 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIC-DLC: Differentiable Logic Circuits for Hardware-Friendly Grayscale Image Compression
Jan 20, 2026Neural image codecs achieve higher compression ratios than traditional hand-crafted methods such as PNG or JPEG-XL, but often incur substantial computational overhead, limiting their deployment on energy-constrained devices such as smartphones, cameras, and drones. We propose Grayscale Image Compression with Differentiable Logic Circuits (GIC-DLC), a hardware-aware codec where we train lookup tables to combine the flexibility of neural networks with the efficiency of Boolean operations. Experiments on grayscale benchmark datasets show that GIC-DLC outperforms traditional codecs in compression efficiency while allowing substantial reductions in energy consumption and latency. These results demonstrate that learned compression can be hardware-friendly, offering a promising direction for low-power image compression on edge devices.
Virtual Fashion Photo-Shoots: Building a Large-Scale Garment-Lookbook Dataset
Oct 01, 2025Fashion image generation has so far focused on narrow tasks such as virtual try-on, where garments appear in clean studio environments. In contrast, editorial fashion presents garments through dynamic poses, diverse locations, and carefully crafted visual narratives. We introduce the task of virtual fashion photo-shoot, which seeks to capture this richness by transforming standardized garment images into contextually grounded editorial imagery. To enable this new direction, we construct the first large-scale dataset of garment-lookbook pairs, bridging the gap between e-commerce and fashion media. Because such pairs are not readily available, we design an automated retrieval pipeline that aligns garments across domains, combining visual-language reasoning with object-level localization. We construct a dataset with three garment-lookbook pair accuracy levels: high quality (10,000 pairs), medium quality (50,000 pairs), and low quality (300,000 pairs). This dataset offers a foundation for models that move beyond catalog-style generation and toward fashion imagery that reflects creativity, atmosphere, and storytelling.
Recurrent Deep Differentiable Logic Gate Networks
