 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Effort and Problem Complexity: A Scaling Analysis in LLMs
Mar 19, 2025Large Language Models (LLMs) have demonstrated remarkable text generation capabilities, and recent advances in training paradigms have led to breakthroughs in their reasoning performance. In this work, we investigate how the reasoning effort of such models scales with problem complexity. We use the infinitely scalable Tents puzzle, which has a known linear-time solution, to analyze this scaling behavior. Our results show that reasoning effort scales with problem size, but only up to a critical problem complexity. Beyond this threshold, the reasoning effort does not continue to increase, and may even decrease. This observation highlights a critical limitation in the logical coherence of current LLMs as problem complexity increases, and underscores the need for strategies to improve reasoning scalability. Furthermore, our results reveal significant performance differences between current state-of-the-art reasoning models when faced with increasingly complex logical puzzles.
Beyond Interpolation: Extrapolative Reasoning with Reinforcement Learning and Graph Neural Networks
Feb 06, 2025



Despite incredible progress, many neural architectures fail to properly generalize beyond their training distribution. As such, learning to reason in a correct and generalizable way is one of the current fundamental challenges in machine learning. In this respect, logic puzzles provide a great testbed, as we can fully understand and control the learning environment. Thus, they allow to evaluate performance on previously unseen, larger and more difficult puzzles that follow the same underlying rules. Since traditional approaches often struggle to represent such scalable logical structures, we propose to model these puzzles using a graph-based approach. Then, we investigate the key factors enabling the proposed models to learn generalizable solutions in a reinforcement learning setting. Our study focuses on the impact of the inductive bias of the architecture, different reward systems and the role of recurrent modeling in enabling sequential reasoning. Through extensive experiments, we demonstrate how these elements contribute to successful extrapolation on increasingly complex puzzles.These insights and frameworks offer a systematic way to design learning-based systems capable of generalizable reasoning beyond interpolation.
PUZZLES: A Benchmark for Neural Algorithmic Reasoning
Jun 29, 2024



Algorithmic reasoning is a fundamental cognitive ability that plays a pivotal role in problem-solving and decision-making processes. Reinforcement Learning (RL) has demonstrated remarkable proficiency in tasks such as motor control, handling perceptual input, and managing stochastic environments. These advancements have been enabled in part by the availability of benchmarks. In this work we introduce PUZZLES, a benchmark based on Simon Tatham's Portable Puzzle Collection, aimed at fostering progress in algorithmic and logical reasoning in RL. PUZZLES contains 40 diverse logic puzzles of adjustable sizes and varying levels of complexity; many puzzles also feature a diverse set of additional configuration parameters. The 40 puzzles provide detailed information on the strengths and generalization capabilities of RL agents. Furthermore, we evaluate various RL algorithms on PUZZLES, providing baseline comparisons and demonstrating the potential for future research. All the software, including the environment, is available at https://github.com/ETH-DISCO/rlp.
Bridging Diversity and Uncertainty in Active learning with Self-Supervised Pre-Training
Mar 06, 2024



This study addresses the integration of diversity-based and uncertainty-based sampling strategies in active learning, particularly within the context of self-supervised pre-trained models. We introduce a straightforward heuristic called TCM that mitigates the cold start problem while maintaining strong performance across various data levels. By initially applying TypiClust for diversity sampling and subsequently transitioning to uncertainty sampling with Margin, our approach effectively combines the strengths of both strategies. Our experiments demonstrate that TCM consistently outperforms existing methods across various datasets in both low and high data regimes.
SUPClust: Active Learning at the Boundaries
Mar 06, 2024Active learning is a machine learning paradigm designed to optimize model performance in a setting where labeled data is expensive to acquire. In this work, we propose a novel active learning method called SUPClust that seeks to identify points at the decision boundary between classes. By targeting these points, SUPClust aims to gather information that is most informative for refining the model's prediction of complex decision regions. We demonstrate experimentally that labeling these points leads to strong model performance. This improvement is observed even in scenarios characterized by strong class imbalance.
What Determines the Price of NFTs?
Oct 03, 2023



