 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACORD: An Expert-Annotated Retrieval Dataset for Legal Contract Drafting
Jan 11, 2025Information retrieval, specifically contract clause retrieval, is foundational to contract drafting because lawyers rarely draft contracts from scratch; instead, they locate and revise the most relevant precedent. We introduce the Atticus Clause Retrieval Dataset (ACORD), the first retrieval benchmark for contract drafting fully annotated by experts. ACORD focuses on complex contract clauses such as Limitation of Liability, Indemnification, Change of Control, and Most Favored Nation. It includes 114 queries and over 126,000 query-clause pairs, each ranked on a scale from 1 to 5 stars. The task is to find the most relevant precedent clauses to a query. The bi-encoder retriever paired with pointwise LLMs re-rankers shows promising results. However, substantial improvements are still needed to effectively manage the complex legal work typically undertaken by lawyers. As the first retrieval benchmark for contract drafting annotated by experts, ACORD can serve as a valuable IR benchmark for the NLP community.
Evaluation of Contrastive Learning with Various Code Representations for Code Clone Detection
Jun 17, 2022



Code clones are pairs of code snippets that implement similar functionality. Clone detection is a fundamental branch of automatic source code comprehension, having many applications in refactoring recommendation, plagiarism detection, and code summarization. A particularly interesting case of clone detection is the detection of semantic clones, i.e., code snippets that have the same functionality but significantly differ in implementation. A promising approach to detecting semantic clones is contrastive learning (CL), a machine learning paradigm popular in computer vision but not yet commonly adopted for code processing. Our work aims to evaluate the most popular CL algorithms combined with three source code representations on two tasks. The first task is code clone detection, which we evaluate on the POJ-104 dataset containing implementations of 104 algorithms. The second task is plagiarism detection. To evaluate the models on this task, we introduce CodeTransformator, a tool for transforming source code. We use it to create a dataset that mimics plagiarised code based on competitive programming solutions. We trained nine models for both tasks and compared them with six existing approaches, including traditional tools and modern pre-trained neural models. The results of our evaluation show that proposed models perform diversely in each task, however the performance of the graph-based models is generally above the others. Among CL algorithms, SimCLR and SwAV lead to better results, while Moco is the most robust approach. Our code and trained models are available at https://doi.org/10.5281/zenodo.6360627, https://doi.org/10.5281/zenodo.5596345.
FastRPB: a Scalable Relative Positional Encoding for Long Sequence Tasks
Feb 23, 2022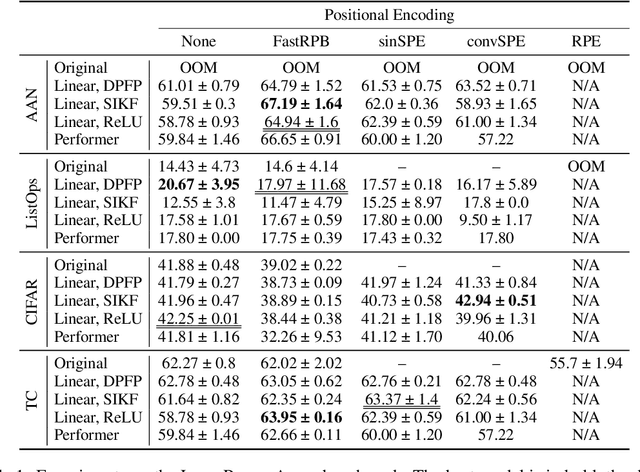


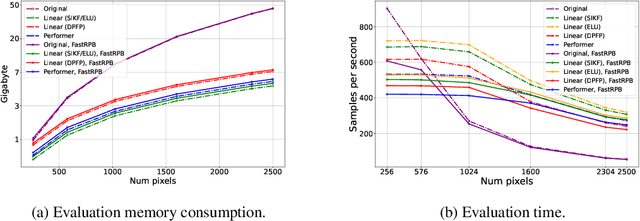
Transformers achieve remarkable performance in various domains, including NLP, CV, audio processing, and graph analysis. However, they do not scale well on long sequence tasks due to their quadratic complexity w.r.t. the inputs length. Linear Transformers were proposed to address this limitation. However, these models have shown weaker performance on the long sequence tasks comparing to the original one. In this paper, we explore Linear Transformer models, rethinking their two core components. Firstly, we improved Linear Transformer with Shift-Invariant Kernel Function SIKF, which achieve higher accuracy without loss in speed. Secondly, we introduce FastRPB which stands for Fast Relative Positional Bias, which efficiently adds positional information to self-attention using Fast Fourier Transformation. FastRPB is independent of the self-attention mechanism and can be combined with an original self-attention and all its efficient variants. FastRPB has O(N log(N)) computational complexity, requiring O(N) memory w.r.t. input sequence length N.