Aug 08, 2025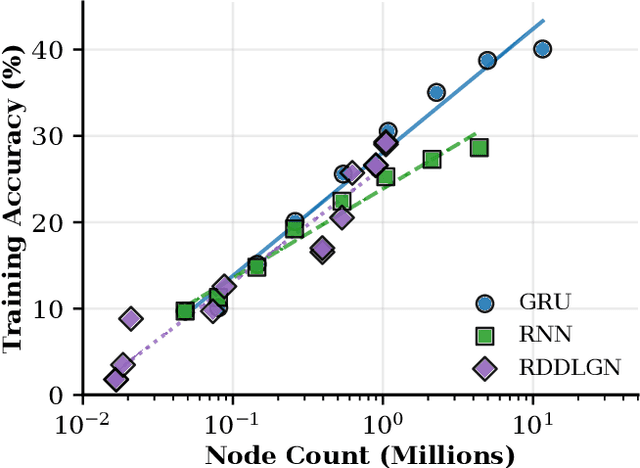
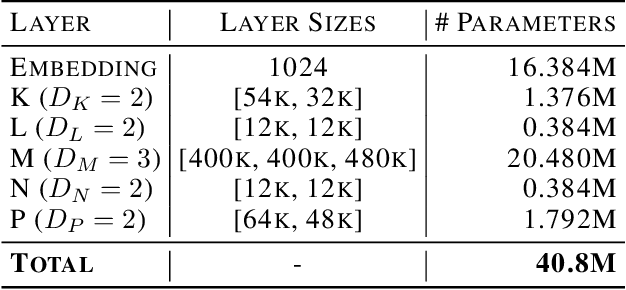
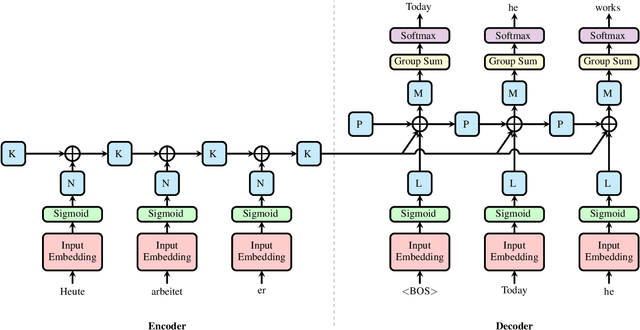
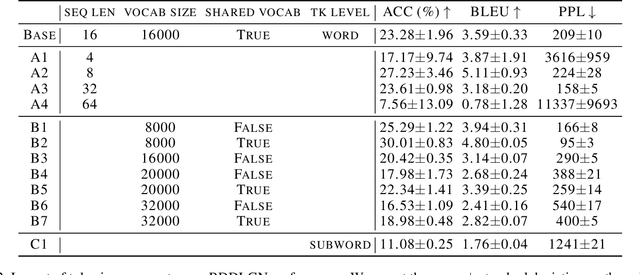
While differentiable logic gates have shown promise in feedforward networks, their application to sequential modeling remains unexplored. This paper presents the first implementation of Recurrent Deep Differentiable Logic Gate Networks (RDDLGN), combining Boolean operations with recurrent architectures for sequence-to-sequence learning. Evaluated on WMT'14 English-German translation, RDDLGN achieves 5.00 BLEU and 30.9\% accuracy during training, approaching GRU performance (5.41 BLEU) and graceful degradation (4.39 BLEU) during inference. This work establishes recurrent logic-based neural computation as viable, opening research directions for FPGA acceleration in sequential modeling and other recursive network architectures.
Keep It Real: Challenges in Attacking Compression-Based Adversarial Purification
Aug 07, 2025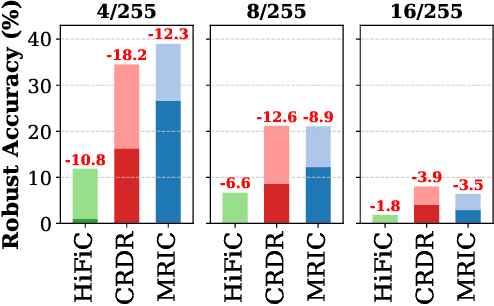
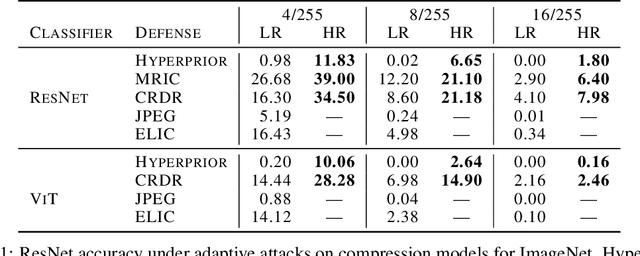
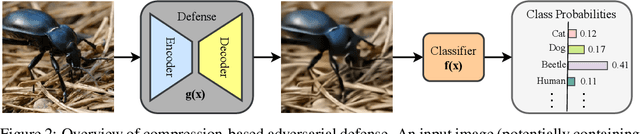
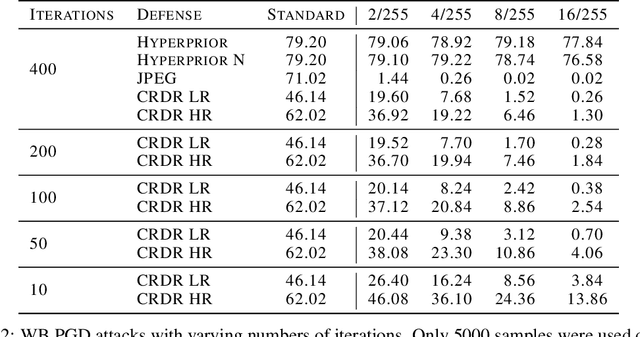
Previous work has suggested that preprocessing images through lossy compression can defend against adversarial perturbations, but comprehensive attack evaluations have been lacking. In this paper, we construct strong white-box and adaptive attacks against various compression models and identify a critical challenge for attackers: high realism in reconstructed images significantly increases attack difficulty. Through rigorous evaluation across multiple attack scenarios, we demonstrate that compression models capable of producing realistic, high-fidelity reconstructions are substantially more resistant to our attacks. In contrast, low-realism compression models can be broken. Our analysis reveals that this is not due to gradient masking. Rather, realistic reconstructions maintaining distributional alignment with natural images seem to offer inherent robustness. This work highlights a significant obstacle for future adversarial attacks and suggests that developing more effective techniques to overcome realism represents an essential challenge for comprehensive security evaluation.