In the evolving landscape of digital art, Non-Fungible Tokens (NFTs) have emerged as a groundbreaking platform, bridging the realms of art and technology. NFTs serve as the foundational framework that has revolutionized the market for digital art, enabling artists to showcase and monetize their creations in unprecedented ways. NFTs combine metadata stored on the blockchain with off-chain data, such as images, to create a novel form of digital ownership. It is not fully understood how these factors come together to determine NFT prices. In this study, we analyze both on-chain and off-chain data of NFT collections trading on OpenSea to understand what influences NFT pricing. Our results show that while text and image data of the NFTs can be used to explain price variations within collections, the extracted features do not generalize to new, unseen collections. Furthermore, we find that an NFT collection's trading volume often relates to its online presence, like social media followers and website traffic.
Visual Abstraction and Reasoning through Language
Mar 07, 2023While Artificial Intelligence (AI) models have achieved human or even superhuman performance in narrowly defined applications, they still struggle to show signs of broader and more flexible intelligence. The Abstraction and Reasoning Corpus (ARC), introduced by Fran\c{c}ois Chollet, aims to assess how close AI systems are to human-like cognitive abilities. Most current approaches rely on carefully handcrafted domain-specific languages (DSLs), which are used to brute-force solutions to the tasks present in ARC. In this work, we propose a general framework for solving ARC based on natural language descriptions of the tasks. While not yet beating state-of-the-art DSL models on ARC, we demonstrate the immense potential of our approach hinted at by the ability to solve previously unsolved tasks.
DAVA: Disentangling Adversarial Variational Autoencoder
Mar 02, 2023



The use of well-disentangled representations offers many advantages for downstream tasks, e.g. an increased sample efficiency, or better interpretability. However, the quality of disentangled interpretations is often highly dependent on the choice of dataset-specific hyperparameters, in particular the regularization strength. To address this issue, we introduce DAVA, a novel training procedure for variational auto-encoders. DAVA completely alleviates the problem of hyperparameter selection. We compare DAVA to models with optimal hyperparameters. Without any hyperparameter tuning, DAVA is competitive on a diverse range of commonly used datasets. Underlying DAVA, we discover a necessary condition for unsupervised disentanglement, which we call PIPE. We demonstrate the ability of PIPE to positively predict the performance of downstream models in abstract reasoning. We also thoroughly investigate correlations with existing supervised and unsupervised metrics. The code is available at https://github.com/besterma/dava.
Robust Disentanglement of a Few Factors at a Time
Oct 26, 2020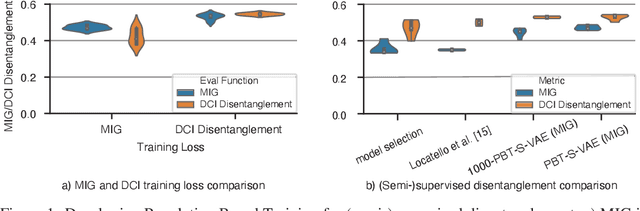

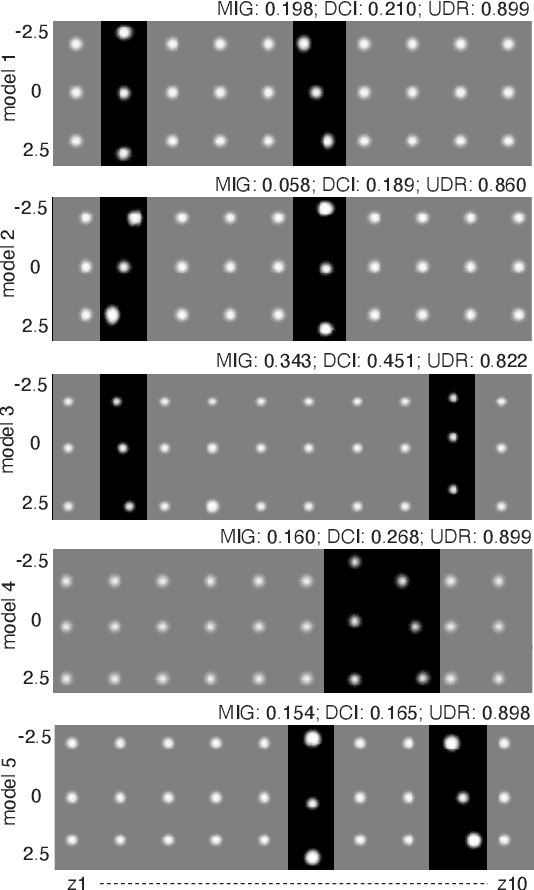

Disentanglement is at the forefront of unsupervised learning, as disentangled representations of data improve generalization, interpretability, and performance in downstream tasks. Current unsupervised approaches remain inapplicable for real-world datasets since they are highly variable in their performance and fail to reach levels of disentanglement of (semi-)supervised approaches. We introduce population-based training (PBT) for improving consistency in training variational autoencoders (VAEs) and demonstrate the validity of this approach in a supervised setting (PBT-VAE). We then use Unsupervised Disentanglement Ranking (UDR) as an unsupervised heuristic to score models in our PBT-VAE training and show how models trained this way tend to consistently disentangle only a subset of the generative factors. Building on top of this observation we introduce the recursive rPU-VAE approach. We train the model until convergence, remove the learned factors from the dataset and reiterate. In doing so, we can label subsets of the dataset with the learned factors and consecutively use these labels to train one model that fully disentangles the whole dataset. With this approach, we show striking improvement in state-of-the-art unsupervised disentanglement performance and robustness across multiple datasets and metrics.