge
Apr 16, 2025Over the past years, advances in artificial intelligence (AI) have demonstrated how AI can solve many perception and generation tasks, such as image classification and text writing, yet reasoning remains a challenge. This paper introduces the FLIP dataset, a benchmark for evaluating AI reasoning capabilities based on human verification tasks on the Idena blockchain. FLIP challenges present users with two orderings of 4 images, requiring them to identify the logically coherent one. By emphasizing sequential reasoning, visual storytelling, and common sense, FLIP provides a unique testbed for multimodal AI systems. Our experiments evaluate state-of-the-art models, leveraging both vision-language models (VLMs) and large language models (LLMs). Results reveal that even the best open-sourced and closed-sourced models achieve maximum accuracies of 75.5% and 77.9%, respectively, in zero-shot settings, compared to human performance of 95.3%. Captioning models aid reasoning models by providing text descriptions of images, yielding better results than when using the raw images directly, 69.6% vs. 75.2% for Gemini 1.5 Pro. Combining the predictions from 15 models in an ensemble increases the accuracy to 85.2%. These findings highlight the limitations of existing reasoning models and the need for robust multimodal benchmarks like FLIP. The full codebase and dataset will be available at https://github.com/aplesner/FLIP-Reasoning-Challenge.