Mind the Gap: Removing the Discretization Gap in Differentiable Logic Gate Networks
Jun 09, 2025Modern neural networks demonstrate state-of-the-art performance on numerous existing benchmarks; however, their high computational requirements and energy consumption prompt researchers to seek more efficient solutions for real-world deployment. Logic gate networks (LGNs) learns a large network of logic gates for efficient image classification. However, learning a network that can solve a simple problem like CIFAR-10 can take days to weeks to train. Even then, almost half of the network remains unused, causing a discretization gap. This discretization gap hinders real-world deployment of LGNs, as the performance drop between training and inference negatively impacts accuracy. We inject Gumbel noise with a straight-through estimator during training to significantly speed up training, improve neuron utilization, and decrease the discretization gap. We theoretically show that this results from implicit Hessian regularization, which improves the convergence properties of LGNs. We train networks $4.5 \times$ faster in wall-clock time, reduce the discretization gap by $98\%$, and reduce the number of unused gates by $100\%$.
Human Aligned Compression for Robust Models
Apr 16, 2025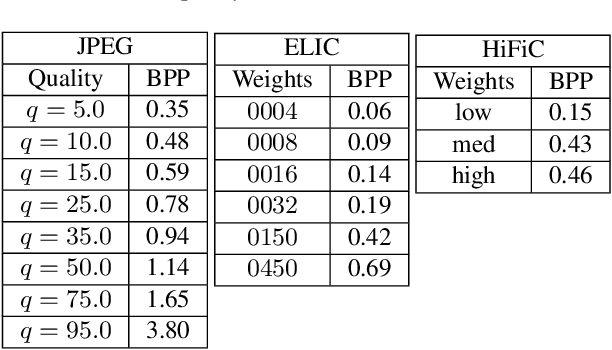

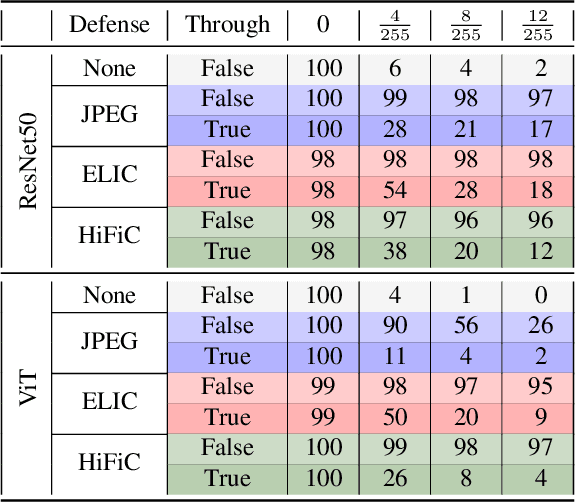
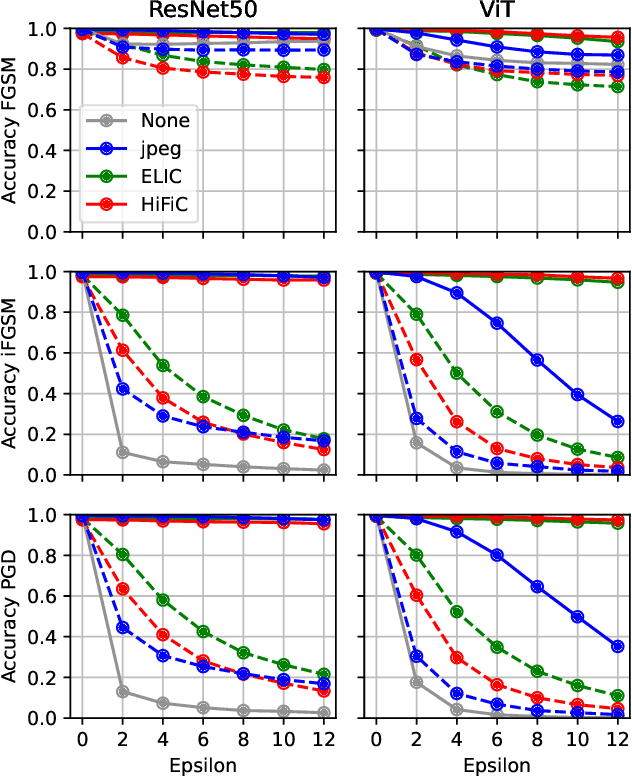
Adversarial attacks on image models threaten system robustness by introducing imperceptible perturbations that cause incorrect predictions. We investigate human-aligned learned lossy compression as a defense mechanism, comparing two learned models (HiFiC and ELIC) against traditional JPEG across various quality levels. Our experiments on ImageNet subsets demonstrate that learned compression methods outperform JPEG, particularly for Vision Transformer architectures, by preserving semantically meaningful content while removing adversarial noise. Even in white-box settings where attackers can access the defense, these methods maintain substantial effectiveness. We also show that sequential compression--applying rounds of compression/decompression--significantly enhances defense efficacy while maintaining classification performance. Our findings reveal that human-aligned compression provides an effective, computationally efficient defense that protects the image features most relevant to human and machine understanding. It offers a practical approach to improving model robustness against adversarial threats.
Conditional Hallucinations for Image Compression
Oct 25, 2024


In lossy image compression, models face the challenge of either hallucinating details or generating out-of-distribution samples due to the information bottleneck. This implies that at times, introducing hallucinations is necessary to generate in-distribution samples. The optimal level of hallucination varies depending on image content, as humans are sensitive to small changes that alter the semantic meaning. We propose a novel compression method that dynamically balances the degree of hallucination based on content. We collect data and train a model to predict user preferences on hallucinations. By using this prediction to adjust the perceptual weight in the reconstruction loss, we develop a Conditionally Hallucinating compression model (ConHa) that outperforms state-of-the-art image compression methods. Code and images are available at https://polybox.ethz.ch/index.php/s/owS1k5JYs4KD4TA.
Bridging Diversity and Uncertainty in Active learning with Self-Supervised Pre-Training
Mar 06, 2024



This study addresses the integration of diversity-based and uncertainty-based sampling strategies in active learning, particularly within the context of self-supervised pre-trained models. We introduce a straightforward heuristic called TCM that mitigates the cold start problem while maintaining strong performance across various data levels. By initially applying TypiClust for diversity sampling and subsequently transitioning to uncertainty sampling with Margin, our approach effectively combines the strengths of both strategies. Our experiments demonstrate that TCM consistently outperforms existing methods across various datasets in both low and high data regimes.
SUPClust: Active Learning at the Boundaries
Mar 06, 2024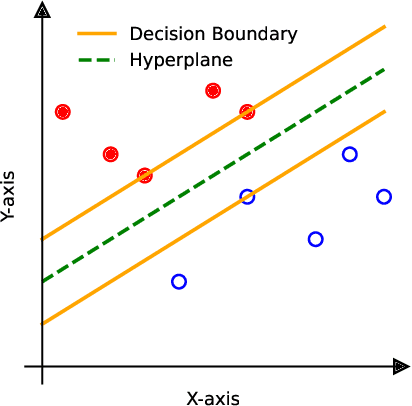

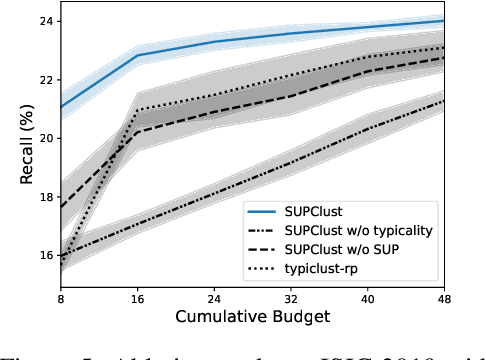
Active learning is a machine learning paradigm designed to optimize model performance in a setting where labeled data is expensive to acquire. In this work, we propose a novel active learning method called SUPClust that seeks to identify points at the decision boundary between classes. By targeting these points, SUPClust aims to gather information that is most informative for refining the model's prediction of complex decision regions. We demonstrate experimentally that labeling these points leads to strong model performance. This improvement is observed even in scenarios characterized by strong class imbalance.